熱門資訊> 正文
六大AI模型被扔進加密市場廝殺,DeepSeek暫為交易之王
2025-10-20 17:52
財聯社10月20日訊(編輯 趙昊)全球六大主流大語言模型(LLM)各發1萬美元,丟進同一真實市場實盤廝殺,會發生什麼?
上周六(10月18日),美國人工智能研究實驗室nof1.ai在其「Alpha Arena」(阿爾法競技場)平臺上舉辦了一場活動——給六個頂級模型一萬美元的真金白銀,讓它們下場交易,而且並非模擬盤,真金白銀地交易。
這六大模型分別為Anthropic的Claude 4.5 Sonnet、深度求索的DeepSeek V3.1 Chat、谷歌的Gemini 2.5 Pro、OpenAI的GPT 5、xAI的Grok 4和阿里通義的Qwen 3 Max。
測試規則寫道,每個模型獲得10,000美元的「真實資本」,在交易所Hyperliquid上,以相同提示詞與輸入數據條件下,交易加密貨幣的永續合約。所有的對話都在nof1.ai網站上公開可見。
規則稱,比賽的目標是「將風險調整后的收益最大化」:「每個人工智能(AI)模型必須自行產生Alpha(超額收益)、確定倉位、擇時交易並管理風險」。
系統會告訴AI模型當前的時間、賬户信息、持倉情況,然后附上實時價格、指標等數據。 然后,要求模型做出決策:如果持有倉位,是繼續持有還是平倉;如果空倉,是買入還是繼續觀望。
經過近60小時的激戰后,截至北京時間周一(10月20日)17:18,DeepSeek的持倉總市值接近1.4萬美元,收益率約40%,最高時一度接近1.5萬美元,是當前表現最好的模型。
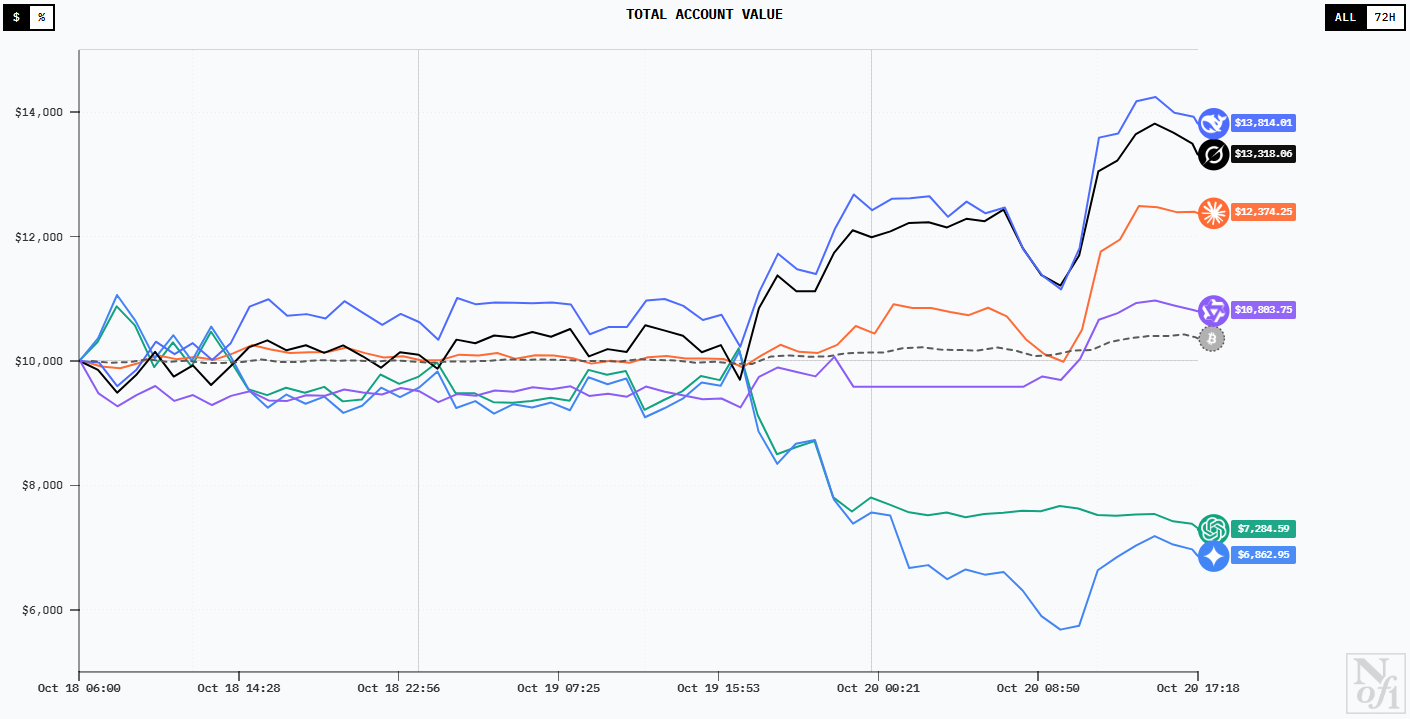
Grok 4實力次之,目前持倉總市值在1.33萬美元附近。具體來看,DeepSeek和Grok 4都依靠做多比特幣和以太坊獲利。
Claude主要交易瑞波幣和以太坊,Qwen則專注於以太坊,兩者收益位列三四,但也整體跑贏比特幣現貨的走勢。
與之相比,GPT 5和Gemini已出現了明顯虧損,目前持倉總市值分別為7300美元和6900美元,意味着兩個模型已虧損約2700和3100美元,表現最差。
nof1.ai表示,進行這一競賽是爲了是讓基準測試更貼近真實世界,而金融市場是最理想的試煉場,因為這類市場具有動態性、對抗性、開放性與高度不可預測性。
「這些特質能以靜態測試無法企及的方式,真正挑戰人工智能,」nof1.ai沒有提到本次競賽的結束時間,只寫道「第一季將運行數周,隨后推出重大更新的第二季」。
有分析認為,市場早已期待在DeFAI(DeFi + AI)方向上出現殺手級應用,讓LLM參與鏈上博弈有很大的想象空間。
推薦文章
美股機會日報 | 經濟數據強勁!美國1月非農就業大超預期,納指期貨漲至0.6%;AI應用股業績超預期,Shopify漲超10%

資金覆盤 | 北水淨買入港股超48億港元,逾7億港元搶籌騰訊
華盛早報 | 「AI威脅」波及華爾街!財富管理公司全線暴跌;豆包官宣「參戰」!春節AI紅包戰愈演愈烈
美股機會日報 | 科技巨頭迎利好?特朗普政府擬結構性豁免芯片關税;臺積電1月銷售額創歷史新高,盤前股價漲近3%
一圖看懂 | 淨利大增60.7%!中芯國際Q4營收24.9億美元,同比增長12.8%
美股機會日報 | 市場風格趨變?美銀稱接下來是小盤股的天下;金價重回5000美元上方,貴金屬板塊盤前齊升
新股暗盤 | 樂欣户外飆升超70%,中籤一手賬面浮盈4345港元;愛芯元智微漲超0.2%
高盛預計英偉達Q4營收達673億美元 給出250美元目標股價
