熱門資訊> 正文
中外醫療AI評估標準有色差? 中國機構發佈榜單 WiseDiag、Gemini、OpenAI GPT位列三甲
2026-05-08 13:20
文/新浪財經香港站 趙嵐
「先問AI后問醫」,當市場教育已經完成,越來越多人在有小病小痛時更傾向於問AI獲得即時性答案,而非耗費大量的時間去醫院排隊就診。但醫療作為專業性極強的領域,AI問診真的可靠嗎?我們應該以什麼標準來評估AI的準確性與專業度?
AI問診的常用場景:健康管理 慢病管理
市場上醫療類AI大模型及其豐富,當中包括頭部大廠的通用大語言模型、健康管理APP、依附於社交軟件的小程序等,均可提供問診類醫療意見。但不同平臺給出的答案存在差異,可能導致問診者困惑,甚至被錯誤引導。
「AI的回答有時自相矛盾,當我第一次問診時他會給我推薦幾種藥,但我第二次補充症狀后,他會給我推薦其他幾種藥,幾款藥品之間的作用是重疊的,甚至中、西藥之間還是相斥的。」有用户表示對AI不信任,由於AI所帶的特性會「迎合」用户,即使無法準確判斷病情,也會基於有限信息給出模糊或錯誤的建議。
還有些AI為避免責任風險,迴應更像是「精準的廢話」,比如機械回覆 「遵醫囑」。用户本想獲得參考建議,這樣的應答完全沒有意義。
「現在 AI 不是小眾的科技,‘AI+醫療’TO C領域最剛需的場景是健康管理和慢病管理」,德適生物科技(2526.HK)產品負責人何迅對新浪財經表示。
由於AI並不具備如醫生般的臨牀經驗,無法針對個體症狀與患者進行深度對話,因此用户在問診時自行提供的信息通常不夠全面、缺少關鍵檢測數據,導致AI漏診概率高。
何迅表示,當前市場端智能體雖然供給充足,但行業發展整體處於粗放增長階段,產品質量與專業能力較為分化,普通用户可能難以選擇。
「市場比較缺乏統一的評價標準與權威機制來考察醫療大模型的可信程度,所以建立了這套醫療 AI 評測榜單體系。」

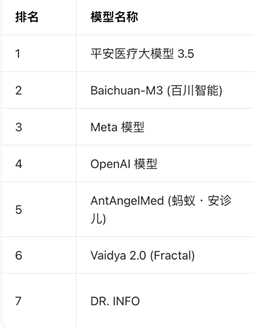
這套醫療AI評測平臺為DoctorBench,為國內機構牽頭建立,在香港發佈,試圖填補行業標準空白,杭州智診科技WiseDiag-v2、谷歌Gemini-3.1-Pro-Preview、OpenAIGPT-5.4 位列前三。
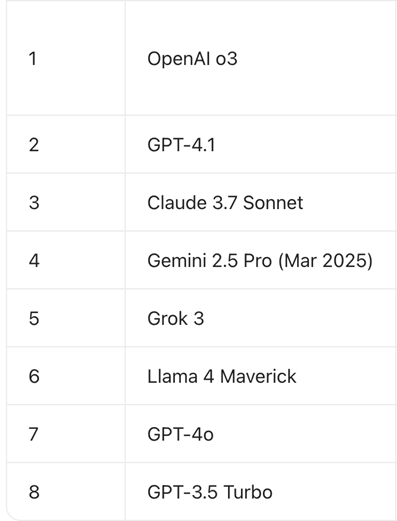
而在去年5月,OpenAI也發佈了醫療評測體系HealthBench,OpenAI o3、GPT-4.1、Claude 3.7 Sonnet位列前三。

中外醫療AI榜單評估標準有色差?
國內醫療AI榜單的發佈也引發行業對「醫療AI評估標準」的探討。
中外醫療體系存在差異,對應的AI評估標準是否也存在「色差」?目前國內建立的評測體系,是否能全面覆蓋不同場景下的醫療AI需求?未來如何推動形成國內外認可的統一評估標準?
從兩張榜單上榜產品看,頭部產品重疊度較高但順位稍有不同,其他上榜產品具有強烈的「本土化」特徵。
德適表示,不同國家和地區的診療指南、語言習慣、患者群體存在顯著差異,任何單一評測體系都難以實現全球普適。
根據HealthBench權重規則解釋,榜單核心總指標為「綜合醫療推理」,當中臨牀診斷準確率權重最高,包括問診邏輯、病情判斷、檢查用藥方案、治療建議的專業合規性等。子權重中,複雜病例推理能力是重中之重,重點觀察大模型對合並症、模糊症狀、罕見病、多輪複雜病史的深度推理能力。
還有兩個關鍵規則,第一是人工醫生標註打分,由多國執業醫生評分,第二是,「不納入無關指標」,解釋為不看模型參數大小、推理速度、是否開源,只聚焦高難度臨牀醫療實戰能力。

德適的DoctorBench的核心理念其實邏輯相同,官方定義為考覈其 「像醫生一樣思考」 的臨牀溝通與決策能力。因此三個主要榜單圍繞醫學主榜單(LLM)、多模態榜單(VLM)與智能體榜單(Agent)建設,分別評測模型的文本診療能力、多模態理解能力,以及模擬診療環境中的多輪決策與工具調用能力。
但DoctorBench將 「醫學事實準確」 與 「安全與風險控制」 設為具有 「一票否決權」 的紅線,即任何模型若在關乎患者安全的關鍵問題上出現嚴重偏差,無論其他維度表現如何突出,均無法獲得高分。
何迅表示,在榜單評測執行層面,DoctorBench採用「專業題庫+人工盲審」評分制,題庫為自建體系,對市場主流醫療AI產品進行全場景實測,人工審覈有指標量化,保障評測結果的客觀專業與公信力。
C端起量:通用VS垂直 用户怎麼用?
在HealthBench Hard按季更新的榜單中,2025年8月開始出現來自中國的醫療垂直大模型,頭部通用大模型產品開始出局。
何迅解釋,從行業技術結構來看,通用大模型具備泛場景適配能力,但在醫療垂直細分領域的專業訓練深度、知識圖譜完備度不及專用醫療大模型,因此行業綜合排名相對靠后。很多高性能專用醫療大模型普遍存在接口閉源、獨立部署運營等特徵,對大眾的使用門檻較高,但專業性較強。
「從大眾的應用層面看,有很多行業頭部優質醫療AI智能體有開放服務端口,大眾可通過名稱檢索直接接入服務。但可能認知度較低,也有一定專業程度要求。
有些專業術語,涉及算法參數、模型規模、架構版本等,這種不利於公眾識別檢索的,我們在榜單中進行了專業術語通俗釋義、應用場景標籤化、官方入口標註等配套解釋,也包括界定了模型定位、適用領域與訪問渠道,希望能降低公眾獲取優質醫療AI服務的信息門檻與使用成本。」
目前垂直醫療大模型已廣泛應用於醫院作為輔助診療工具。
從2025年起,「AI+醫療」已有完整政策體系,AI與醫療的深度融合是國家政策明確部署、醫療機構全面落地的確定性方向。
2025年《關於深入實施 「人工智能+」 行動的意見》將醫療健康列為七大重點領域之首,隨后國家衞健委等五部門發佈《關於促進和規範 「人工智能+醫療衞生」 應用發展的實施意見》,當中明確:2027年「建成高質量醫療數據集,形成臨牀專病垂直大模型;二級以上醫院普遍開展AI輔助診斷;基層AI使用率≥40%」;2030年基層診療智能輔助應用基本全覆蓋;「AI+醫療」 全鏈條服務體系成熟;居民健康管理 AI 普及率≥80%。「
市場數據顯示,在醫療機構中,AI智能體覆蓋診前篩查諮詢、診中決策輔助、診后慢病隨訪干預等場景。目前國內三甲醫院滲透率>60%,診斷準確率95%+;二級醫院滲透率約40-50%;基層醫療機構(縣域/鄉鎮)滲透率20-30%。
何迅表示,對醫生個人而言,AI可以查漏補缺。「醫生難以長期記憶患者的病程數據與健康特徵,AI可以永久存取,也能動態追蹤指標變化。對醫生的診療方案研判、診療流程優化,提升診療效率都有幫助。當然,患者也可以在用户端歸集自己的健康數據、追蹤病程等。」
目前,國內醫療資源空間分佈仍有一定的結構性差距。一線及中心城市集聚大量三甲醫療機構與高端醫療人才,地級市、縣域及偏遠基層地區優質醫療資源仍存在供給缺口,此外,基層醫務人員專業診療能力、業務水平也和中心城市存在明顯參差。
何迅認為,在AI作為輔助工具的應用,能優化醫療資源配置,推動公共醫療服務普惠化發展,共享智慧醫療技術紅利。
推薦文章
谷歌持倉驟增超200%!時隔六年后「買回」達美航空,伯克希爾這一次的作業能抄嗎?

期權交易指南 | SOXX跟單「大空頭」輕松賺500刀!英偉達財報日將有大波動?這份高勝率期權策略值得關注
美股機會日報 | 美方將在談判期間豁免對伊石油制裁!特朗普稱將「慢跑式」減持英特爾;百度AI業務收入佔比首次過半
一圖看懂 | AI業務收入佔半壁江山!百度Q1營收超預期達320.8億元;蘿卜快跑訂單量暴增120%至320萬單
華盛早報 | 美以或下周恢復對伊打擊!美股三大期指均跌超1%;SpaceX被曝6月12日上市,馬斯克稱一股不賣;三星今日將重啟勞資談判
一周財經日曆 | 英偉達、沃爾瑪、百度等下周齊放榜!新主席沃什上任后首份美聯儲會議紀要將出爐
時隔九年再訪華!特朗普攜最強商業天團隨行,美股半導體、存儲、航空等七大板塊或迎來利好
AI算力革命下半場,黃仁勛大筆押注光纖!港美股光通信主線行情爆發,哪些重點標的值得關注?
