熱門資訊> 正文
谷歌內部揭祕Genie 3:Sora后最強AI爆款,開啟世界模型新時代
2025-08-17 16:40
Genie 3是有史以來最先進的世界模型之一。
僅通過文本,它能夠實時生成完全互動、高度一致的世界。
它不僅是DeepMind積累的結晶,還是通向AGI和具身智能體的關鍵一步。
但Genie 3是如何構建的?未來的世界模型又是什麼樣?
剛剛,谷歌DeepMind的研究科學家Jack Parker-Holder和研究總監Shlomi Fruchter,在a16z的訪談中,分享了他們的觀點。

谷歌DeepMind的研究科學家Jack Parker-Holder和研究總監Shlomi Fruchter
這次對話提供了對Genie 3的第一手洞察。
主持人Justine Moore發推表示:「Genie 3在網絡上引發熱潮」。

主持人Justine Moore發文
他總結了深入探討的要點:
Genie3是由兩個DeepMind項目(Veo 2和Genie 2)合作完成的成果。
實時、互動的世界模型有很多潛在應用。
但應用並不是推動研究的主要動力——它們是從用户使用模型的過程中自然涌現出來的。
Genie 3可以保留最長達一分鍾的空間記憶。
物理規律是模型的「自然產物」,並會隨着訓練數據的規模和深度而不斷提升。
目前還沒有一個「終極模型」能夠同時具備Veo 3和Genie 3的所有能力。
Genie 3:AI新魔法
如果説LLM的原生圖像編輯功能,「動動嘴PS」是「言出法隨」,那Genie 3這次的新特性叫什麼?
只需輸入文本提示,Genie 3即可生成動態世界。用户可以實時進行探索,每秒高達24幀,分辨率為720p。
十多年來,谷歌DeepMind一直致力於模擬環境的研究。
Genie 3是他們最新最強的「世界模型」,是通向通用人工智能(AGI)的關鍵一步,因為它能讓AI智能體在無限豐富的模擬環境中進行訓練。
去年,他們推出了首批基礎世界模型Genie 1和Genie 2,它們能為智能體生成全新的環境。此外,他們還通過Veo 2和Veo 3等視頻生成模型,不斷提升對直觀物理的理解能力。
這些模型在世界模擬的不同能力上都取得了進展。Genie 3是谷歌首個支持實時交互的世界模型,同時提升了一致性和真實感。
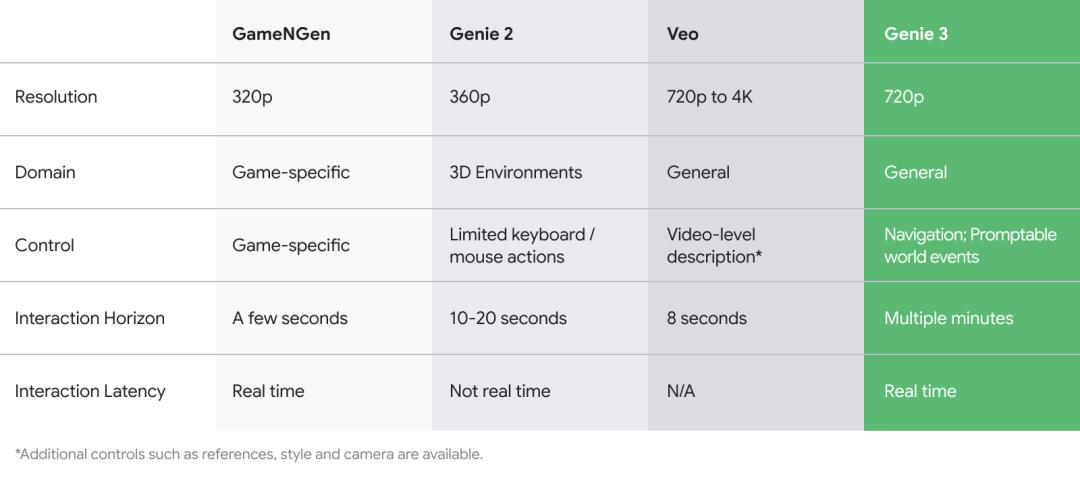
Genie 3在多個方面實現突破
在生成視頻時長、世界一致性、內容的多樣性、特殊記憶等多個方面,Genie 3都實現了突破。
它甚至可以讓個人創造自己的遊戲世界、訓練強化學習的智能體、機器人研究等。
所有這些應用基本上都源於一個核心能力:只用幾句話就能生成一個完整的世界。
最關鍵的新特性是:特殊記憶。
比如:一個角色拿着刷子在牆上刷漆,然后他移動到牆的另一邊去刷,接着又回到原來的位置,結果之前刷的痕跡還在。
特殊記憶(special memory)是DeepMind團隊有意設計的目標,但最終的效果好得出乎意料。
即便是參與Genie 3的內部成員,第一次看到上面刷牆的示例時也不敢相信,需要再三觀看、逐幀檢查,才確定這真的是模型生成的。
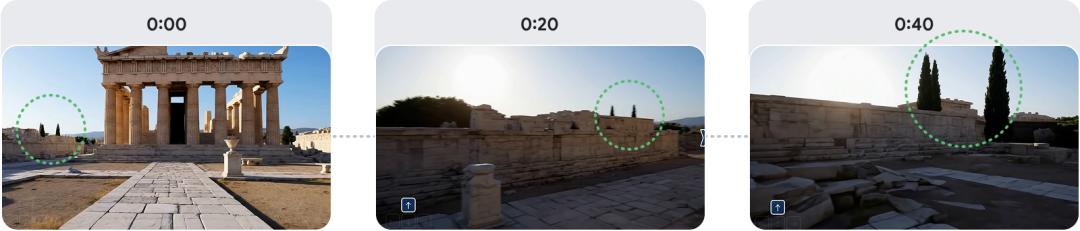
Genie 3的一致性非常高:建築物左側的樹木在整個交互過程中始終保持一致,即使它們時而進入視野時而消失
其實,Genie 2就已經具備了一些「記憶能力」。但當時,整個AI界太多令人激動的模型發佈,比如Veo 2模型幾天后也發佈了。而且,當時谷歌主打的賣點是「可以生成新的世界」,所以記憶能力就沒被強調出來。
到了Genie 3,在「記憶」上,谷歌DeepMind下了更大的決心,明確地把「增強記憶能力」作為核心目標之一。
當時設定的目標是:
超過一分鍾的記憶、
支持「實時生成」、
還能提升「分辨率」。
其實,這幾個目標本身是互相矛盾的,但谷歌無所畏懼。
説實話,直到項目快結束時,在看到最終樣本的那一刻,他們依然感到震撼。這種成果即使是預期中的,真的實現的時候還是非常令人興奮。畢竟,研究項目永遠不會有百分百的確定性。
在設計上,他們還有一個明確的方向,就是不採用「顯式表示法」。市面上已有一些方法,比如用NeRF或Gaussian Splatting等技術,通過構建明確的3D世界結構,來達到一致性。這些方法很好,在某些應用上效果不錯。
但他們堅持讓模型「逐幀生成」,這種方式對模型的泛化能力、適應多樣世界的能力更有幫助。
智能涌現,驚喜不斷
就像其他生成式模型一樣,隨着Scaling,效果確實會提升,這已經不是什麼祕密了。
儘管不如語言模型在推理能力上的涌現表現,Genie 3依然涌現出一些令人驚訝的行為。比如説,如果一個角色靠近一扇門,模型可能就會「推測」角色應該打開門;這類符合人類直覺的行為,模型現在能在一定程度上表現出來了。
還有就是對語言的理解在不斷變好,生成的內容也越來越真實,視覺效果更自然。
從Genie 2到Genie 3的提升非常明顯,特別是在「模擬現實世界能力」上有巨大飛躍。
比如物理效果的表現——像水的模擬、光照的變化,都非常驚艷。
現在已經到了一個地步,哪怕是非專業人士,看了之后也會覺得是真實拍攝的視頻。
這太驚人了。而在Genie 2時代,模型雖然大致能表現出物體該有的行為,但你還是一眼能看出「這是AI生成的,不是真的」。
現在的視頻真假難辨,進步真的很大了。
在「地形多樣性」問題:比如模型需要理解在沙地上行走、在下坡滑雪、在水中游泳,這些動作和物理反饋應該是不一樣的。
谷歌團隊發現這些行為很多都是規模和數據廣度所帶來的「涌現能力」。
換句話説,他們並沒有為這些行為做專門的訓練或設計,而是模型自己「學」出來的。它通過足夠豐富的訓練數據,掌握了這個「世界」的通用常識。大多數時候,它表現非常不錯。
比如下面的例子:
在滑雪時,角色在下坡時速度會變快,而試圖上坡時就會變慢,甚至爬不上去;
下水后,角色一般會開始游泳或濺起水花;
靠近水坑時,模型通常也會讓角色穿上雨靴。
這些行為都非常自然,和人類對真實世界的理解非常一致,而這些都是模型自己學會的,真的讓人覺得像魔法一樣。
這里還有一個有趣的權衡:既能保持世界的「物理一致性」,同時也能忠實地執行用户的提示詞。
對視頻模型來説,「低概率事件」本來很難,但Genie 3依然能有不錯的表現。
這正是它的魅力所在:
即便是一些現實中不太可能發生的場景,Genie 3也能讓你如臨其境,而不是僅僅生成一個和你身邊環境一樣的無聊視頻。
在「指令跟隨/文本對齊」,Genie 3也得到了提升,這主要得益於DeepMind內部不同項目(特別是Veo項目)的經驗遷移和知識共享。這種跨團隊協作是DeepMind的優勢。
世界模型是讓智能體走向現實世界最快的路徑。Genie 3朝着這個目標邁出了一大步。
那Genie 4、Genie 5的新特性有哪些設想?
未來的關鍵,真實感和交互性
但總的來説,Genie 3團隊最關注的始終是一件事:讓模型本身變得儘可能強大,讓它能產生更廣泛的影響,然后把創造應用的機會交給其他團隊。
他們表示最終會開放Genie 3模型。
未來確實讓人特別興奮,但也必須承認,世界模型距離真正「準確模擬現實世界」還有很大差距。
比如,把一個人放進生成的世界里,讓他隨心所欲地做任何事情,我們還遠遠做不到。
還有很多工作要做,才能讓虛擬世界的真實感和自由度接近現實。
應用還有很多,關鍵在於能否準確模擬世界,並把人放進其中。也許還能從「第三視角」觀察自己,或者與虛擬智能體互動。
他們還透露真實感和交互性是未來的關鍵。
現在機器人領域最大的瓶頸之一就是數據:能收集到的數據非常有限。
而Genie 3能生成幾乎無限的場景,這樣一來機器人就能在虛擬世界里學習,而不再侷限於現實中能採集到的視頻。這個想法真的很令人興奮。
最后一個問題:人類是不是生活在某種模擬中?
這個問題被問過很多次,得到了「哲學化」的回答:如果真是模擬,那它運行在完全不同的硬件之上
如果人類真的生活在一個模擬世界里,那它絕對不是運行在現在的硬件上的。因為我們的世界是連續的,而不是數字化的。
所有的感知都是連續的信號。
也許,在量子層面會有一些「硬件限制」,但至少和我們現在的計算機完全不同。
或許未來量子計算機,纔是運行我們這個模擬世界的真正平臺。
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。
推薦文章
港股周報 | 利空突襲?華爾街限制對衝基金槓桿做多SK海力士和三星電子; 建滔系雙雄領漲市場! 建滔集團周累漲近47%

一周財經日曆 | 美聯儲利率決議來襲,沃什首次議息會議將遭遇空前考驗?琻捷電子、溜溜梅下周上市
一周IPO | 2萬億美元太空巨頭!SpaceX首秀飆漲近20%;海清智元等3只新股火熱認購中
6月13日外盤頭條:美國和伊朗暗示和平協議即將達成 SpaceX首日上漲19.22% 市值破2萬億美元躍居全球第六
SpaceX上市首日收漲19% 第一天市值躍居全球第六
美股前瞻 | 今晚見證歷史!SpaceX 22點開始交易,股價至少漲35%?美伊諒解備忘錄簽字在即,布油跳水一度跌近5%!
SpaceX今夜重磅上市!下周一12只槓桿/反向ETF接力登場,帶你一圖看懂
華盛早報 | TACO再現!特朗普取消對伊打擊,納指反彈2.5%;市場押注黃金未來兩年再跌4成;泡泡瑪特LABUBU將亮相世界盃
