熱門資訊> 正文
DeepSeek V4千呼萬喚始出來!梁文鋒這次要掀桌
2026-04-24 23:02

今天,中國深度求索的DeepSeek-V4人工智能模型「千呼萬喚始出來」,一點沒讓人失望。
所謂「冤家路窄」。幾個小時前,OpenAI的GPT5.5剛剛發佈,沒什麼水花——好比開演唱會的汪峰,總是幫忙預告「別的大事發生」。

DeepSeek-V4(上)和OpenAI的GPT5.5(下)
要知道,DeepSeek的兩大撒手鐗模型,2024年底發佈的V3和2025年初發布的R1,以極高推理效率和極低成本,直接掀翻了大模型Scaling Law的桌子,證明「堆算力」絕不是人工智能發展的唯一路徑,導致GPU霸主英偉達一天之內市值蒸發6000億美元,創下美股史上最大單日市值損失紀錄。
如果不是后來推理需求替代了訓練需求,全球AI算力的「敍事」都得重寫,多賺錢的GPU廠商都得迎接寒冬。
一年多后的今天,DeepSeek-V4又來「掀桌」了。
這一次被「掀翻」的,又是誰呢?

1、掀了「模型性能桌」
今天發佈的DeepSeek-V4,兩個版本。一個叫Flash,參數少點,是多快好省的日常版,沒什麼大活兒就用它;一個叫Pro,專家版,參數1.6T,主打專業高性能「服務」。
畢竟其他AI模型的更新「日新月異」,而經歷了145天,DeepSeek才發佈新模型V4,它到底厲害在哪里?
什麼數學推理能力增強、代碼輸出能力增強、多模態短板補齊、上下文窗口百萬詞元起步、API價格更低等等,其實都不是關注的重點,它們屬於AI模型「正常」的迭代升級。

DeepSeek-V4的兩個版本,Flash版和Pro版/圖源:DeepSeek
根據官網信息,V4有3大「厲害」的技術要點,真正值得注意。
一是Engram記憶模塊。今年1月深度求索發表過創始人梁文鋒的署名論文,專門談這個技術要點。簡單説,Engram是一種條件記憶,可以區分靜態知識和主動知識,即只要能「查」的就不去「算」,節約算力。
它是要解決傳統Transformer架構里,記憶和推理混在一起的問題。以前大模型累得要死,既要用「注意力」去「檢索」知識,又得用「注意力」去推理。
而Engrame可以把那些固定的、靜態的知識存入到一個類似「字典」的查找表里,使模型能夠快速調用,就不用消耗大量算力在那「現算」了。
實際效果是相當不錯的,模型的寶貴「注意力」資源釋放了,可以專心做組合推理任務。在實驗階段,一個集成270億參數的Engram的模型,在參數和浮點運算次數同等的條件下,性能超過MoE(混合專家)模型。
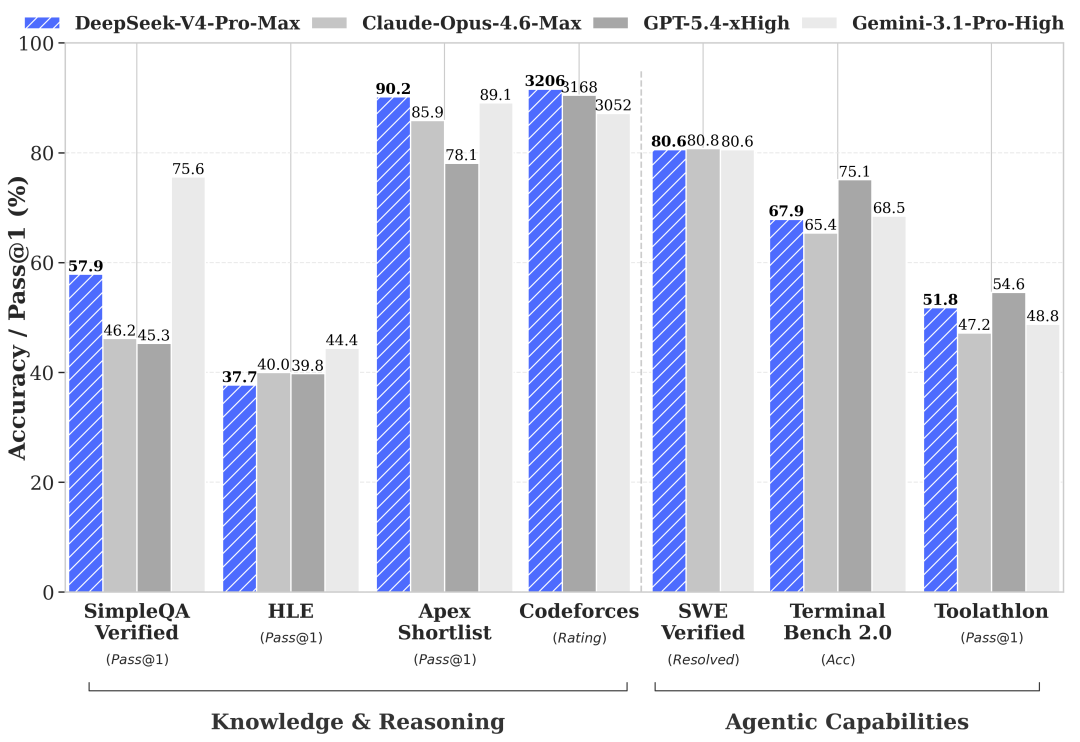
DeepSeek表示,DeepSeek-V4-Pro性能比肩頂級閉源模型/圖源:DeepSeek
二是mHC,也叫流形約束超連接。梁文鋒也在署名論文里介紹過,主要是想解決極深網絡訓練不穩定的問題。
Transfomer模型就像金字塔,一層摞一層,堆疊得很深的時候,很容易出現梯度爆炸、指令消失、訓練崩潰。
這模型就好比一座500層摩天大樓,信號是一層一層傳上去的,但如果每層都漏一點信息,等到頂樓時,指令跟噪音差不多了,傳得越多錯得越多;而且地基容易壞,樓太高,下面支撐不穩定,稍微一點搖晃樓就要塌了。
mHC等於在摩天大樓里裝了一個自動穩定電梯。它有數學上的硬約束,「每一層」都有一個閥門,不管傳進來是什麼信號,一律精準控制在一個固定範圍內:既不能讓信號太強給電梯增加負擔,也不會讓信號太弱以至於傳丟了。
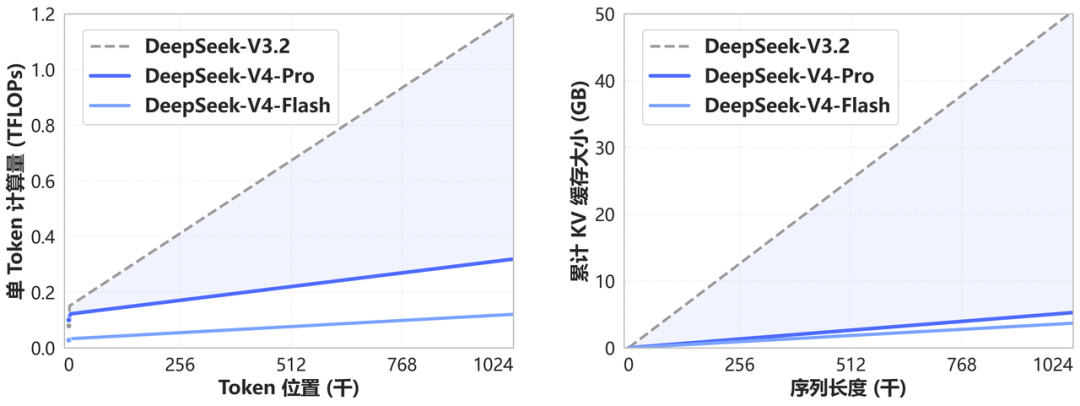
DeepSeek-V4 和 DeepSeek-V3.2 的計算量和顯存容量隨上下文長度的變化/圖源:DeepSeek
三是CSA和HCA注意力機制創新。CSA是壓縮稀疏注意力,可以看摘要找重點;HCA是高度壓縮注意力,看大綱抓主旨。
V4把這兩種方法交錯使用,一層CSA,一層HCA,就像一個人讀書,既粗看目錄大綱,又細看了一下各章內容摘要。這兩種創新解決了大模型處理長文本的兩個短板:卡頓、爆顯存。
靠這三個集中的創新點,深度求索掀了「模型性能桌」。據深度求索公司內部評測,V4的編程體驗,比Anthropic的Claude Sonnet 4.5強,交付質量接近Opus 4.6非思考模式,比起Opus 4.6思考模式還有些差距。
前幾天Opus 4.7也上線了,編程能力是強於4.6思考模式,綜合性能全球第一。這樣看,V4的性能逼近Opus4.6,也就和「全球第一」差兩個月左右。

2、掀了「GPU壟斷桌」
V4還有一個突出的本領——精打細算地榨乾了GPU的性能。
4月23日,也就是V4發佈的前一天,深度求索發佈了開源Tile Kernels模塊,使用的是TileLang語言。
TileLang是一個兼具計算機語言和編譯器前端/中端的AI算子編程語言,屬於領域特定語言(DSL),由北京大學計算機學院團隊主導開發,深度求索聯合開發,2025年在GitHub上開源。去年9月,DeepSeek的V3.2-Exp模型就使用了這個語言。
開發GPU內核,之前只能靠C++和CUDA。
CUDA是和英偉達綁定的計算平臺加編程模型,允許軟件開發者利用計算機語言,直接調用GPU中的通用計算資源。目前全球90%以上的AI算力都跑在CUDA架構上。
現在,TileLang拋開CUDA,用Python表達計算邏輯,再交給編譯器自動優化,直接改變了GPU優化的方式。
而且,TileLang可以跑在任意一種芯片上。英偉達的可以,寒武紀的可以,華為昇騰也可以——同一套邏輯能夠跨硬件執行。
TileLang-Ascend開源社區
深度求索昨天發佈的Tile Kernels模塊,是利用TileLang的Python接口編寫邏輯,然后通過TileLang的編譯器,自動生成針對特定硬件優化的底層代碼。
其優化GPU的主要辦法包括:「瓷片」(Tile)式管理,把計算任務切成固定大小的矩陣,數據搬運整塊進、整塊出;還可以一邊算「這塊」,一邊搬「下一塊」,磨刀不誤砍柴工,讓GPU的計算狀態永遠滿載,利用率極大拉高。
AI芯片使用的現實情況是,很多國產芯片的紙面算力很高,但實測的有效利用率只有3到4成,而英偉達芯片有CUDA的加持,利用率輕松達到6至7成。
現在,有了處於軟件抽象層的Tile Kernels,通過Tile級的微操,國產芯片的有效算力可以真正實現與英偉達同代產品的1比1對齊。
在使用層面,中國頂級AI芯片與英偉達頂級AI芯片的差距會越來越小。
説到底,英偉達的GPU不是唯一選擇了,連英偉達的CUDA也不是非用不可了。英偉達的股價,恐怕又得往下走一走了。

3、掀了「美國AI牌桌」
美國放行英偉達H200已經4個月,而美國商務部長盧特尼克在4月22日表示,中國一塊也沒買。
核心原因當然有「自力更生」的因素,也因為深度求索等中國公司已經可以挑戰英偉達幾款更先進的芯片,沒有必要買它的「限定版」舊款。
美國本來的算盤是,偶爾小規模放行一下英偉達的舊款芯片,其他芯片禁售、模型禁用,對中國實行一波緊似一波的圍追堵截。
而中國芯適配中國模型,已經不算新聞了。
2025年8月DeepSeek-V3.1發佈,模型推理端已經穩定支持華為昇騰910系列。今年2月,V4輕量版內測時,業內傳出其訓練和推理優先向昇騰芯片開放,暫時未向英偉達芯片開放測試權限。

DeepSeek-V4-Flash上線華為雲/圖源:華為
很可能,從訓練到推理,V4全棧使用昇騰芯片。在這一過程中,深度求索和華為共同解決了一系列技術難題,如穩定性問題、片間互聯問題、軟件工具問題,因此V4花的時間也比較長。
未來,V4模型明確支持華為昇騰950。昇騰950將於今年下半年推出,面向大模型訓練和推理,是昇騰910C的升級版,據悉採用全新架構,將是當下國內唯一商用、明確支持FP4低精度推理的AI加速卡,搭載華為自研國產HBM芯片。
其次,深度求索的創新,幾乎是逆潮流而行的,和美國的路數不一樣。主流的創新,都是不斷優化模型架構,如MoE、長上下文等等;而深度求索琢磨的是GPU內核。
而越往GPU內核走,對工程能力的要求越高。特別是Tile Kernels的意義,絕不能僅視其為算子集合,它是一套性能工程。
深度求索這樣的世界頂級團隊,可以通過這一做法獲得數倍的效率提升,但其他團隊只能依賴框架優化等辦法、甚至無法判斷硬件性能瓶頸在哪里。
芯片的真正瓶頸在於人,而不是代碼。V4露了一手「能力上限」,這不是「平均能力」所能達到的。

2025年5月4日,人們在浙江省杭州市文三數字生活街區的AI黑科技市集上體驗DeepSeek的人工智能大模型/新華社發(龍巍攝)
最后,看定價,V4依然極具市場競爭力。其中,高性能版的Pro輸入價格1元/百萬Tokens,輸出價格24元/百萬Tokens。輕量版的Flash輸入價格0.2元/百萬Tokens,輸出價格2元/百萬Tokens。
看看美國競品「高聳入雲」的價格:Claude Opus 4.7,輸入價格36.25元/百萬Tokens,輸出價格181.25元/百萬Tokens。今天發佈的GPT5.5,輸入價格36.25元/百萬Tokens,輸出價格217.5元/百萬Tokens。
靠V3和R1,DeepSeek將訓練成本極大拉低;到了V4,推理的成本也被極大拉低。
所以,往深處説,V4的一系列創新,掀了「現有模型性能」「GPU壟斷」和「美國AI封堵」這三張牌桌,並改變了全球AI領域的競爭態勢:過去總是擔心中國AI芯片不夠「頂尖」,「落后」的壓力隨處可見。
從今而后,中國AI模型,可以毫不焦慮地跑在中國AI芯片上了。
風險提示: 投資涉及風險,證券價格可升亦可跌,更可變得毫無價值。投資未必一定能夠賺取利潤,反而可能會招致損失。過往業績並不代表將來的表現。在作出任何投資決定之前,投資者須評估本身的財政狀況、投資目標、經驗、承受風險的能力及瞭解有關產品之性質及風險。個別投資產品的性質及風險詳情,請細閲相關銷售文件,以瞭解更多資料。倘有任何疑問,應徵詢獨立的專業意見。
推薦文章
新股申購 | 2只新股今起招股!「機器人大腦第一股」 仙工智能一手入場費5131.24港元,麥科醫藥-B一手入場費4242.36港元

華爾街如何操盤完成SpaceX史上最大規模IPO
華盛早報 | 特朗普放話美伊協議已達成!美股期指、黃金、白銀全線拉昇;木頭姐4.4億美元大舉買入SpaceX;SK海力士計劃8月赴美上市
美國堅持簽約時間表 伊朗提出不同協議版本 美伊談判疑雲密佈
特朗普稱美伊協議定於周日簽署 屆時霍爾木茲海峽將立即重開
港股周報 | 利空突襲?華爾街限制對衝基金槓桿做多SK海力士和三星電子; 建滔系雙雄領漲市場! 建滔集團周累漲近47%
一周財經日曆 | 美聯儲利率決議來襲,沃什首次議息會議將遭遇空前考驗?琻捷電子、溜溜梅下周上市
一周IPO | 2萬億美元太空巨頭!SpaceX首秀飆漲近20%;海清智元等3只新股火熱認購中
