熱門資訊> 正文
掀翻傳統推薦!OneRec端到端模型如何同時「吞噬」效果與成本雙難題
2025-06-20 14:56
AI大模型(LLM)掀起的生成式革命,正重塑各行各業,連我們每天刷到的推薦系統也不例外。
傳統推薦系統像一條多環節的「流水線」(級聯架構),容易導致算力浪費、目標衝突,制約了發展。要突破瓶頸,關鍵在於用LLM技術進行「一體化」重構,實現效果提升和成本降低。
快手技術團隊最新提出的「OneRec」系統,正是這一思路的突破。它首次用端到端的生成式AI架構,徹底改造了推薦系統的全流程,在效果和成本上實現了「既要又要」:
效果猛增:有效計算量提升10倍!讓強化學習技術在推薦場景真正「活」了起來,推薦更精準。
成本鋭減:通過架構革新,訓練和推理的算力利用率(MFU)分別飆升至23.7%和28.8%,運營成本(OPEX)僅為傳統方案的10.6%。
目前,該系統已在快手App/快手極速版雙端服務所有用户,承接約25%的QPS(每秒請求數量),帶動App停留時長提升0.54%/1.24%,關鍵指標7日用户生命周期(LT7)顯著增長,為推薦系統從傳統Pipeline邁向端到端生成式架構提供了首個工業級可行方案。
完整技術報告鏈接:https://arxiv.org/abs/2506.13695
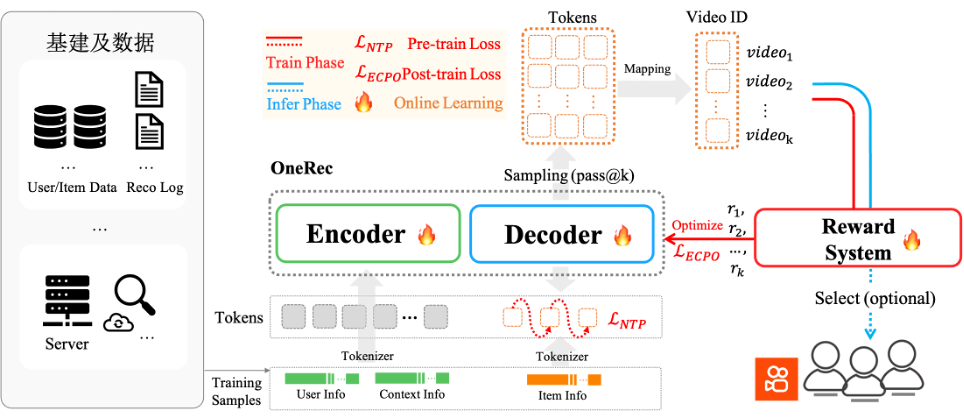
OneRec基礎模型剖析
OneRec採用端到端生成式架構,首創協同感知多模態分詞器:通過融合視頻標題、圖像等多維信息與用户行為,利用RQ-Kmeans分層生成語義ID。其Encoder-Decoder框架將推薦轉化為序列生成任務:
Encoder整合用户終身/短期行為序列實現多尺度建模;
MoE增強的Decoder通過Next Token Prediction精準生成推薦結果。
實驗驗證其遵循Scaling Law——參數量增至2.633B時訓練損失顯著下降,結合特徵/碼本/推理級優化,實現效果與算力的協同突破。
強化學習(RL)偏好對齊
OneRec突破傳統推薦依賴歷史曝光的侷限,創新引入強化學習偏好對齊機制。通過融合偏好獎勵(用户偏好)、格式獎勵(有效輸出)及業務獎勵(工業需求)構建綜合獎勵系統,並利用個性化P-Score作為強化信號。採用改進的ECPO算法(嚴格截斷負優勢梯度)提升訓練穩定性,在快手場景中實現不損失曝光量前提下顯著提升用户時長,達成工業級效果突破。
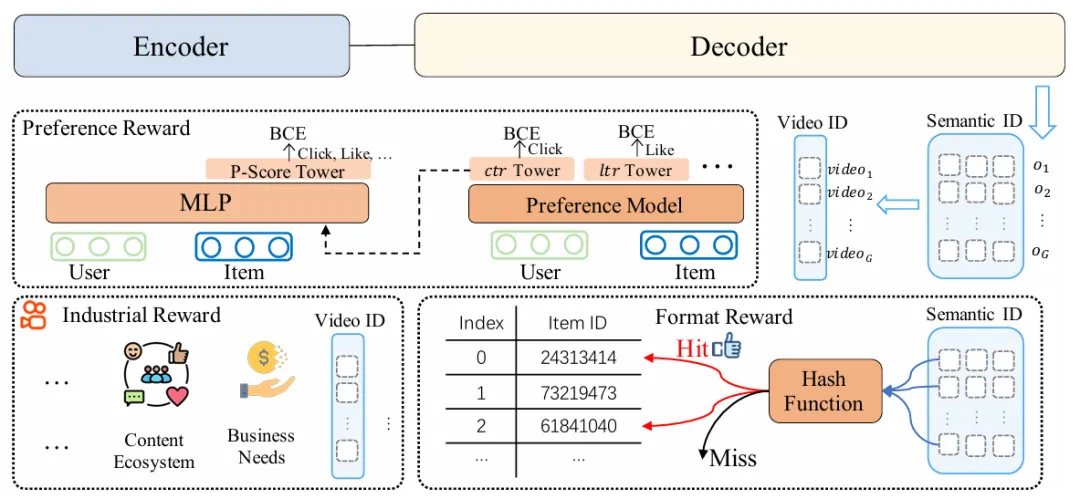
性能優化
在性能優化上,OneRec突破傳統推薦MFU個位數魔咒:通過架構重構+算子壓縮92%至1,200個,訓練/推理MFU提升至23.7%/28.6%,算力效能達主流AI模型水平,實現3~5倍躍升。首次讓推薦系統達到與主流AI模型比肩的算力效能水平。
此外,快手技術團隊還針對OneRec特性在訓練和推理框架層面進行了深度定製優化。訓練側採用請求分組特徵複用與變長Flash Attention提升計算密度,自研SKAI系統實現Embedding全流程GPU訓練,徹底消除CPU同步瓶頸;推理側首創計算複用架構——Encoder單次前向+Beam間KV共享+Decoder層KV Cache,支撐512大Beam Size生成需求,並基於Float16混合精度與MoE/Attention算子深度融合提升吞吐。最終訓練/推理MFU達23.7%/28.8%(較傳統模型提升3~5倍),運營成本降至傳統方案10.6%,實現近90%成本節約。
Online實驗效果
該模型經過一周5%流量AB測試,在點贊、關注、評論等所有交互指標上均獲正向收益(如下圖)。系統現已全量覆蓋短視頻推薦主場景,承擔約25%QPS。除了短視頻推薦的消費場景之外,OneRec在快手本地生活服務場景同樣表現驚艷:AB對比實驗表明該方案推動GMV暴漲21.01%、訂單量提升17.89%、購買用户數增長18.58%,其中新客獲取效率更實現23.02%的顯著提升。目前,該業務線已實現100%流量全量切換。
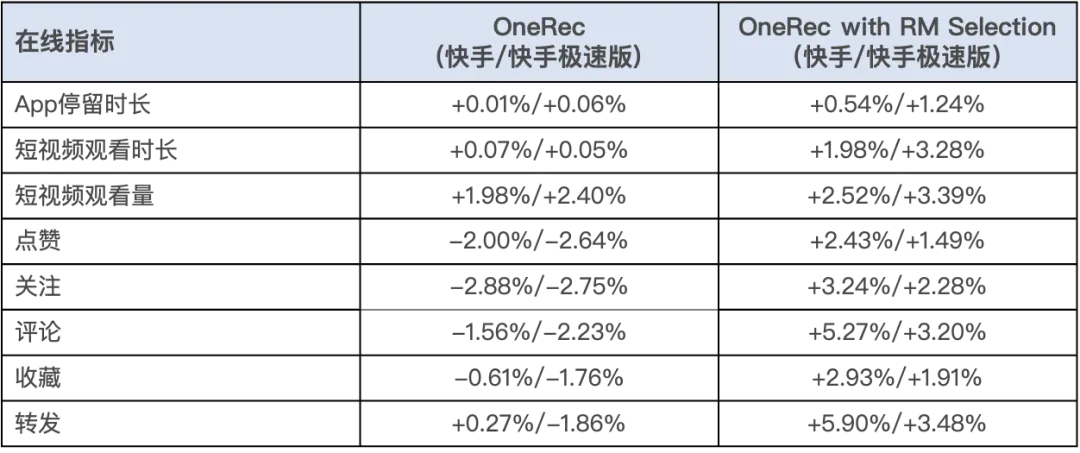
生成式AI方興未艾,正引發各領域根本性技術變革與降本增效。OneRec不僅論證了推薦系統與LLM技術棧深度融合的必要性,更重構了互聯網核心基礎設施的技術DNA。隨着其新範式的到來,推薦系統將加速迎來「端到端生成式覺醒」時刻。
推薦文章
港股周報丨三家外賣平臺被約談!「瘋狂星期六」或不再瘋狂;花旗呼籲增持中國互聯網、科技及消費板塊

美股機會日報 | 特朗普放大招!9萬億養老金即將殺入加密市場;美聯儲主席候選人支持7月降息
一周財經日曆 | 特斯拉、谷歌財報重磅來襲!維立志博將於下周五登陸港交所
一圖看懂 | 港股上半年IPO募資額登頂全球!中籤就賺一萬港幣的「大肉籤」你參與了嗎?
黃仁勛年內三度訪華!H20重返中國市場,釋放了什麼信號?
創新葯行情徹底爆發!維立志博-B打新半日孖展超購130倍,凍資近150億港元
新股申購 | 維立志博-B入場費3535.30港元!引入騰訊、易方達等基石投資者
7月財報預告丨迎關税考驗!特斯拉、臺積電放榜在即,美股能否守住漲勢?
