熱門資訊> 正文
破局算力浪費 阿里雲AI成果入選頂會 GPU用量削減82%
2025-10-18 21:45
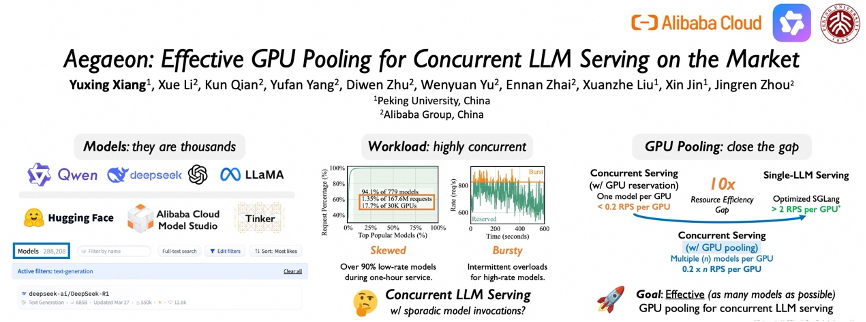
《科創板日報》10月18日訊(編輯 宋子喬) 近日,阿里雲提出的計算池化解決方案「Aegaeon」成功入選頂級學術會議SOSP 2025,該方案可解決AI模型服務中普遍存在的GPU資源浪費問題,大幅提升GPU資源利用率,目前其核心技術已應用在阿里雲百鍊平臺。
 SOSP(操作系統原理研討會)由ACM SIGOPS主辦,是計算機系統領域頂級學術會議,平均每年收錄的論文數量僅有數十篇,被譽為計算機操作系統界的「奧斯卡」,入選論文代表了操作系統和軟件領域最具代表的研究成果。本屆SOSP大會上,系統軟件與AI大模型技術的融合成為新的趨勢。
SOSP(操作系統原理研討會)由ACM SIGOPS主辦,是計算機系統領域頂級學術會議,平均每年收錄的論文數量僅有數十篇,被譽為計算機操作系統界的「奧斯卡」,入選論文代表了操作系統和軟件領域最具代表的研究成果。本屆SOSP大會上,系統軟件與AI大模型技術的融合成為新的趨勢。
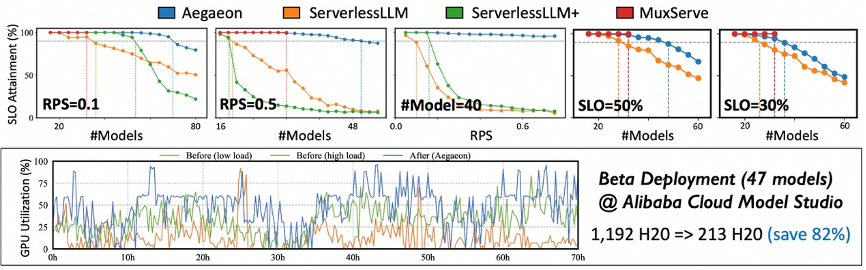
數據顯示,在阿里雲模型市場為期超三個月的Beta測試中,Aegaeon系統在服務數十個參數量高達720億的大模型時,所需的英偉達H20 GPU數量從1192個減至213個,削減比例高達82%(見下圖)。GPU用量削減82%意味着公司硬件採購成本將顯著降低,這對於動輒使用成千上萬張GPU的大型模型服務商至關重要。
 在真實的模型服務場景中,少數熱門模型(如阿里的Qwen)承載了絕大多數用户請求,而大量不常被調用的「長尾」模型卻各自獨佔着GPU資源。數據顯示,在阿里雲模型市場中,曾有17.7%的GPU算力僅用於處理1.35%的請求,資源閒置嚴重。
在真實的模型服務場景中,少數熱門模型(如阿里的Qwen)承載了絕大多數用户請求,而大量不常被調用的「長尾」模型卻各自獨佔着GPU資源。數據顯示,在阿里雲模型市場中,曾有17.7%的GPU算力僅用於處理1.35%的請求,資源閒置嚴重。
而Aegaeon系統通過GPU資源池化,打破了「一個模型綁定一個GPU」的低效模式。
Token級調度是該系統的核心創新點,Aegaeon多模型混合服務系統在每次生成下一個token后動態決定是否切換模型,實現精細化管理,同時,通過組件複用、顯存精細化管理和KV緩存同步優化等全棧技術,Aegaeon將模型切換開銷降低97%,確保了token級調度的實時性,可支持亞秒級的模型切換響應。
據介紹,Aegaeon系統支持單GPU同時服務多達7個不同模型,相比現有主流方案提升1.5-9倍的有效吞吐量,實現2-2.5倍的請求處理能力。
如何從底層系統軟件層面優化,以更好地支撐和賦能上層AI應用,已成為全球學術界和工業界關注的焦點。未來AI的發展將不僅依賴於硬件算力的單純增長,更需要通過系統級的軟件創新來深度挖掘現有硬件的潛力。
推薦文章
美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產

港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
一周IPO | 賺錢效應持續火熱!年內24只上市新股「0」破發;「圖模融合第一股」海致科技首日飆漲逾242%
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
財報前瞻 | 英偉達Q4財報放榜在即!高盛、瑞銀預計將大超預期,兩大關鍵催化將帶來意外驚喜?
