熱門資訊> 正文
阿里巴巴股價創近4年新高!或迎來DeepSeek時刻?開源新架構模型:推理快10倍、成本暴降90%
2025-09-12 11:38
今天凌晨2點,阿里巴巴開源了新架構模型Qwen3-Next-80B-A3B,對混合注意力機制、高稀疏性MoE、訓練方法等進行了大幅度創新,迎來了自己的DeepSeek時刻。
此外,據The Information報道稱,百度和阿里巴巴 正在使用自主研發的芯片來訓練人工智能模型。隔夜美股市場上, 阿里巴巴暴漲8%,不僅強勢突破3月底的前高,也刷新2021年底以來的新高。港股阿里巴巴-SW也大漲6%,股價升破150港元。
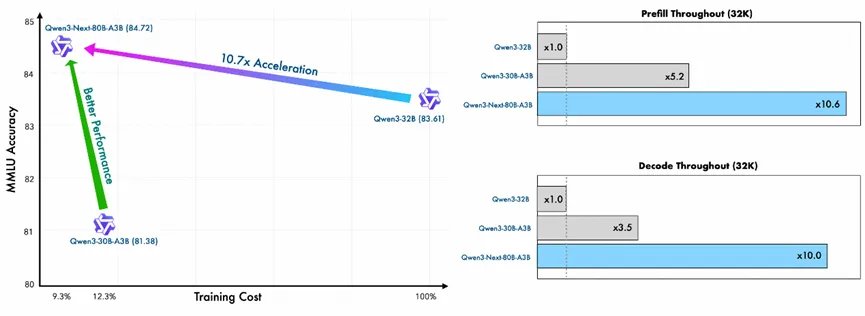
Qwen3-Next是一個混合專家模型總參數800億,僅激活30億,訓練成本較Qwen3-32B暴降90%,推理效率卻提升10倍,尤其是在超長文本32K以上的提示場景中。
性能方面,Qwen3-Next的指令微調模型在推理與長上下文任務中,可媲美阿里的旗艦模型Qwen3-235B;思考模型則超過了谷歌最新的Gemini-2.5-Flash思考模型,成為目前最強低能耗開源模型之一。
在線體驗:https://chat.qwen.ai/
開源地址:https://huggingface.co/collections/Qwen/qwen3-next-68c25fd6838e585db8eeea9d
https://modelscope.cn/collections/Qwen3-Next-c314f23bd0264a
阿里API:https://www.alibabacloud.com/help/en/model-studio/models#c5414da58bjgj
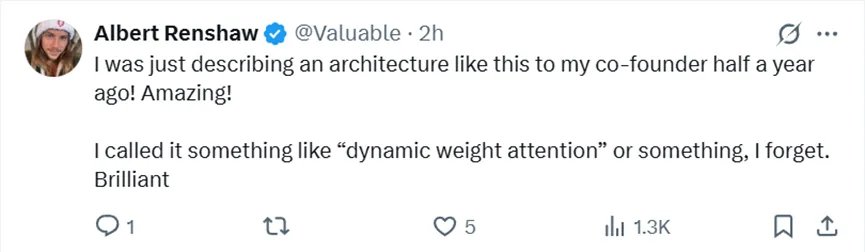
網友對阿里新模型的架構非常讚賞,表示,半年前我纔剛跟聯合創始人聊過類似這樣的架構!當時好像把它叫做 「動態權重注意力」 之類的,具體名字記不太清了。這設計真的太出色了!
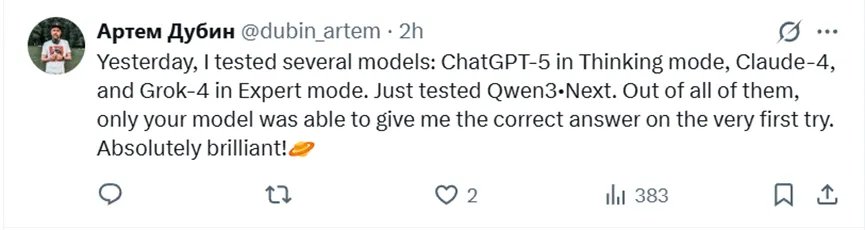
昨天我測試了好幾款模型:思維模式下的 ChatGPT-5、Claude-4,還有專家模式下的 Grok-4。剛剛又測了Qwen3 Next。在所有這些模型里,只有你們這款模型第一次嘗試就給了我正確答案。真的太出色了!
未來以來,這個模型擊敗了谷歌的Gemini-2.5-Flash。
在這里看到 DeltaNet的應用,真的有點讓人驚喜!我很好奇,如果換成模型架構發現的AlphaGo 時刻這篇論文中提出的模型架構,這款模型的性能會發生怎樣的變化?
800 億參數、超高稀疏性再加上多token預測,這配置太驚艷了!要是你的 GPU 有足夠顯存,用它跑起來速度絕對飛快。
基本上老外對阿里的創新模型非常滿意,讚美超多。
Qwen3-Next架構簡單介紹
阿里認為上下文長度擴展與總參數擴展是大模型未來發展的兩大核心趨勢,為在長上下文和大參數場景下進一步提升訓練與推理效率,他們設計了全新的模型架構Qwen3-Next。
相較於Qwen3的MoE結構,Qwen3-Next進行了多項關鍵改進,包括混合注意力機制、高稀疏性MoE結構、利於訓練穩定性的優化手段,以及可實現更快推理的多token預測機制。
在覈心特性方面,Qwen3-Next採用門控DeltaNet+門控注意力的混合創新架構。線性注意力雖能打破標準注意力的二次複雜度,更適合長上下文處理,但僅用線性注意力或標準注意力均有侷限。

線性注意力速度快但召回能力弱,標準注意力推理時成本高、速度慢。經系統實驗驗證,門控DeltaNet的上下文學習能力優於滑動窗口注意力、Mamba2等常用方法,將其與標準注意力按3:1比例,75%層用門控DeltaNet,25%層保留標準注意力結合,模型性能持續超越單一架構,實現性能與效率的雙重提升。
標準注意力層還進行了多項增強,如採用此前研究中的輸出門控機制以減少注意力低秩問題、將每個注意力頭的維度從128提升至256、僅對前25%位置維度應用旋轉位置編碼以改善長序列外推能力。
稀疏性設計上,Qwen3-Next採用超高稀疏性MoE結構,800億總參數在每步推理中僅激活約30億,佔比3.7%。實驗表明,在全局負載均衡的前提下,固定激活專家數量並增加專家總參數,能穩步降低訓練損失。與Qwen3的MoE相比,Qwen3-Next將總專家數擴展至512個,結合10個路由專家+1個共享專家的設計,在不影響性能的同時最大化資源利用率。
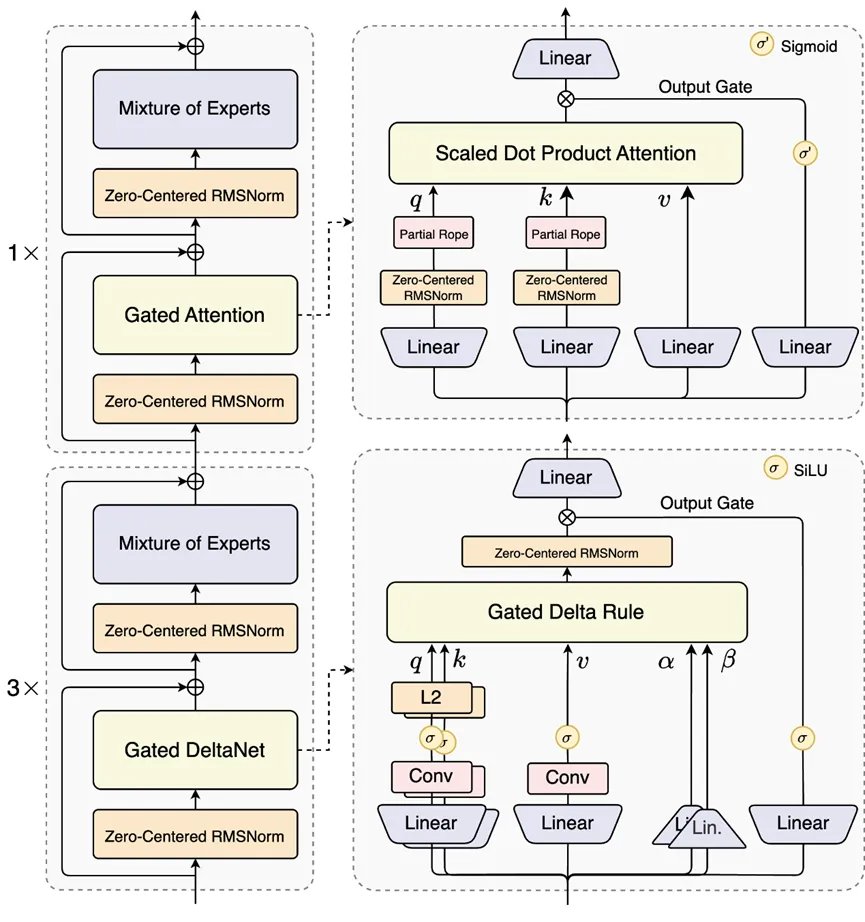
訓練穩定性優化方面,注意力輸出門控機制有效解決了注意力Sink、大規模激活等問題,保障模型數值穩定性;針對Qwen3中QK-Norm存在的部分層歸一化權重異常增大問題,Qwen3-Next採用零中心RMSNorm,並對歸一化權重施加權重衰減以防止無界增長;初始化時對MoE路由器參數進行歸一化,確保訓練初期每個專家都能被無偏選擇,減少隨機初始化帶來的噪聲。這些設計提升了小規模實驗的可靠性,保障大規模訓練平穩進行。
多token預測機制也是Qwen3-Next的亮點,其原生引入的多token預測(MTP)機制,不僅為投機解碼提供高接受率的MTP模塊,還能提升模型整體性能,同時針對MTP的多步推理性能進行優化,通過保持訓練與推理一致性的多步訓練,進一步提高實際場景中投機解碼的接受率。
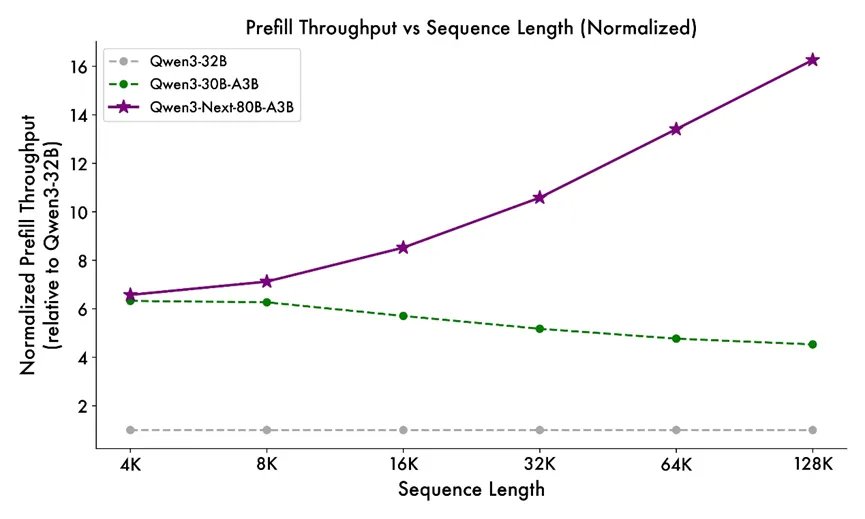
預訓練階段,Qwen3-Next展現出卓越的效率。其訓練數據來自Qwen3的36T token預訓練語料中均勻採樣的15T token子集,GPU時長不足Qwen3-30-3B的80%,計算成本僅為Qwen3-32B的9.3%,卻能實現更優性能。推理速度上,填充階段4K上下文長度時吞吐量接近Qwen3-32B的7倍,32K以上時超10倍;
解碼階段4K上下文長度時吞吐量接近Qwen3-32B的4倍,32K以上時仍保持超10倍的速度優勢。性能表現上,Qwen3-Next-80B-A3B-Base僅激活Qwen3-32B-Base非嵌入參數的1/10,卻在多數基準測試中性能更優,且顯著超過Qwen3-30B-A3B。
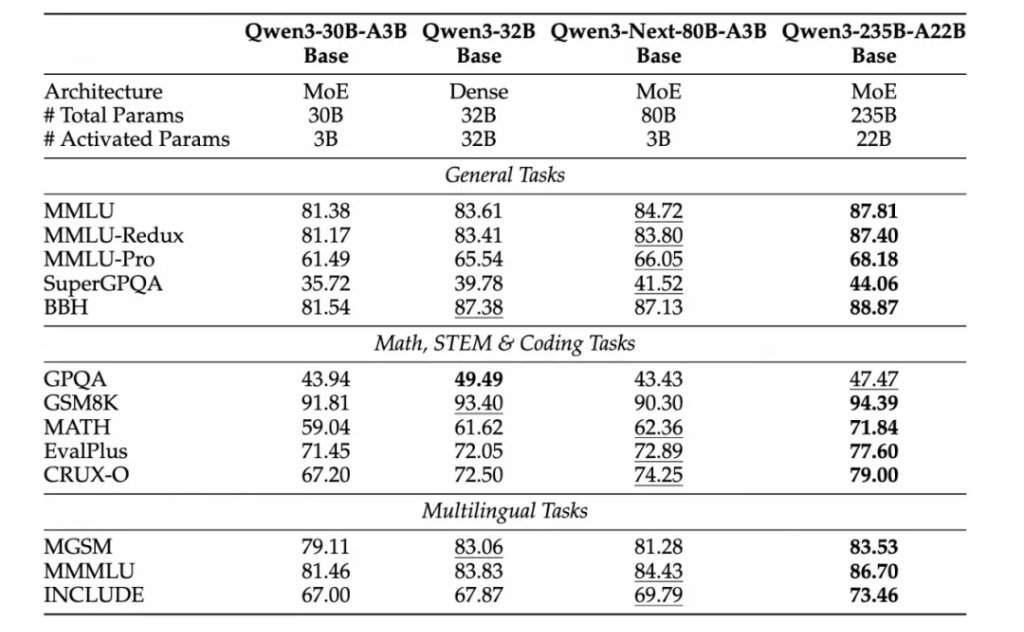
后訓練階段的性能同樣亮眼。指令模型Qwen3-Next-80B-A3B-Instruct大幅超越Qwen3-30B-A3B-Instruct-2507和Qwen3-32B-Non-thinking,性能接近旗艦模型Qwen3-235B-A22B-Instruct-2507;在RULER基準測試中,該模型在各長度下均優於注意力層更多的Qwen3-30B-A3B-Instruct-2507,且在256K上下文內擊敗總層數更多的Qwen3-235B-A22B-Instruct-2507,印證了混合架構在長上下文任務中的優勢。
推理模型Qwen3-Next-80B-A3B-Thinking性能超過Qwen3-30B-A3B-Thinking-2507、Qwen3-32B-Thinking等更高成本模型,多個基準測試擊敗Gemini-2.5-Flash-Thinking,關鍵指標接近Qwen3-235B-A22B-Thinking-2507。
風險提示: 投資涉及風險,證券價格可升亦可跌,更可變得毫無價值。投資未必一定能夠賺取利潤,反而可能會招致損失。過往業績並不代表將來的表現。在作出任何投資決定之前,投資者須評估本身的財政狀況、投資目標、經驗、承受風險的能力及瞭解有關產品之性質及風險。個別投資產品的性質及風險詳情,請細閲相關銷售文件,以瞭解更多資料。倘有任何疑問,應徵詢獨立的專業意見。
推薦文章
提價83%需求卻暴增400%!智譜、MiniMax鎖定大模型定價權,AI Agent元年即將開啟?

港股見底了嗎?北水大舉加倉逾600億港元!大行看好4月做多窗口來臨,十大金股一圖睇全
華盛早報 | 伊朗與阿曼擬共管霍爾木茲!美股V型反轉;伊朗襲擊甲骨文、亞馬遜數據中心;港美股今日因假期休市一天
諾和諾德稱:口服版Wegovy減肥效果優於禮來GLP‑1口服藥
美股機會日報 | 特朗普粉碎停戰幻想!恐慌指數飆升12%,納指期貨跌約2%;美油期貨暴漲超9%!油氣股飆升,美國原油基金ETF漲超9%
清明休市提醒 | 港股本周五休市,下周三恢復交易;美股周五休市一天
油價上漲 此前特朗普表示伊朗衝突可能在未來幾周升級
野村:特朗普講話未能發出局勢降温的明確信號
