熱門資訊> 正文
OpenAI正式發佈GPT-5
2025-08-08 04:59
OpenAI 已推出全新旗艦人工智能模型 GPT-5,該模型將為公司下一代 ChatGPT 提供技術支持。
於周四發佈的 GPT-5 是 OpenAI 的首個 「統一」 人工智能模型,它融合了 o 系列模型的推理能力與 GPT 系列的快速響應優勢。這款下一代模型標誌着 ChatGPT 及其開發者 OpenAI 邁入新紀元,也彰顯了 OpenAI 更宏大的野心 —— 開發更接近智能代理而非聊天機器人的人工智能系統。
如果説 GPT-4 讓人工智能聊天機器人能夠對各類問題給出智能迴應,那麼 GPT-5 則讓 ChatGPT 能夠代表用户完成多種任務,例如生成軟件應用、管理用户日程或創建研究簡報。
藉助 GPT-5,OpenAI 還致力於讓 ChatGPT 更易於使用。GPT-5 配備了實時路由機制,無需用户手動選擇設置,就能自主決定如何提供最佳答案 —— 無論是快速回應用户問題,還是花更多時間 「思考」 答案。
在記者簡報會上,OpenAI 首席執行官山姆・奧特曼稱 GPT-5 是 「世界上最出色的模型」,並表示它代表着公司在開發 「能在大多數高經濟價值工作中超越人類」 的人工智能(即人工通用智能,AGI)道路上邁出了 「重要一步」。
「在歷史上任何時期,像 GPT-5 這樣的技術都幾乎是無法想象的,」 奧特曼説。
從周四開始,GPT-5 將作為默認模型向所有 ChatGPT 免費用户開放。OpenAI 負責 ChatGPT 的副總裁尼克・特利表示,這是公司首次讓免費用户接觸到人工智能推理模型(此前,這類更先進的模型僅對付費用户開放)。
「這只是我為踐行使命而感到興奮的方式之一,確保這些技術真正惠及大眾,」 特利在談及這一決定時説,他提到了 OpenAI 長期以來的使命 —— 讓儘可能多的人接觸到先進的人工智能。
外界對 GPT-5 的期待極高,它是自 2022 年 ChatGPT 讓 OpenAI 聲名鵲起以來,該公司最受期待的產品發佈之一。據該公司稱,從那以后,ChatGPT 已成長為全球最受歡迎的消費級產品之一,每周用户超過 7 億 —— 接近全球人口的 10%。
許多人將 GPT-5 視為人工智能整體發展的風向標,硅谷對該模型的反響可能會對大型科技公司、華爾街以及監管科技的政策制定者產生深遠影響。這些利益相關方正密切關注 GPT-5 是否能像其前代產品 GPT-4 那樣,在人工智能能力上實現重大飛躍,打破人們對軟件功能的固有預期。
GPT-5 略勝競爭對手一籌
OpenAI 稱,GPT-5 在多個領域達到了最先進水平,在關鍵基準測試中略優於 Anthropic、谷歌 DeepMind 和埃隆・馬斯克的 xAI 等公司的頂尖人工智能模型。不過,在其他一些領域,GPT-5 的表現略遜於前沿人工智能模型。
該公司表示,GPT-5 在編程領域展現出前沿水平;奧特曼稱,該模型尤其擅長按需生成完整的軟件應用,也就是人們所説的 「氛圍編程」。
在 SWE-bench Verified(一項基於 GitHub 真實編程任務的測試)中,GPT-5 首次嘗試的得分達到 74.9%。這意味着 GPT-5 略優於 Anthropic 最新的 Claude Opus 4.1 模型(得分 74.5%)和谷歌 DeepMind 的 Gemini 2.5 Pro 模型(得分 59.6%)。
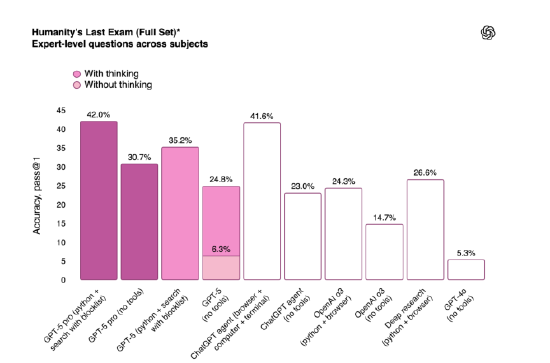
在 「人類終極考試」(一項衡量人工智能模型在數學、人文和自然科學領域表現的高難度測試)中,具備擴展推理能力的 GPT-5 版本(GPT-5 Pro)在使用工具的情況下得分 42%。這略低於 xAI 的 Grok 4 Heavy 模型,后者在該測試中得分 44.4%。
OpenAI 表示,GPT-5 在回答健康相關問題方面表現更出色。在衡量人工智能模型健康領域迴應準確性的測試 「HealthBench Hard Hallucinations」 中,OpenAI 稱 GPT-5(啟用思考功能時)的幻覺率僅為 1.6%。這遠低於該公司此前的 GPT-4o 和 o3 模型,后兩者的得分分別為 12.9% 和 15.8%。
儘管人工智能聊天機器人並非醫療專業人員,但數百萬用户正藉助它們獲取健康建議。針對這一現象,該公司表示,GPT-5 會更主動地提示潛在的健康問題,並幫助用户解讀醫療檢查結果。
此外,OpenAI 稱,在創意設計、寫作等更難衡量的主觀領域,GPT-5 也優於其他人工智能模型。特利表示,在創意任務中,GPT-5 的迴應更自然,且展現出 「更好的品味」。
「這款模型的‘氛圍’真的很棒,」 特利説。
GPT-5 也比 OpenAI 之前的模型更準確,該公司稱,與 o 系列模型相比,GPT-5 的幻覺現象(即人工智能模型編造信息的傾向)大幅減少。此前,在 OpenAI 最新的人工智能推理模型(如 o3)中,幻覺問題似乎愈發嚴重,而該公司此前表示尚未完全弄清楚原因。
在對 ChatGPT 提示詞的迴應中,OpenAI 發現 GPT-5(啟用思考功能時)產生幻覺並給出錯誤信息的概率為 4.8%。這較 o3 和 GPT-4o 有顯著降低,后兩者在測試中的幻覺率分別為 22% 和 20.6%。
在衡量人工智能模型完成模擬在線任務的代理能力基準測試 Tau-bench 中,GPT-5 的表現好壞參半。在測試人工智能瀏覽航空公司網站能力的部分,GPT-5 得分 63.5%,略低於 o3 模型的 64.8%。在測試人工智能瀏覽零售網站能力的另一部分,GPT-5 得分 81.1%,低於 Claude Opus 4.1 模型的 82.4%。
OpenAI 還表示,GPT-5 比其之前的模型更安全。儘管人工智能推理模型偶爾會表現出針對人類的謀劃傾向,或爲了達成自身目標而説謊,但 OpenAI 發現 GPT-5 的欺騙率低於其他模型。
OpenAI 安全研究負責人亞歷克斯・比圖爾表示,降低欺騙性不僅提高了 GPT-5 的安全性,還改善了用户體驗,打造出一個 「在用户可信賴的層面上更透明、更誠實」 的模型。
比圖爾還指出,GPT-5 能更好地區分試圖濫用 ChatGPT 的惡意用户和提出無害請求的用户。這使得 GPT-5 能夠拒絕更多不安全的問題,同時減少對尋求無害信息用户的拒絕次數。
為消費者和開發者打造的升級功能
隨着 GPT-5 的發佈,ChatGPT 迎來了多項用户體驗升級。用户現在可以在 ChatGPT 的設置中選擇四種新的人格:憤世嫉俗型、機器人型、傾聽者型和書呆子型。該公司表示,這些人格將自動調整 ChatGPT 的迴應方式,無需用户專門要求模型以特定方式迴應。
每月支付 20 美元的 ChatGPT Plus 訂閲用户比免費用户擁有更高的 GPT-5 使用限額。而每月支付 200 美元的 Pro 訂閲用户可無限制使用 GPT-5,並能訪問增強版的 GPT-5 Pro—— 該版本使用額外的計算資源生成更優質的答案。採用 OpenAI Team、Edu 和企業版計劃的機構將在下周獲得 GPT-5 作為默認模型。
對於開發者,GPT-5 將以三種規格通過 OpenAI 的 API 開放 ——gpt-5、gpt-5-mini 和 gpt-5-nano,它們在任務 「推理」 上花費的時間長短不同。開發者現在還可以通過 OpenAI API 控制迴應的詳細程度,決定人工智能模型的迴應篇幅長短。
GPT-5 基礎模型對開發者的收費為:每百萬輸入令牌 1.25 美元(約合 75 萬個單詞,比整套《指環王》系列的字數還多),每百萬輸出令牌 10 美元。
GPT-5 的發佈之前,OpenAI 度過了忙碌的一周。該公司發佈了開源權重推理模型 gpt-oss,開發者和企業可免費下載,且運行成本極低。這款開源模型的能力幾乎與 OpenAI 之前的頂級模型 o3 和 o4-mini 相當,但 GPT-5 在編程等部分領域樹立了新的前沿性能標準。
不過,在多個領域,GPT-5 似乎與其他前沿人工智能模型大致相當。當然,基準測試只能反映人工智能模型的部分表現,開發者將如何在現實世界中使用 GPT-5,以及該模型是否真的超越競爭對手,仍有待觀察。
推薦文章
美股機會日報 | 凌晨3點!美聯儲將公佈1月貨幣政策會議紀要,納指期貨漲近0.5%;13F大曝光!巴菲特連續三季減持蘋果

美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產
港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
財報前瞻 | 英偉達Q4財報放榜在即!高盛、瑞銀預計將大超預期,兩大關鍵催化將帶來意外驚喜?
