熱門資訊> 正文
面壁智能發佈語音生成基座模型VoxCPM,稱可媲美真人、能用方言
2025-09-18 19:04
9月18日,面壁智能發佈0.5B參數尺寸的語音生成基座模型VoxCPM。該模型由面壁智能與清華大學深圳國際研究生院人機語音交互實驗室(THUHCSI)聯合研發。目前,VoxCPM已在GitHub、Hugging Face等平臺開源。
VoxCPM 是一個端到端的擴散自迴歸語音生成模型,旨在從輸入文本直接合成高質量的連續語音表徵,並且支持流式地實時輸出生成音頻片段。與當前 CosyVoice、FireRedTTS 及 SparkTTS 等普遍遵循將連續的語音信號轉換為離散的聲學詞元(Speech token)序列進行處理的方法不同,VoxCPM 採用融合層次化語言建模和局部擴散生成的端到端 TTS 方案。
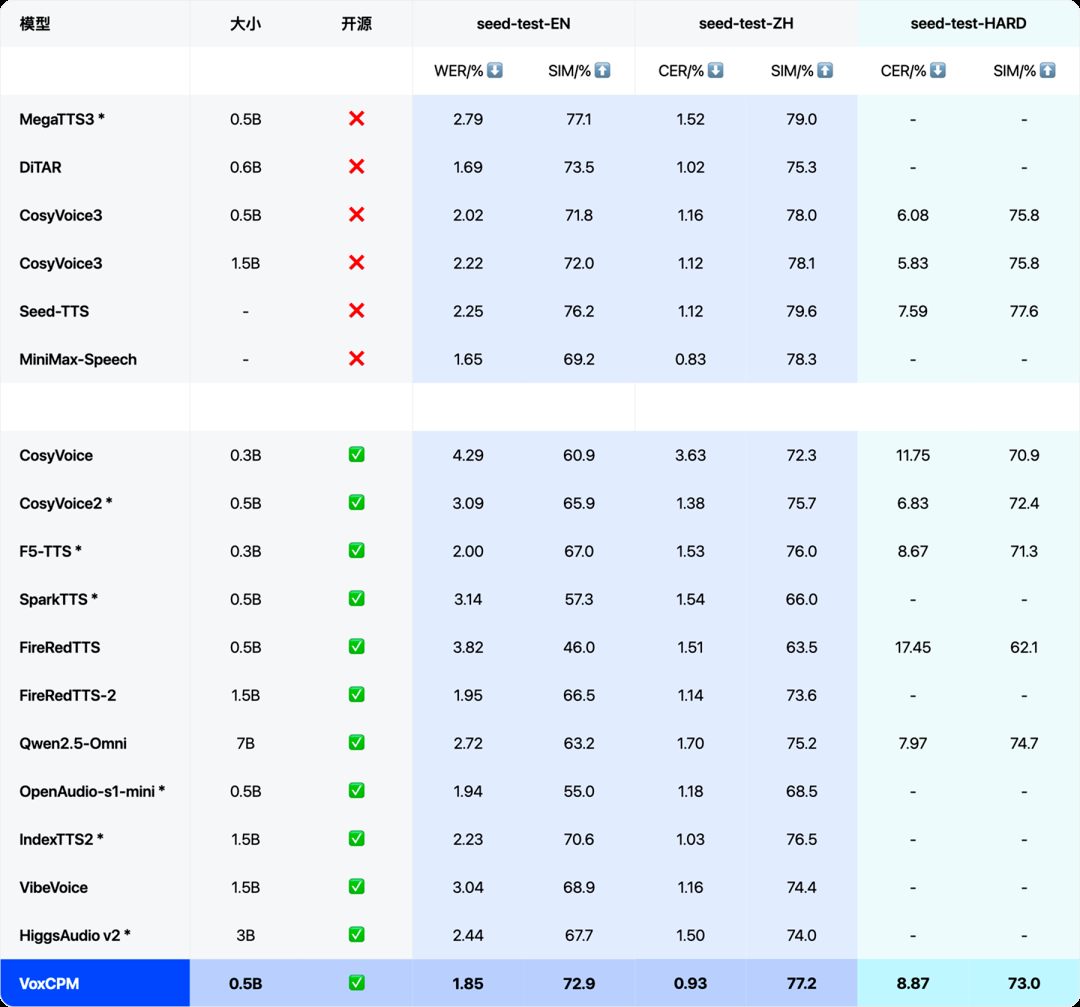
據介紹,VoxCPM 在 Seed-TTS-EVAL 等權威語音合成評測榜單中,相似度、詞錯誤率等關鍵指標上均達到了業界 SOTA 水平。在單 NVIDIA RTX 4090 顯卡上實現了 RTF(Real-Time Factor)≈ 0.17 的高效推理速度,且理論上支持流式輸出。該模型採用融合層次化語言建模和局部擴散生成的連續表徵端到端 TTS 方案,顯著提升了語音生成的表現力、自然度、穩定性。
VoxCPM 可根據對文本內容的超強理解,自主選擇合適的聲音、腔調、韻律風格生成音頻。比如,化身為天氣預報員字正腔圓的播報、英雄將領戰前慷慨激昂的演講,還可以模擬方言主播等。
在中文語境下,VoxCPM 支持公式、符號音頻合成。此外,VoxCPM還支持音素標記替換,實現自定義讀音糾正等功能。
推薦文章
美股機會日報 | 凌晨3點!美聯儲將公佈1月貨幣政策會議紀要,納指期貨漲近0.5%;13F大曝光!巴菲特連續三季減持蘋果

美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產
港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
財報前瞻 | 英偉達Q4財報放榜在即!高盛、瑞銀預計將大超預期,兩大關鍵催化將帶來意外驚喜?
風險及免責提示:以上內容僅代表作者的個人立場和觀點,不代表華盛的任何立場,華盛亦無法證實上述內容的真實性、準確性和原創性。投資者在做出任何投資決定前,應結合自身情況,考慮投資產品的風險。必要時,請諮詢專業投資顧問的意見。華盛不提供任何投資建議,對此亦不做任何承諾和保證。
