熱門資訊> 正文
中金:DeepSeek技術破局,成本下探引領應用百花齊放
2025-02-11 08:52
- 蘋果(AAPL) 0
- 英偉達(NVDA) 0
- 中金公司(03908.HK) 0
本文來自格隆匯專欄:中金研究 作者: 於鍾海 魏鸛霏等
DeepSeek於2025年1月末全球範圍內出圈,APP端DAU達2,215萬,在AI產品日活總榜中僅次於ChatGPT,在157個國家地區的蘋果應用商店下載量排名第一。中金研究認為,DeepSeek出圈背后的技術創新、工程能力突出,引領全球技術趨勢,其降本成果對於端雲應用的鋪墊作用具備重要意義,建議2025年關注國內模型性能優化背景下的應用層投資機遇。
摘要
DeepSeek V3通過技術創新與工程優化,實現了領先的性價比。其採用自主研發的MoE架構,總參數量達671B,每個token激活37B參數,多維度對標GPT-4o。技術突破包括稀疏專家模型MoE、多頭注意力機制MLA和創新訓練目標MTP,顯著提升推理效率。此外,FP8混合精度訓練策略首次大規模應用,兼顧穩定性和性價比,訓練成本僅為557萬美元,耗時不到兩個月。V3的API定價低至百萬輸入tokens 0.5元,大幅降低使用成本,中金研究認為有望推動大模型應用端廣泛普及。
DeepSeek R1系列通過強化學習(RL)實現了推理能力邊際突破。R1 Zero跳過了傳統的大規模監督微調(SFT)環節,直接通過強化學習訓練基礎模型,達到比肩OpenAI o1的能力,驗證了RL在大語言模型中的應用潛力。R1在R1 zero的基礎上進一步優化算法,解決了語言一致性等問題。通過底層優化了Nvidia的PTX指令集,R1系列提高了跨平臺兼容性,併爲國產芯片適配提供了可能。R1的高效推理和低成本使其在產業應用中潛力釋放,中金研究認為有望進一步推動AI應用的普及與規模化。
DeepSeek Janus-Pro模型在圖像理解和生成方面表現出色,實現架構統一。Janus-Pro通過兩個編碼器分別負責圖像理解和生成,共享一個Transformer網絡,並採用了三階段訓練優化以提高模型對真實場景的適應能力,模型效果優於Dalle 3等海外成果。
中金研究認為Deepseek將帶來三方面產業影響。1)數據從「規模驅動」向「質量優先」轉變;2)蒸餾技術帶動輕量化模型滿足高性能、高效率,使大規模端側部署更進一步;3)國內外大廠追隨,有望迎來技術平權,工程化能力和生態系統建設仍是企業構建競爭壁壘的關鍵要素。
風險
技術迭代不及預期,下游商業化不及預期。
正文
DeepSeek V3:技術創新+工程優化,實現極致性價比
DeepSeek通過MoE與MLA算法創新,V3性能對標GPT-4o。DeepSeek-V3採用自主研發的MoE架構,總參數量達到671B,其中每個token會激活37B個參數,並在14.8Ttokens上進行預訓練,最終實現多維度對標GPT-4o的能力。其技術突破體現在:
1)稀疏專家模型 MoE:延續DeepSeek-V2的路徑,拓展至256個路由專家+1個共享專家,每個token激活8個路由專家、最多被發送到4個節點。DeepSeek V3還引入了冗余專家(redundant experts)的部署策略,即複製高負載專家並冗余部署。這主要是爲了在推理階段,實現MoE不同專家之間的負載均衡。DeepSeek-V3在DeepSeek-V2架構的基礎上,提出了一種無輔助損失的負載均衡策略,能最大限度減少負載均衡而導致的性能下降,為MoE中的每個專家引入了一個偏置項(bias term),並將其添加到相應的親和度分數中,以確定top-K路由。
2)多頭注意力機制 MLA:圍繞推理階段的顯存、帶寬和計算效率展開。通過創新底層軟件架構,引入數學變換減少kv cache內存佔用,緩解transformer推理時的顯存和帶寬瓶頸。MLA核心思想是藉助低秩分解(LoRA)將大投影矩陣分解為wkv_a和wkv_b兩個線性層來代替一個大的Key/Value投影矩陣,wkv_a把輸入投影到低維空間,wkv_b再投影回原始維度,同時,RoPE通過旋轉Query和Key向量為其添加位置信息。而DeepSeek-V3的MLA包含一種優化的注意力計算方式,即將wkv_b的部分計算融入到注意力分數計算中,減少了后續的矩陣乘法操作,進一步提高了效率。
3)創新訓練目標:採用MTP(Multi-token prediction)提升模型性能,實現推理加速。MTP的核心思想是讓模型在訓練時一次性預測多個未來令牌,而非傳統的僅預測下一個令牌。這一設計通過擴展模型的預測範圍,增強對上下文的理解能力,並優化訓練信號的密度。
圖表1:V3採用MTP一次預測多個令牌,計算交叉熵損失,由主模型進行快速驗證,將推理速度提升1.8倍
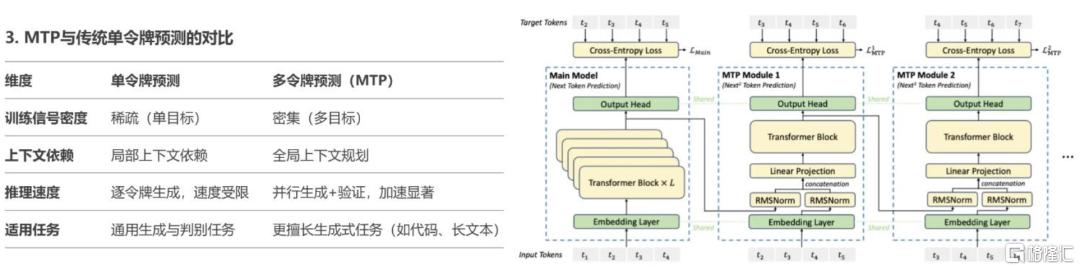
資料來源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
創新性大範圍落地FP8+混合精度策略,兼顧模型穩定性和性價比。預訓練方面,DeepSeek V3採用FP8訓練。計算精度從過去主流的FP16降到FP8,保留了混合精度策略,在重要算子模塊還保留了FP16/32來保證準確度和收斂性;對於FP8的採用和大量工程化創新,能夠兼顧模型穩定性和降低算力成本。在解決通信瓶頸問題上,DeepSeek V3採用DualPipe高效流水線並行算法(單前向后向塊對內,重疊計算和通信),只要保持計算通信比率恆定,可以跨節點使用專家門控,實現接近於0的通信開銷。后訓練部分,用長思維鏈模型(R1)蒸餾給V3模型,再進行反哺,保持V3輸出風格一致性。
圖表2:V3採用FP8混合精度訓練框架,首次驗證FP8在大模型訓練中的可行性

資料來源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
「性價比」為應用廣泛拓展的核心要素。DeepSeek-V3訓練成本僅為557萬美元,遠低於海外模型。單次訓練成本557萬美元,耗時低於兩個月。2024年中,DeepSeek-V2率先掀起國內的大模型價格競爭,率先將推理成本推動到每百萬tokens 1元(下降99%),約等於Llama3 70B的七分之一,GPT-4 Turbo的七十分之一[1],隨后阿里、字節開始追隨降價。高性能配合極致推理性價比,隨着性能更強的DeepSeek-V3更新上線,模型API服務定價也將調整為每百萬輸入tokens 0.5元(緩存命中)/2元(緩存未命中),每百萬輸出tokens 8元,程序員月均使用成本可控制在10元左右,大幅降低使用成本。
圖表3:DeepSeek-V3訓練成本557萬美元,耗時<2個月

資料來源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
圖表4:DeepSeek-V3進入最佳性價比三角,以2%成本對標Claude 3.5 Sonnet性能
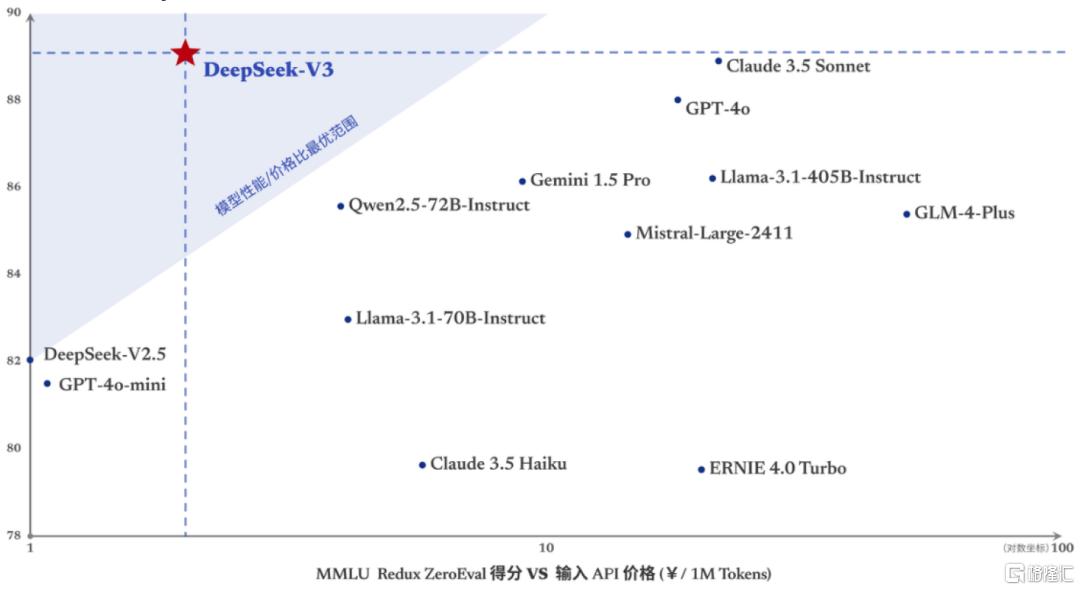
資料來源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
DeepSeek R1 Zero及R1:強化學習打開推理天花板
技術原理:R1 Zero強化學習主導,R1進行SFT與RL融合優化
DeepSeek R1 Zero和R1出圈,R1 Zero具備對標AlphaZero的重要意義。DeepSeek APP於2025年1月11日發佈,截至1月31日DAU達2,215萬,達ChatGPT DAU的41.6%,超過豆包DAU 1,695萬。截至2025年1月,ChatGPT、DeepSeek、豆包排名全球AI產品日活總榜TOP3,DeepSeek霸榜蘋果應用商店157個國家地區的第一名(含美國)。DeepSeek MAU達到3,370萬,1月末中國MAU佔比30%,印度等多國家實現快速滲透[2]。中金研究認為,技術視角具備重要意義的是R1 Zero對於強化學習(RL)在訓練側的大範圍採用,即無需人類監督的SFT,藉助RL打開推理能力天花板,與AlphaZero在圍棋領域僅憑自對弈強化學習取得的成果相呼應。
圖表5:DeepSeek上線21天,DAU達2,215萬,排名全球AI產品榜第二名,霸榜157國家和地區蘋果應用商店
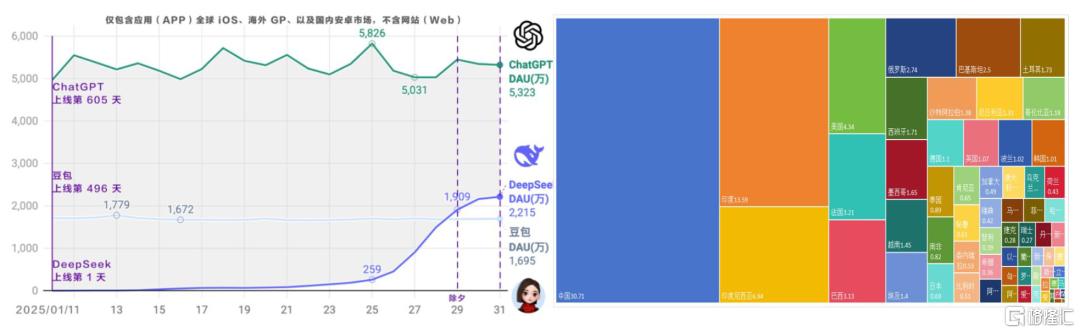
注:右圖單位為百分比(%),為截至2025年1月31日DeepSeek APP MAU按國家佔比 資料來源:AI產品榜 aicpb.com,中金公司研究部
技術覆盤:回顧早期強化學習到ChatGPT到o1的發展歷程,2017年5月,AlphaGo創新性地採用兩階段訓練範式,即先基於人類棋譜預訓練神經網絡,繼而通過自我對弈強化學習實現能力躍升,最終以3:0戰勝圍棋世界冠軍柯潔。隨后DeepMind推出的AlphaZero實現範式突破,完全依賴自我對弈強化學習即超越前代系統,標誌着強化學習技術首次實現突破性進展。至2022年末,ChatGPT通過基於人類反饋的強化學習(RLHF)機制顯著提升對話交互能力。2024年OpenAI推出的o1模型開創性引入「AI自主評分」訓練範式,弱化人類監督,運用強化學習優化思維鏈生成,實現類人類慢思考機制,大幅降低對人類反饋的依賴。2025年DeepSeek發佈的推理模型R1-Zero,通過完全消除監督式微調過程(SFT)、僅憑強化學習即達到與o1相當的智能水平,向AlphaZero技術路線致敬,更推動強化學習技術迎來第二次重大突破。
圖表6:R1-Zero相比o1的突破,可以類比於AlphaZero相較AlphaGo的強化學習突破

資料來源:豆包,公司官網,中金公司研究部
傳統大模型訓練經歷SFT-RLHF環節,R1 Zero繞過SFT環節,剔除人類監督,進行算法顛覆式創新。在大語言模型的訓練中,SFT通常被認為是必要環節,先用大量人工標註的數據來讓模型初步掌握某種能力,然后再利用人類反饋的強化學習(RLHF)來進一步優化模型的性能。R1-Zero選擇將 RL直接應用於基礎模型(DeepSeek-V3-Base),而沒有經過任何形式的SFT預訓練,節約標註成本,不被預先設定的模式所束縛,推理能力突破,具備強大泛化能力和適應性。R1-Zero證實了純強化學習的有效性,彰顯RL潛力。在AIME 2024上,R1-Zero的pass@1指標從15.6%提升至71.0%,經過投票策略(majority voting)后更是提升到了86.7%,與 OpenAI-o1-0912 相當。
圖表7:採用羣組相對策略優化GRPO算法,R1在數學、代碼等任務上比肩 OpenAI o1
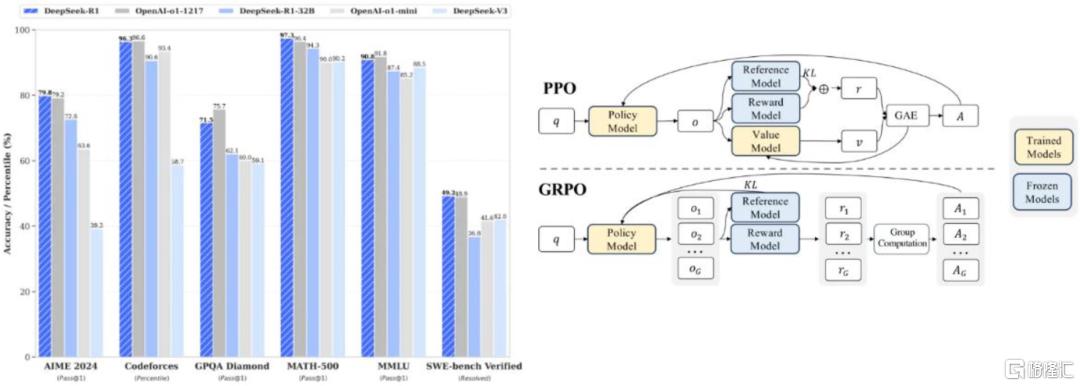
資料來源:DeepSeek R1 Technical Report https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf,DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models https://arxiv.org/pdf/2402.03300,中金公司研究部
R1-Zero強推理能力下仍具備語言不一致等問題,R1則以多階段訓練、Cold start的方式解決落地短板。R1則通過「SFT—RL—SFT—RL」過程進一步優化算法,提升產品使用體驗。1)SFT 冷啟動:基於高質量CoT數據對V3模型進行首次監督微調,給模型打個底,解決語言不一致問題,有助於加速收斂;2)RL 強化學習訓練,進一步提升推理能力並引入語言一致性優化;3)SFT 為適應更廣泛的非推理任務,構建特定數據集對模型進行二次監督微調,優化其在文本等通用場景下的表現;4)RL 通過混合獎勵模型(reward model)進行強化學習,在提升語言流暢度和一致性的同時,平衡推理能力與實用需求,確保模型在實際應用中的穩定性和可用性,平衡推理能力和實用需求。
圖表8:基於基座模型V3,R1 Zero僅基於強化學習RL,R1則融合SFT和RL進行優化
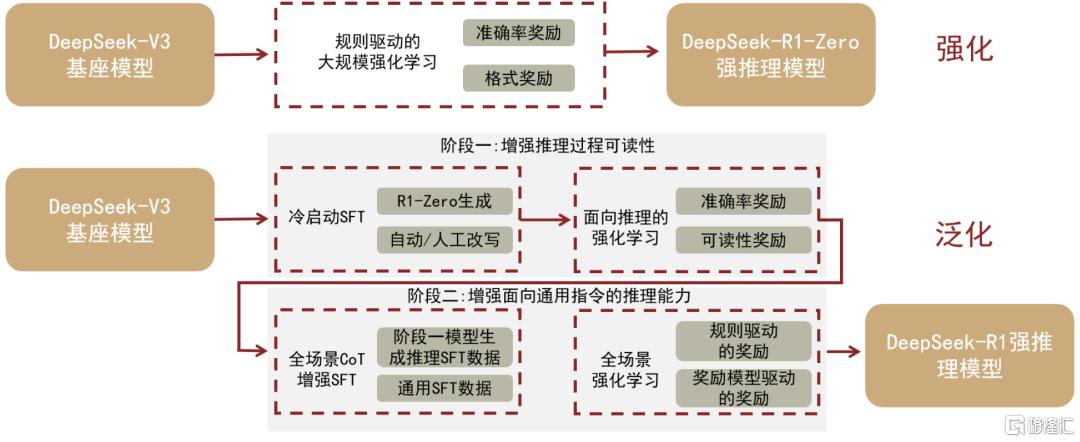
資料來源:DeepSeek R1 Technical Report https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf,中金公司研究部
硬件層面優化,本質沒有繞開CUDA生態,跨平臺兼容性帶來國產機遇。DeepSeek底層優化了Nvidia的PTX(Parallel Thread Execution)指令集,本質上沒有繞開CUDA生態。相比於直接調用CUDA生態,DeepSeek進行更為精細的硬件層面優化,直接編寫PTX代碼,得以實現計算效率大幅提升。例如,DeepSeek在H800 GPU上將132個流處理器中的20個專門用於服務器間的通信任務,提升了數據傳輸效率。「繞開CUDA生態」表述實則意味着跨平臺兼容性。DeepSeek直接使用PTX,本質上是對Nvidia CUDA生態的粘性,但其技術可以適配其他GPU平臺,如AMD和華為昇騰,展示了其技術的跨平臺兼容性。R1的MoE架構和FP8精度未來或推動ASIC芯片適配。
圖表9:DeepSeek在硬件層面優化,直接編寫PTX代碼,本質上沒有繞開Nvidia CUDA生態
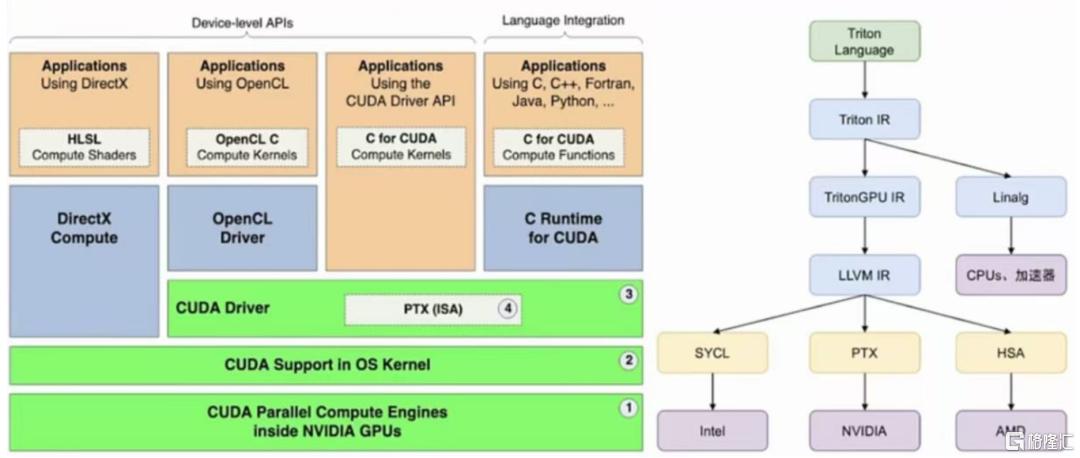
資料來源:https://developer.download.nvidia.com/compute/cuda/docs/CUDA_Architecture_Overview.pdf,中金公司研究部
產業影響:數據重質少量,R1蒸餾思路帶動端雲應用規模化落地
性能突出,模型開源,DeepSeek-R1持續破圈。採用預填充與推理分離架構,通過計算與通信過程重疊設計,DeepSeek-R1全面適配國產芯片,推理效率達到英偉達A100的92%[3],超越行業平均65%。FP8混合精度技術使顯存佔用大幅減少,精度損失控制在0.25%以內[4],兼顧效率與性能。R1系列通過MIT許可證開源模型權重及蒸餾技術,蒸餾小模型性能超越OpenAI o1-mini,吸引全球開發者學習和適配,將進一步推動AI應用增長。
R1訓練及推理成本進一步優化,核心要素從性能向成本過渡。DeepSeek-R1在有限算力下做出對標o1能力的模型,R1-zero使用671B總參數,每個token僅激活37B參數,從而實現輕量化調用。DeepSeek-R1 API服務定價為每百萬輸入tokens 1元(緩存命中)/4元(緩存未命中),每百萬輸出tokens 16元,調用價格是OpenAI o1的1-5%。
大模型密度定律認為,大模型的效率提升具備規律。中金研究認為應用層的PMF探索和成本下探趨勢下有望百花齊放。面壁智能創始人、清華大學長聘副教授劉知遠團隊提出大模型的「密度定律」,2023年以來大模型能力密度每3.3個月翻一倍,也就是達到對標最高水平需要的參數量、算力減半,預示着訓練成本在現有基礎上仍具備持續下探潛力。中金研究認為,企業級應用、通用及垂類C端應用、手機汽車等端側部署場景均有望受益於大模型輕量化的效率提升紅利。
圖表10:面壁智能大模型密度定律:每3.3個月,達到領先模型性能所需的參數量、算力需求減半

資料來源:Xiao,C. et al. Densing Law of LLMs. arXiv preprint arXiv:2412.04315v2,中金公司研究部
基於以上探討,中金研究認為DeepSeek-R1產業影響體現在三個方面:
1)國內外大廠追隨,有望迎來技術再次平權,工程化能力和生態系統建設仍然是企業構建競爭壁壘的關鍵要素。在海外,ChatGPT-o3mini、Deep Research以及Google提出的Gemini Flash Thinking等成果亮眼,也具備追隨價值。在國內,字節跳動、阿里巴巴等公司在FP8等混合精度量化技術、混合專家模型(MoE)架構以及強化學習訓練方法等方面也已具備相應的技術儲備,產業鏈值得密切追蹤,行業範圍內應用層均有望受益於模型平權、降本。
2)蒸餾成為廣泛部署R1能力中小型模型的思路,端側AI規模化值得關注。知識蒸餾已成為將大型模型的能力遷移至參數規模更小的模型,從而實現廣泛部署的有效策略。例如,DeepSeek-R1可以作為教師模型,用於蒸餾Qwen14B等模型。目前,基於蒸餾技術的模型已經覆蓋了1B到70B的參數範圍[5]。玩具、耳機等端側硬件有望在小模型賦能下迎來新機遇。
3)數據需求,重質少量:與傳統監督學習範式不同,RL訓練更側重於高質量、具備複雜推理鏈的數據,例如圍棋的專家棋譜、數學定理證明過程以及代碼規範等,這些數據能夠有效引導模型學習策略性決策和邏輯推理能力。而大量日常對話數據對於底層模型優化貢獻有限,甚至可能引入噪聲,降低訓練效率。
DeepSeek Janus-Pro:多模態理解及生成能力超過Dalle 3等模型
Janus-Pro一共包含兩個參數模型,分別為1.5B和7B。Janus-Pro 7B在理解和生成兩方面都超越了LLaVA、Dalle 3等模型。在多模態理解基準MMBench上,它獲得了79.2分的成績,超越了此前的最佳水平,包括Janus(69.4分)、TokenFlow(68.9分)和MetaMorph(75.2分)。在圖像生成評測上,Janus-Pro-7B在GenEval基準測試中達到0.80分,大幅領先於DALL-E 3(0.67分)和Stable Diffusion 3 Medium(0.74分)。
圖表11:Janus-Pro 7B在理解和生成兩方面都超越了LLaVA、Dalle 3等主流模型
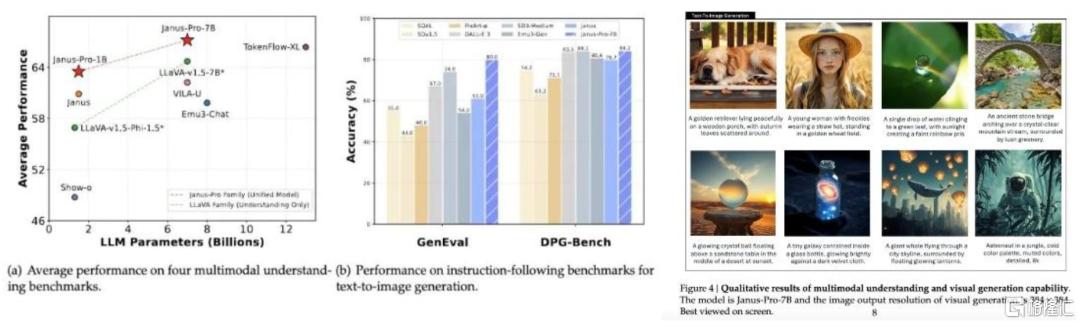
資料來源:DeepSeek Janus-Pro Technical Report https://arxiv.org/pdf/2410.13848 ,中金公司研究部
Janus Pro為模型配置兩個編碼器共用一個Transformer網絡,實現圖像生成和理解大一統,符合人腦第一性原理:技術報告中思路與MetaMorph項目(楊立昆和謝賽寧主導)類似,放棄編碼器統一,轉而採用專門化方案。具體而言,SigLIP編碼器負責提取圖像的高層語義特徵,負責圖像理解;VQ編碼器負責圖像轉化為離散的token序列,用於生成創作,兩個編碼器共用一個Transformer網絡。
圖表12:Janus-Pro 架構中兩個編碼器分別負責圖像理解、生成,共用一個transformer
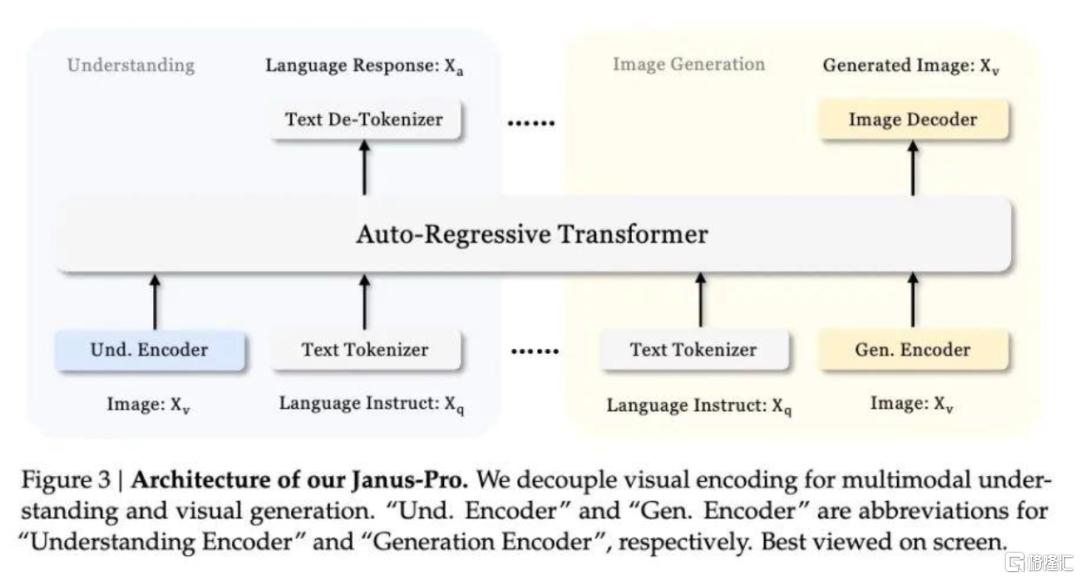
資料來源:DeepSeek Janus-Pro Technical Report https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf ,中金公司研究部
多模態統一的概念最早由Google於2023年12月提出,Gemini為代表作,商湯等廠商已採用類似路徑。核心在於基於Transformer架構,將文本、圖像、音頻、視頻等多種模態的數據進行統一處理,實現跨模態的理解與生成,實現縮短時延、保留多模態信息完整性的效果。
Janus分為三階段訓練流程,Janus pro在其三階段都有進一步優化。階段一:鎖定LLM參數,僅通過訓練適配器,模型即可掌握複雜的像素依賴關係。Janus pro延長了階段一的訓練時間至25-30%。階段二:放棄ImageNet訓練,僅使用真實的文本到圖像數據進行訓練,使訓練時間減少40%、生成質量提升35%、模型對真實場景的適應性大幅提升。階段三:在統一預訓練的基礎上進一步微調模型,這一步Janus的數據混合比例是傳統的多模態數據、純文本數據和文本到圖像數據為 7:3:10,Janus Pro創新出更優的配比方案5:1:4,並且創新性引入合成美學數據,和真實數據配比1:1,提升輸出圖像質量。
投資建議:關注雲廠商、AIDC及AI應用投資機遇
主線一:低成本、高性能模型降低用户使用門檻,疊加國產算力適配背景,雲CSP、AIDC迎來利好
雲CSP方面,中金研究認為1)雲資源消耗量有望提升:Deepseek-R1等模型,因其低成本、高性能的特性,降低了用户接入AI技術的門檻,開發者通過雲服務商部署模型、開發應用,有利於應用繁榮、拉動雲資源消耗量;2)國產智算資源利用率有望提升:當前華為雲、騰訊雲、阿里雲、百度雲、移動雲、天翼雲、聯通雲等均已經宣佈支持部署DeepSeek模型,華為雲指出「憑藉其自研的推理加速引擎,雙方合作部署的DeepSeek模型能夠達到與全球高端GPU部署模型相媲美的效果」[6],中金研究認為國內雲廠商此前佈局的國產智算資源利用率或有提升;3)算力需求從訓練向推理轉化,可能帶來雲廠商市場格局演進:當下,能夠進行高性能訓練計算的雲廠商佔據領先地位,隨訓練需求繼續向推理演進,部分雲廠商或可專注於推理服務創造差異化競爭力。國內雲廠商或迎來重估機會。
國產算力方面,受益於訓練向推理的需求遷移,國產算力適配確定性依然較強,DeepSeek出圈會推動整個國產AI使用度的普及和用量提升,且近期華為昇騰適配積極。
AIDC方面,1)雲廠商資本開支提升、第三方數據中心需求提振:過去第三方IDC需求主要來自於傳統雲計算、短視頻等需求,2024年以來國內雲廠商資本開支提升,人工智能帶來增量需求驅動數據中心訂單增長,此外,多家國產AI算力廠商宣佈適配DeepSeek,一定程度上緩解了此前因芯片受限而帶來的市場對雲廠商未來資本開支不及預期的擔憂;2)板塊估值具有提升空間:板塊估值經歷近四年調整后,估值處於歷史相對低位;3)核心第三方數據中心具估值彈性:服務頭部AI廠商、具備快速交付的優質工程能力,並且能夠匹配客户訓練、推理不同場景需求的數據中心廠商有望獲得更大彈性。
主線二:推理成本持續下探,AI應用有望百花齊放
中金研究認為DeepSeek R1作為高性價比的開源推理模型,能夠加速o1性能模型的規模化應用落地,提升AI應用在供給端模型能力的上限。2023-24年基於GPT-4級別的應用沒有達到市場的預期,而R1給予工具類應用和Agent應用更多的可能性。
注:本文摘自中金研究2025年2月9日已經發布的《AI智道(2):DeepSeek技術破局,成本下探引領應用百花齊放》,分析師:於鍾海 S0080518070011;魏鸛霏 S0080523060019;王之昊 S0080522050001;趙麗萍 S0080516060004;車姝韻 S0080523050005;王倩蕾 S0080524100004;童思藝 S0080524060015;李銘姌 S0080524070025
推薦文章
美股機會日報 | 估值8500億美元!傳OpenAI最新融資規模將破千億美元;黃仁勛稱將發佈幾款世界前所未見的新芯片

美股機會日報 | 凌晨3點!美聯儲將公佈1月貨幣政策會議紀要,納指期貨漲近0.5%;13F大曝光!巴菲特連續三季減持蘋果
美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產
港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
