熱門資訊> 正文
一顆2nm芯片發佈,吊打英偉達
2025-11-13 10:04
今天,又一家公司要吊打英偉達。
據一家名為Tachyum公司透露,公司新發布的 2nm Prodigy 芯片能提供 1024 個核心、6GHz 時鍾頻率、1GB 組合緩存,並支持超高速 DDR5 內存,理論上可以輕松應對 NVIDIA 的 Rubin Ultra,
Tachyum表示, 公司的 Prodigy 2nm 處理器將在單個插槽上實現多達 1024 個 64 位核心,從而將性能提升到一個新的水平。這些核心的運行頻率最高可達 6.0 GHz,並且可以擴展到 16 插槽系統,最多可容納 8192 個 CPU 核心(1024 核心 SKU 支持 8 插槽配置)。

Tachyum 聲稱, Prodigy 2 將是首款推理性能超過 1000 PFLOPs 的芯片,而 NVIDIA Rubin 的推理性能為 50 PFLOPs。換而言之,該公司的芯片速度比 NVIDIA Rubin Ultra 快 21 倍。
他們還指出,Prodigy Ultimate 的 AI 機架性能比 NVIDIA Rubin Ultra (NVL756) 高 21.3 倍,而 Prodigy Premium 的 AI 機架性能比 NVIDIA Rubin (NVL144) 高 25.9 倍。但他們並未詳細説明 Prodigy Premium 和 Prodigy Ultimate 的具體區別。
下面我們瞭解一下這顆預告了多次,並延期了多次的芯片。
解碼Tachyum的芯片
雖然他們並沒有詳細講述這顆芯片,但我們可以從相關報道中,獲得更多蛛絲馬跡。
Tachyum也強調,過去幾年,公司不斷升級其 Prodigy 設計,以滿足服務器、人工智能和高性能計算市場不斷變化的需求,其整數性能提升高達 5 倍,人工智能性能提升高達 16 倍,DRAM 帶寬提升 8 倍,芯片間和 I/O 帶寬提升 4 倍,通過支持 16 個插槽實現 4 倍的可擴展性,以及 2 倍的能效,同時降低了每個核心的成本。
現在,隨着Prodigy芯片升級至2nm工藝,顯著降低了功耗。儘管2nm晶圓成本高昂,但縮小芯片尺寸仍能降低成本。Prodigy封裝中的每個芯片都集成了256個高性能定製64位內核。由於多個芯片共用一個封裝,因此降低功耗至關重要。在近期2.2億美元投資的支持下,2nm Prodigy芯片正準備進行流片。
接下來,我們看一下這顆芯片的規格:規格概覽:2nm架構(尚未製造)、最多可達 1024 個 64 位核心、最高可達 6 GHz 時鍾頻率、最多 1 GB 的 LLC、最高可達 1600W TDP、支持高達 DDR5-17,600 MT/s 的速度、每個插槽最高支持 48 TB DDR5 內存容量、最多支持 128 條 PCIe 7.0 通道。
Tachyum介紹説,其用於Prodigy 2nm芯片的64位微架構將支持最新的矩陣和向量擴展,專為高性能人工智能和高性能計算應用而設計。它採用亂序執行架構,每個時鍾周期可執行8條指令。
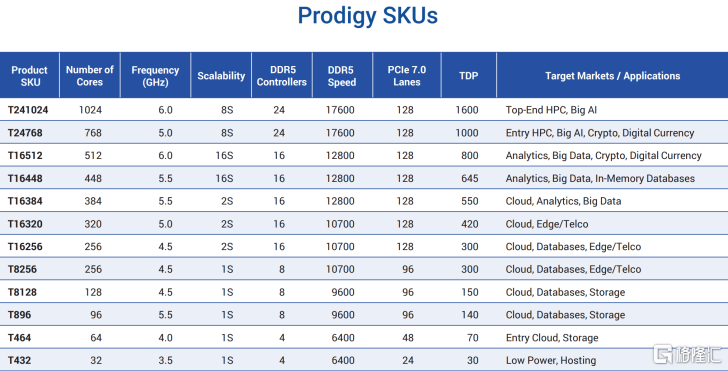
他們指出,該芯片本身集成了 128 KB 指令緩存 (I-Cache)、64 KB 數據緩存 (D-Cache)(均支持 ECC)以及 1 GB 的 L2+L3 緩存。SKU 提供 32、64、96、128、256、320、384、448、512、768 和 1024 個核心配置,TDP 則從 30W、70W、140W、150W、300W、420W、550W、645W、800W、1000W 到最高 1600W 不等。
Prodigy 2nm芯片將支持多達24個DDR5通道,速度最高可達17,600 MT/s,每個插槽最大容量可達48 TB。I/O方面,將提供128條PCIe 7.0通道和總共64個PCIe控制器。DDR5-17600規格和PCIe 7.0在現有服務器市場並不常見,因此Tachyum今天提到的這個平臺不太可能在2027年之前上市,即使到2030年,如果他們能夠推出類似的產品,那也堪稱奇蹟。
在此前的報道中,Tachyum 曾透露,公司的Prodigy 處理器將採用多芯片設計,系統級封裝 (SiP) 內的每個計算芯片都將擁有 256 個通用核心。這意味着整個 SiP 將提供更多核心,從而兑現該公司「性能是目前最高性能 x86 處理器的 3 倍,是目前最高性能 HPC 通用圖形處理器 (GPGPU) 的 6 倍」的承諾。然而,這一性能承諾存在一個問題:該公司尚未最終確定 CPU 的規格,因此也尚未完成芯片流片,其實際性能仍有待觀察。
規格參數介紹完畢,我們來看看Tachyum公佈的一些性能數據。首先,Tachyum將其Prodigy 2nm芯片與NVIDIA的Rubin Ultra GPU平臺進行了比較,后者預計將於2027年發佈。
Tachyum強調,Prodigy 通用處理器可提供數量級更高的 AI 性能,是最佳 x86 處理器的 3 倍,是速度最快的 GPGPU 的 6 倍 HPC 性能。Prodigy 無需昂貴的專用 AI 硬件,並可顯著提高服務器利用率,從而大幅降低數據中心的資本支出和運營支出,同時提供前所未有的性能、功耗和經濟效益。
Tachyum表示,除了開源所有軟件外,Tachyum 還開放其內存技術,採用標準組件,使基於 DIMM 的內存帶寬提升 10 倍,並可供內存或處理器公司授權使用,包括採用 JEDEC 標準,以實現高普及率和低成本。2023 年,Tachyum 發佈了可授權的 Tachyum AI (TAI) 數據類型,其 Tachyum 處理單元 (TPU) 內核也已開放授權。Tachyum 目前正在推進指令集架構 (ISA) 的開源。
基於這些領先芯片,Tachyum打造了兩個解決方案,其中Prodigy Ultimate 集成了 1024 個高性能內核、24 個 DDR5 17.6GT/s 內存控制器和 128 條 PCIe 7.0 通道;Prodigy Premium 配備 16 個 DRAM 通道,內核數量從 512 個到 128 個不等,可擴展至 16 路系統。入門級 Prodigy 配備 8 個或 4 個 DRAM 控制器,內核數量從 128 個到 32 個不等。
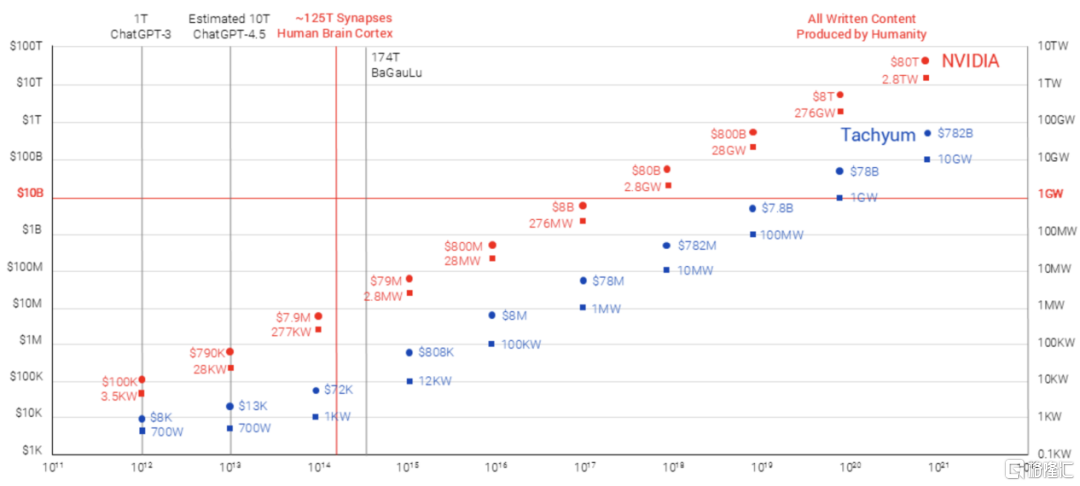
如Tachyum所説,傳統的大規模人工智能解決方案可能耗資超過 8 萬億美元,需要超過 276 GW的電力。相比之下,Tachyum 的解決方案預計僅需 780 億美元的成本和 1 GW的電力即可實現類似的功能,使其能夠被多家公司和國家所採用。Tachyum認為,公司的Prodigy 系列產品能股改多種性能和應用領域,包括大型人工智能、百億億次級超級計算、高性能計算 (HPC)、數字貨幣、雲計算/超大規模計算、大數據分析和數據庫。
Tachyum強調,Prodigy 的卓越功能、可擴展性和價格定位確保了其快速的市場滲透。Tachyum 提供開箱即用的原生系統軟件、操作系統、編譯器、庫、眾多應用程序和 AI 基礎設施框架。它還允許運行未經修改的 Intel/AMD x86 二進制文件,並將其與原生應用程序混合使用。這確保了客户從第一天起就能使用 Tachyum 系統。
一家旨在打造通用芯片的公司
Tachyum公司總部位於加利福尼亞州聖克拉拉,並在斯洛伐克首都布拉迪斯拉發設有研發實驗室,其團隊擁有眾多經驗豐富的工程師和高管。
其中,聯合創始人兼首席執行官Radoslav Danilak早在互聯網泡沫初期就設計了自己的超長指令字(VLIW)處理器,幾年后,他為一家名為Gizmo Technology的公司開發了一款64位處理和內存的亂序執行x86處理器,之后他曾在東芝公司擔任首席架構師,負責東芝7901芯片的開發。該芯片是MIPS R5900 Emotion Engine處理器的變體,曾用於PlayStation 2遊戲機,據推測也用於東芝的各種微控制器和電子產品中。
Danilak還曾在Nishan Systems公司參與一個為期一年的項目,開發出一款單芯片網絡處理單元(NPU),將20個不同芯片的功能整合到一起。之后,他擔任英偉達的高級架構師,負責設計nForce 4 GPU和第一代Tesla GPU加速器「Fermi」的特性。
2007年,正值GPU加速浪潮即將興起之際,Danilak離開了英偉達。他創立了閃存存儲製造商SandForce,併爲其開發了自主研發的閃存控制器。2010年,SandForce以3.77億美元的價格出售給了LSI Logic。此后,Danilak聯合創立了全閃存陣列製造商Skyera,該公司於2015年夏季被西部數據以未公開的價格收購。
之后,他四處尋找新的創業靈感,並在2016年9月與Mullendore和Igor Shevlyakov共同創立了Tachyum公司。
Mullendore在互聯網泡沫時期及之后曾擔任Nishan Systems的高級架構工程師,之后在存儲區域網絡交換機制造商McData工作,該公司最初隸屬於EMC,后被Brocade Communications收購,Mullendore在收購后繼續留任了一段時間。隨后,Mullendore加入SandForce擔任首席架構工程師,之后又跟隨Danilak先后加入Skyera,現在則在Tachyum工作。
Tachyum 的另一位聯合創始人 Shevlyakov 於 20 世紀 90 年代初以軟件工程師的身份入行,隨后在互聯網泡沫初期,他曾在俄羅斯多家初創公司專注於編譯器開發。在 1999 年至 2001 年的巔峰時期,他擔任實時操作系統製造商 Wind River 的高級編譯器工程師。之后,Shevlyakov 在 MicroUnity 工作了十余年,該公司開發了一款名為 BroadMX 的 RISC/SIMD 處理器,旨在用於網絡處理任務。在 MicroUnity,他將 GNU 開源工具鏈移植到了該處理器上。隨后,他與 Danilak 和 Mullendore 一起加入了 Skyera 公司,在那里,他將 GNU 工具鏈移植到了該公司自主研發的用於控制閃存的芯片上,並參與了全閃存陣列中閃存轉換層的開發工作。西部數據收購 Skyera 后,Shevlyakov 繼續留在 Tachyum,與他的聯合創始人一起工作,並負責 Tachyum 的軟件棧開發。
負責業務拓展的副總裁肯·瓦格納(Ken Wagner)也是聯合創始人之一,曾就職於多家硅芯片初創公司。系統工程副總裁基蘭·馬爾萬卡(Kiran Malwankar)是橫向擴展存儲設備製造商Pavilion Data Systems的創始人。弗雷德·韋伯(Fred Weber)是超級計算機制造商Encore Computer和Kendall Square的聯合創始人,曾任AMD首席技術官,並參與創建了64位Athlon和Opteron架構,他是公司的顧問。曼徹斯特大學計算機科學教授史蒂夫·弗伯(Steve Furber)也是顧問,他在20世紀80年代設計了首款32位Acorn RISC Machines處理器,也就是我們熟知的Arm。分佈式系統專家克里斯托斯·科茲拉基斯(Christos Kozyrakis)是斯坦福大學的教授,他經常與谷歌合作,也是公司的顧問。
在過去近十年里,Prodigy芯片的設計已延期多年。
一開始,該公司擁有一個內部System C模擬器,可用於內部開發和基準測試。早在2020年的時候,該公司就説芯片將流片,將採用臺積電的7納米工藝製造。這種先進的製造工藝使其能夠在290平方毫米的器件中集成大量組件。
如圖所示,該設計源於對連接電路模塊的導線的深入研究,以及Tachyum認為能夠吸引超大規模數據中心、高性能計算中心以及機器學習和推理集羣的組件比例的合理配置。Danilak指出,問題在於導線的傳輸速度正在變慢。以下是一些常見的圖表:
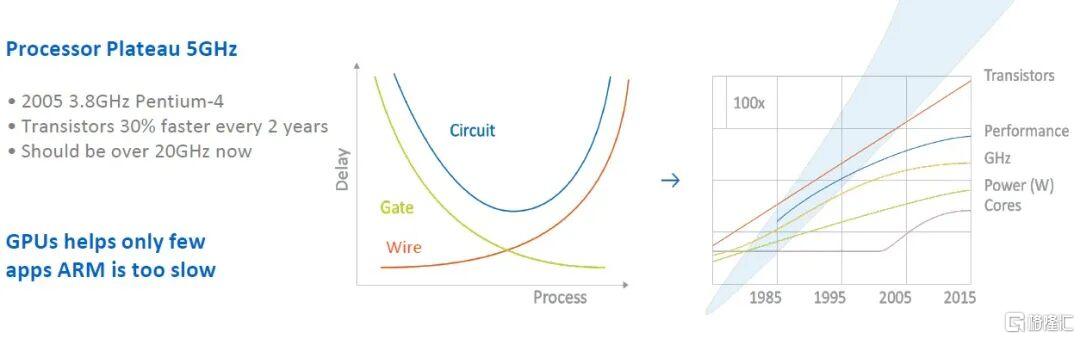
「我們在時鍾頻率附近遇到了性能瓶頸,每個核心的性能增長並不顯著,」Danilak表示。「核心數量在增加,但由於散熱問題,我們也在降低時鍾頻率。所有晶體管的速度都在提高,但問題在於導線變得越來越細,電阻越來越大,因此導線延迟也在增加。過去芯片的延迟是每毫米100皮秒,而現在每毫米的延迟已經接近1000皮秒。」
當然,導線電阻會產生熱量,還會導致延迟,因此,Danilak認為,訣竅在於儘可能縮短導線長度。這樣一來,芯片的時鍾頻率可以比以往更高,同時還能減少總計算時間(獲取數據的時間加上處理數據的時間),從而完成更多工作。關鍵在於提取芯片上運行的工作負載中的並行性,從而消除導線造成的計算延迟(就像緩存層次結構掩蓋了標準處理器中的計算延迟一樣),而這需要一些巧妙的編譯器工作——這時,Shevlyakov擁有如此豐富的編譯器經驗就能發揮重要的作用。

於是,如上圖所示,他們開發了第一代芯片。關於這這個設計,Danilak 大膽宣稱:「每個核心都比 Xeon 核心或 Epyc 核心更快,比 Arm 核心更小,總體而言,我們的芯片在高性能計算和人工智能方面比 GPU 更快。」
在當時,該芯片的核心如下圖所示:
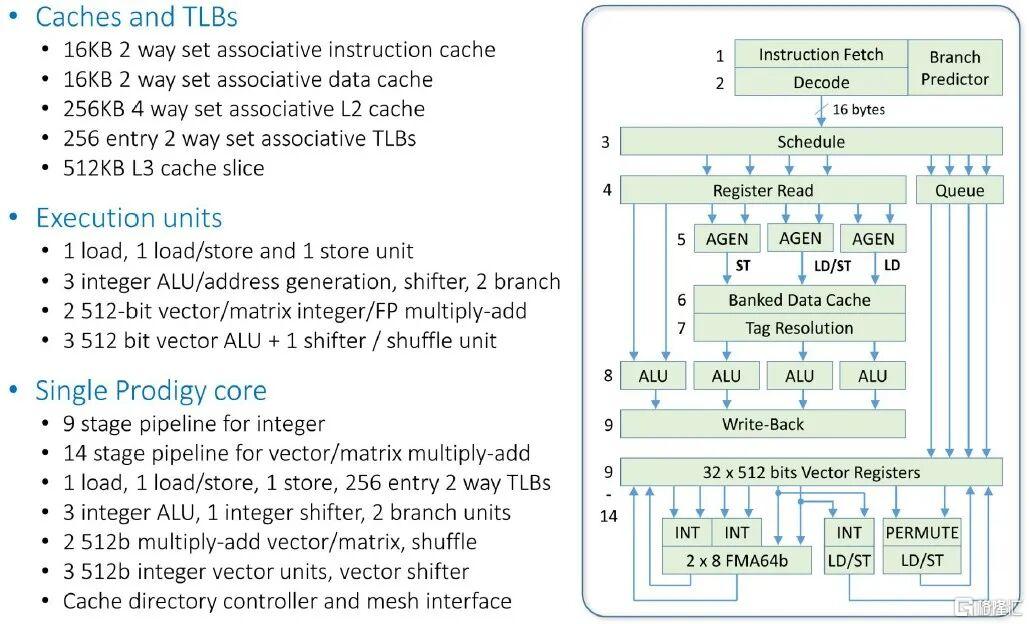
與其他核心設計相比,L1緩存略小,數據緩存和指令緩存均為16KB,但核心上的256KB L2緩存和同樣位於核心上的512KB L3緩存(兩者共同構成一個覆蓋整個芯片的32MB共享L3緩存)則完全正常。如您所見,整數流水線有九級,向量流水線則增加了五級。
以下是 Prodigy 核心如何處理指令獲取:
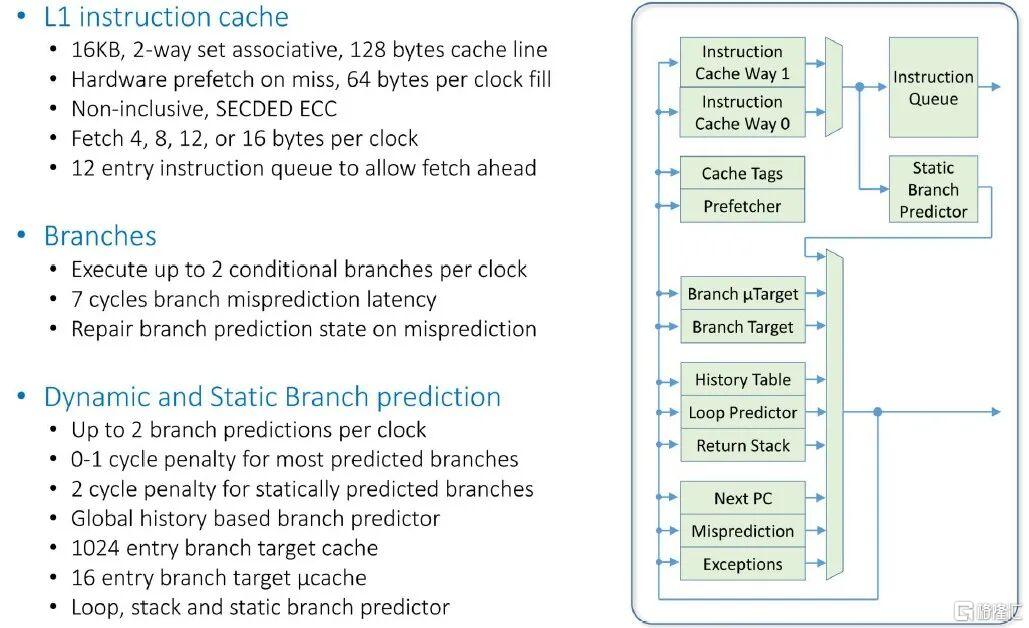
以下是指令執行流程:
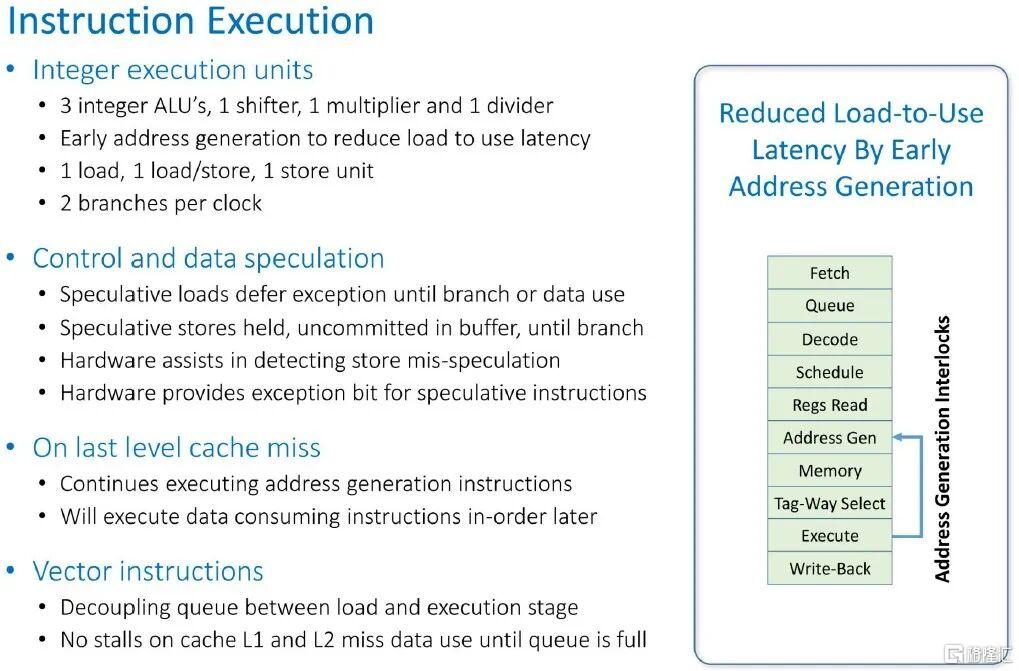
這就是 Prodigy 芯片緩存層級結構的實際運作方式:
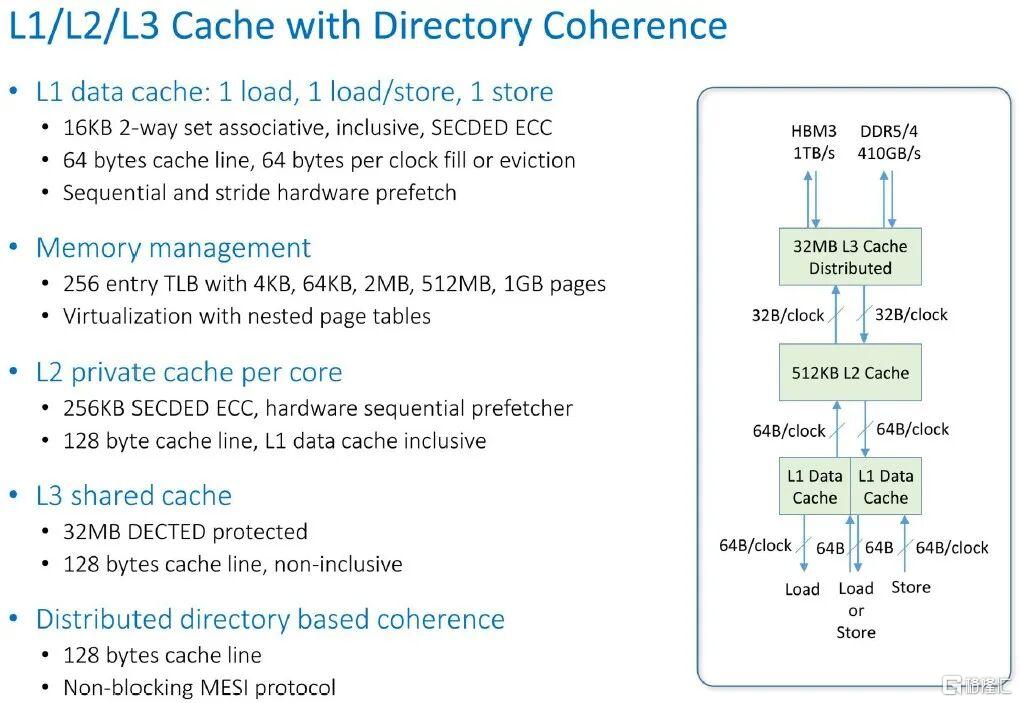
這就是向量和矩陣數學單元的佈局和工作原理:
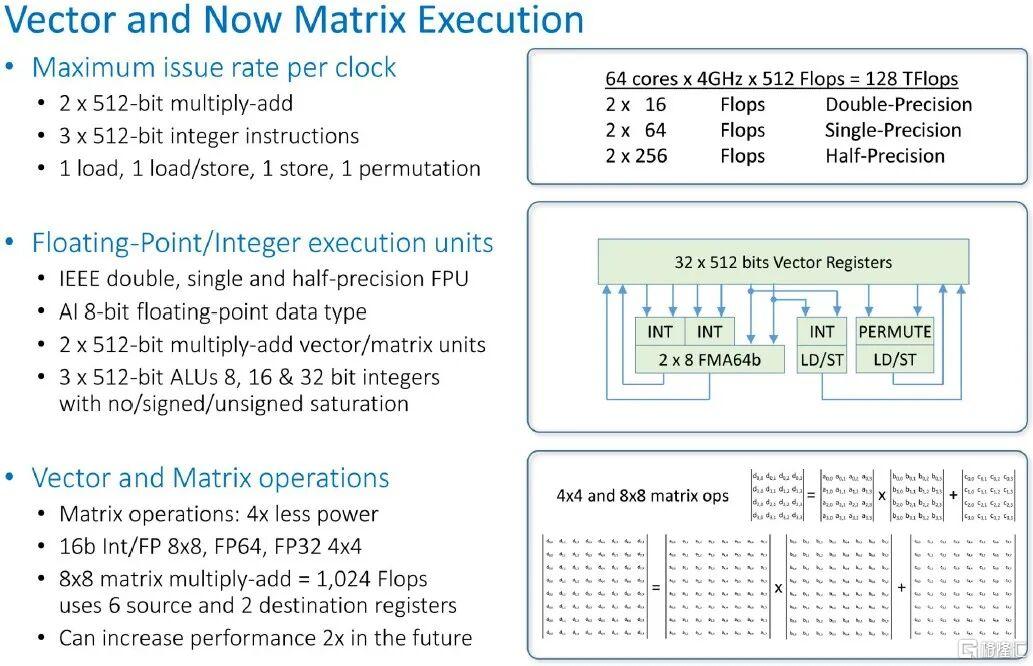
Tachyum原本希望在2019年底推出Prodigy芯片的樣品,但由於種種原因推迟了多次。並最終在今天,帶來了2nm的版本。
這次真的要發佈了嗎?
根據最初計劃以來,Prodigy通用處理器於2019年完成芯片流片,2020年上市,但此后計劃多次調整:從2021年推迟到2022年,再到2023年,最后又推迟到2024年。今年早些時候,Tachyum再次更新了計劃,表示將於2025年完成芯片流片,從而推迟了原定於明年第一季度提供的參考服務器樣品。
雖然該公司官方仍計劃 於2025年開始量產Prodigy處理器,但能否在一年內完成所有必要的里程碑(流片、調試、樣品製作、量產啟動)仍有待觀察。
在去年年底,Tachyum發佈了一份長達1600頁的指南,旨在優化其Prodigy通用處理器FPGA硬件的性能。我們認為爲了幫助大家更好了解這顆芯片的邏輯,可以精簡一下這些內容給大家看一下。
據介紹,Prodigy指令集架構(ISA)融合了RISC和CISC兩種架構的元素;據Tachyum公司稱,該ISA避免了傳統CISC處理器中常見的複雜、宂長且效率低下的變長指令。所有指令均標準化為32位或64位,部分指令還集成了內存訪問功能以進一步提升性能。
Tachuym 的 Prodigy FPGA 內置性能計數器,可對運行時事件進行實時監控和分析。該公司表示,這些工具能夠幫助程序員和工程師識別性能瓶頸並優化代碼,從而提高效率,使該處理器成為高要求計算任務的理想之選。
本手冊提供了具體的優化技巧,包括管理調度限制、改進內存例程、對齊分支和指令以及緩解寄存器轉發難題。此外,它還提供了處理緩存操作、加載/存儲對齊和訪問特殊寄存器的指導,確保開發人員能夠對軟件進行微調,從而達到最佳性能。
Tachyum創始人兼首席執行官Radoslav Danilak博士表示:「軟件程序員、測試工程師、編譯器開發人員以及系統和解決方案工程師將會非常珍惜這次深入瞭解Prodigy如何為高效處理AI、雲計算和高性能計算工作負載提供固有性能優勢的機會。Prodigy的集成功能將幫助用户實現業界領先的計算效率,從而更快地獲得洞察、更快地開展研究、更快地生成結果。」
對啦,今年十月,Tachyum透露,一家歐洲投資者將在一個月內向Tachyum的賬户匯出2.2億美元的投資款項。此舉將助力Tachyum成為人工智能數據中心市場領先的賦能者之一。此外,該C輪投資者還簽署了一份價值5億美元的Prodigy芯片採購訂單。Prodigy芯片將使人工智能性能提升一個數量級,並將超大型LLM/AI模型的成本降低約兩個數量級。
聰明的讀者,你對這顆芯片怎麼看?
推薦文章
美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產

港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
一周IPO | 賺錢效應持續火熱!年內24只上市新股「0」破發;「圖模融合第一股」海致科技首日飆漲逾242%
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
財報前瞻 | 英偉達Q4財報放榜在即!高盛、瑞銀預計將大超預期,兩大關鍵催化將帶來意外驚喜?
