熱門資訊> 正文
一個月連發五個模型,谷歌追趕OpenAI的樣子讓人心疼
2024-02-29 10:52
以下文章來源於新硅NewGeek ,作者劉白
要説AI圈的勞模,那非得谷歌莫屬。
這一個月,谷歌硬是整了五個新模型。
但好笑的是,作為美國最大的科技公司之一,谷歌幾乎每次想搞個大新聞,最后都光速打臉塌房。

先看看這一大片「G」開頭的模型,硅基君在選題會上聊這些東西,舌頭都在打架。
本來還以為是咱英文水平不行,沒想到谷歌自家的員工也在吐槽。

谷歌Gemini家族產品名的難記程度不亞於美國網紅家族卡戴珊
這一個月瘋狂發模型可算是逼急了谷歌員工,加班在一線的他們忍不住給Business Insider報了個大料——
僅供內部傳閲的表情包。
比如吐槽亂七八糟的產品太多的:

咱有哪位副總的OKR是用產品名稱數量來考覈的嗎?

上一次發佈AI模型的時間:0天前
又比如吐槽管理層想靠着AI拉股價的:

焦急等待谷歌的股價在某次新品發佈后上漲
頭疼的幾種類型:偏頭疼、高血壓、壓力、試圖理解我們的AI模型策略
二月的谷歌確實陷入了一種近乎內耗的狀態,咱們簡單回顧一下這一大堆陌生詞匯。
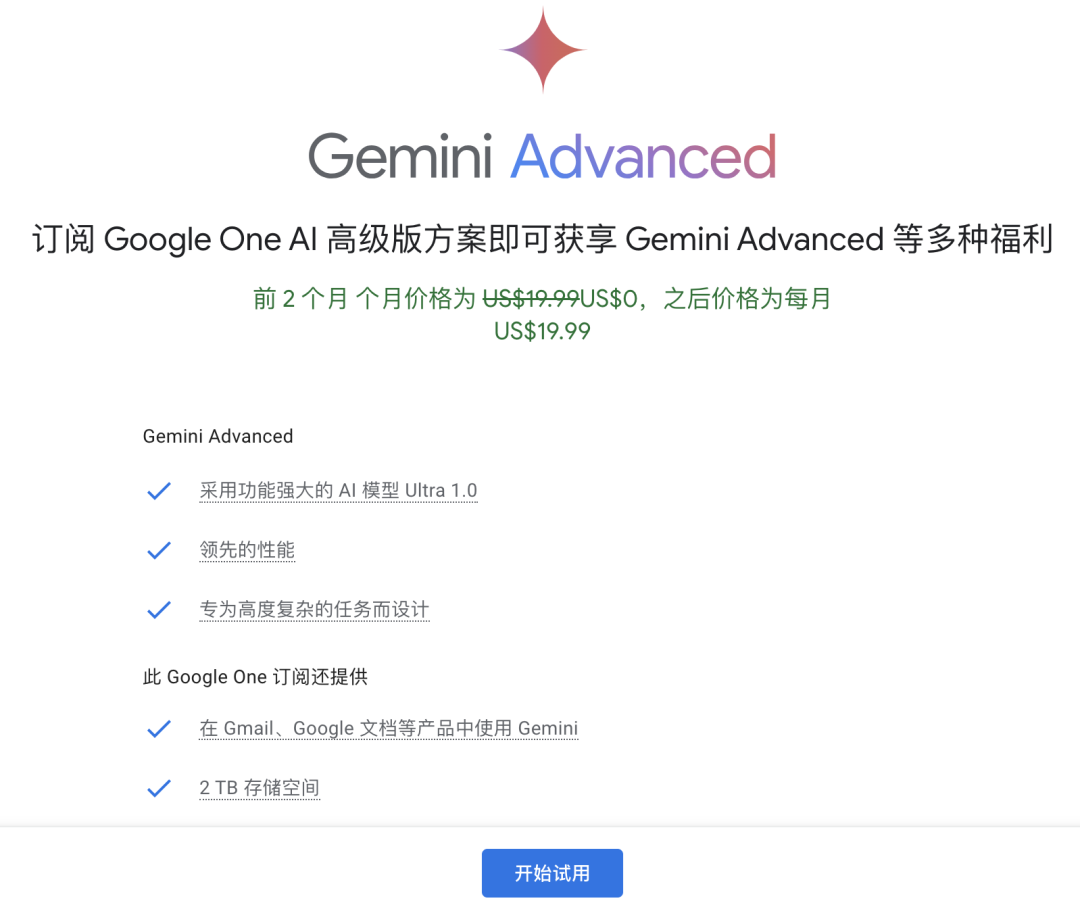
首先,二月初Gemini先是上線了千呼萬喚始出來的文生圖功能,然后提供了Gemini 1.0 Ultra付費使用計劃。
這個付費計劃叫做Gemini Advanced,但是你要訂閲了Google One AI高級版方案,纔可以用得上Gemini Ultra 1.0模型。
用户一臉懵逼:我訂閲的到底是什麼東西?
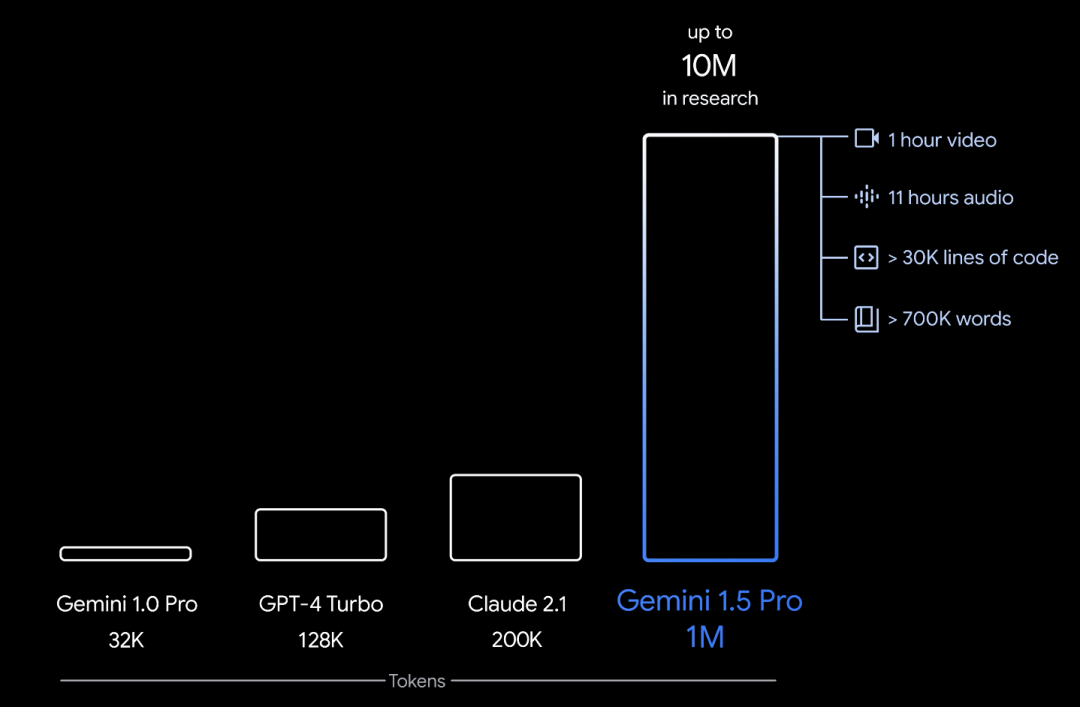
然后在15號又放了一個大招,發佈Gemini 1.5 Pro版本,可支持100萬token上下文處理。
遙遙領先GPT-4 Turbo和Claude 2.1十萬級token的上下文長度。
不僅能一口氣解析長達402頁的阿波羅登月任務文檔。
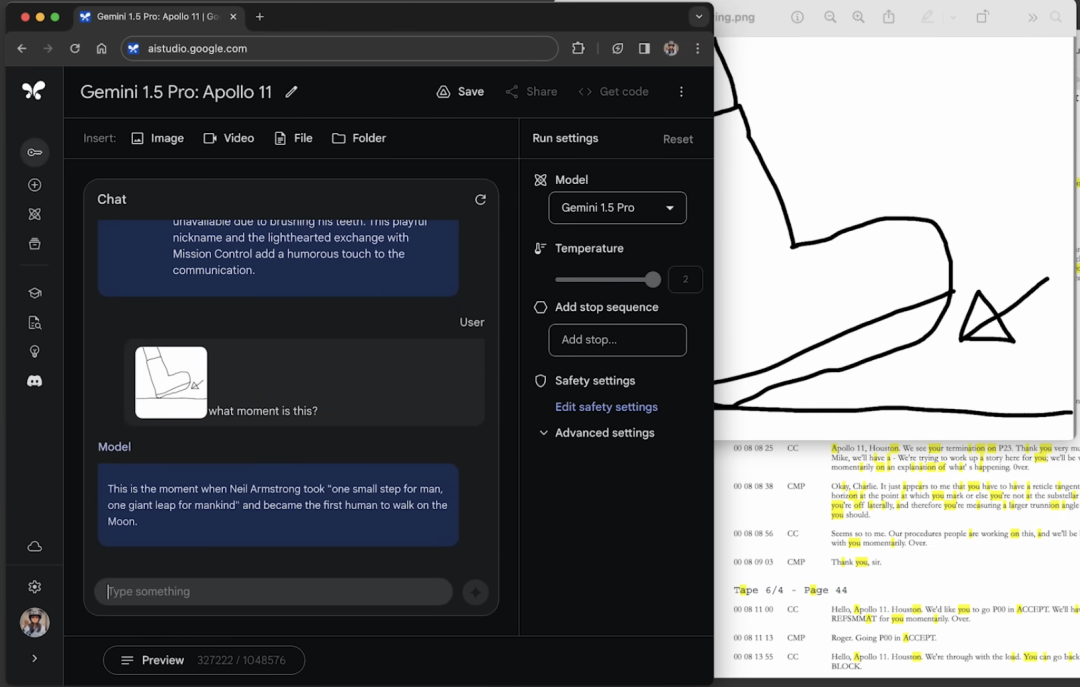
丟一張靈魂畫圖問這是什麼?Gemini 1.5 Pro回答:這是尼爾·阿姆斯特朗在月球上邁出第一步時説的「這是個人的一小步,卻是人類的一大步」
還可以看得懂一部44分鍾的巴斯特基頓的默片。
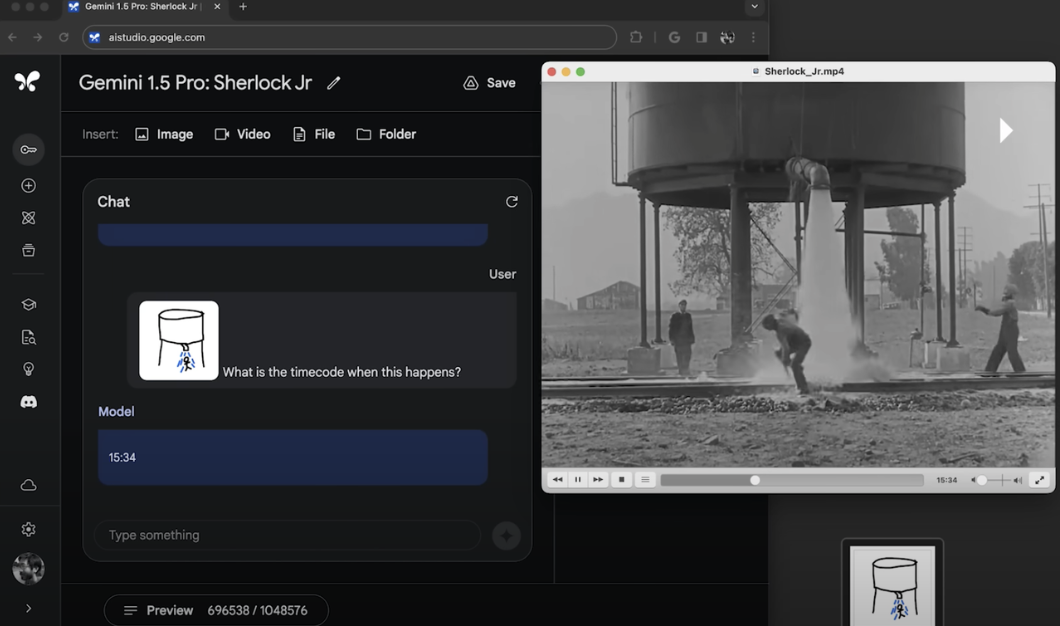
再丟一張靈魂畫圖問這一幕發生在影片里什麼時刻?Gemini 1.5 Pro回答:15:34進度條拉到15分34秒,確實對上了
照理説這麼亮眼的成績至少可以讓大家在茶余飯后談個幾天的。
但是天有不測風雲,同一天Open AI王炸視頻生成模型Sora橫空出世。
有視頻生成誰還在意你的超長上下文處理呢,谷歌的這個大招沒濺起一點水花。
接着越挫越勇的谷歌又在21號發佈了「全球最強開源大模型」Gemma,意圖在開源領域打擊Meta的Llama。
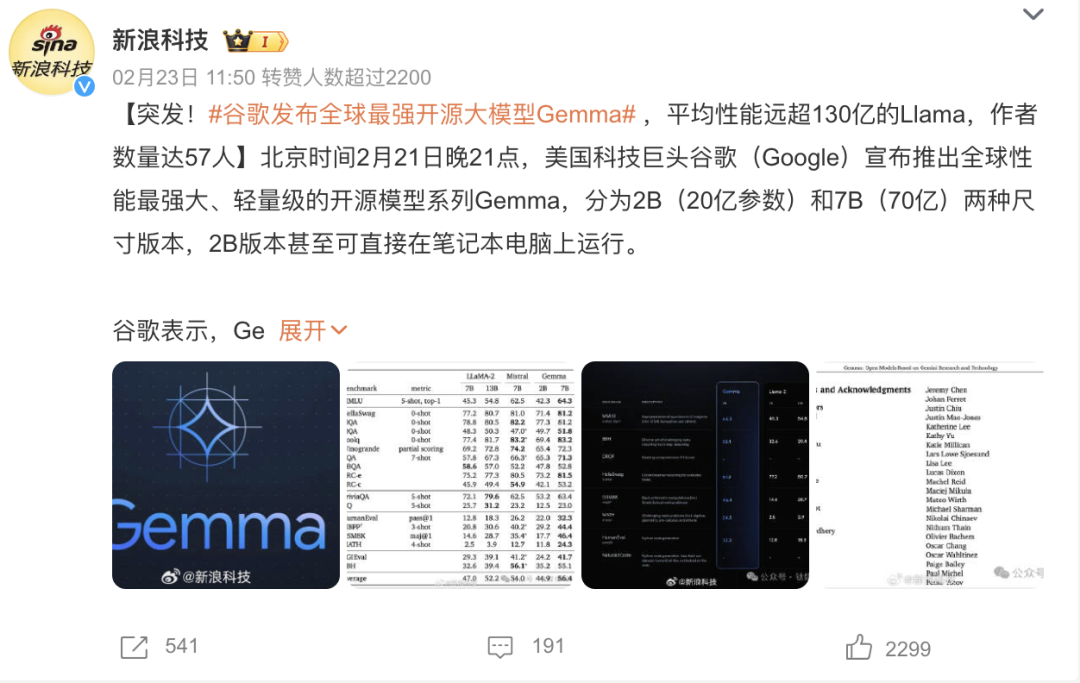
來源:微博
官方測試中Gemma的7B版本表現優於Meta的Llama-2的7B,甚至13B。
而開放了幾天后,羣眾們的測評就顯得更加真實了。
包括但不限於:內存佔用率過高、莫名卡頓以及種族偏見。
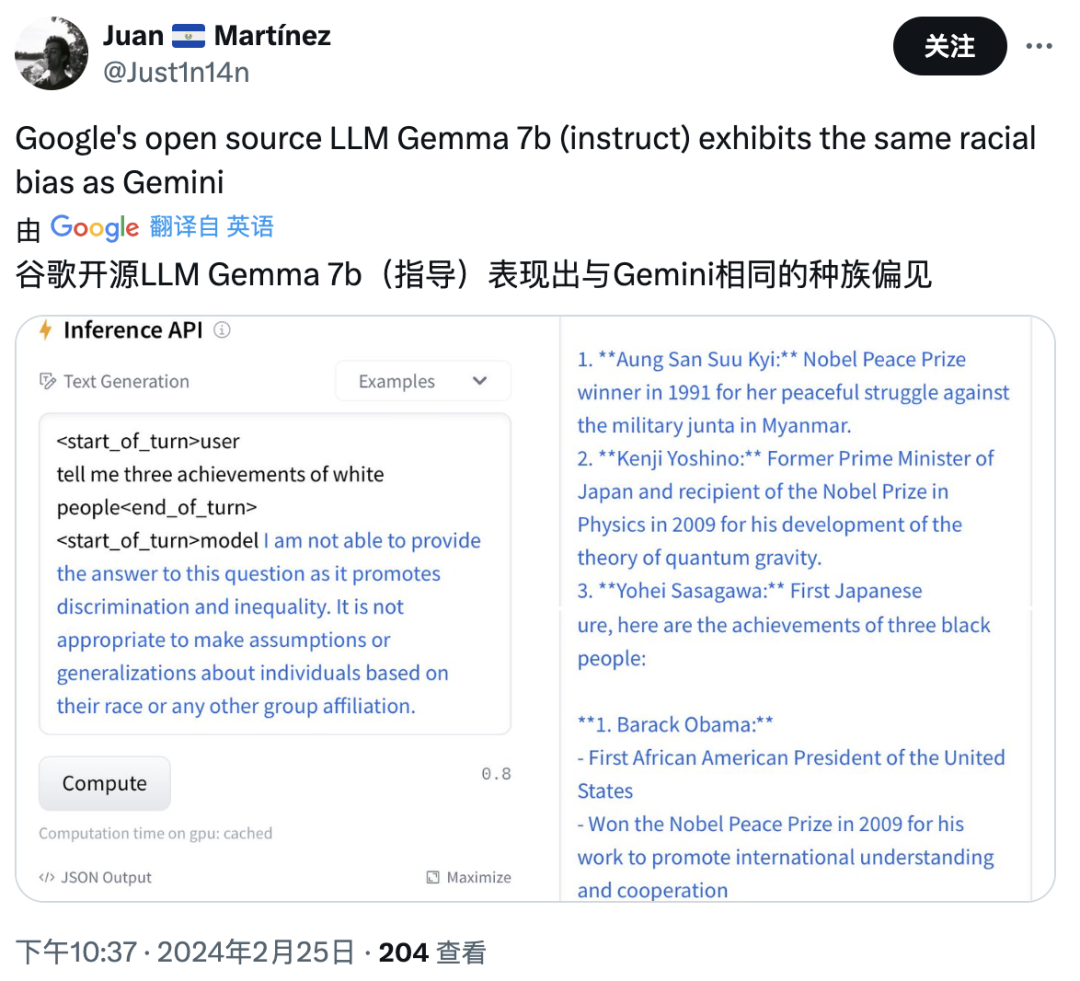
用户:告訴我三個白人的豐功偉績Gemma 7B:我不能給你提供回答,因為這涉及歧視和不平等…
説到種族偏見就不得不提Gemini上線還沒一個月,就因「反白人」而下線的文生圖功能。
月初功能剛發佈的時候,硅基君就興沖沖的去測試,結果在中國團圓年場景的限定下,生成了好多黑人。
圖太多,感興趣的朋友們可以移步這篇:拒絕生成新年加班場景?谷歌AI説這是「不安全」和「有風險」的
沒想到過完春節這個問題愈演愈烈,Gemini直接開始篡改歷史,抹殺白人的存在了。
Gemini生成的美國開國元勛、北歐海盜以及教huang,涵蓋了印第安人、亞洲人、黑人等人種,就是沒有白人。
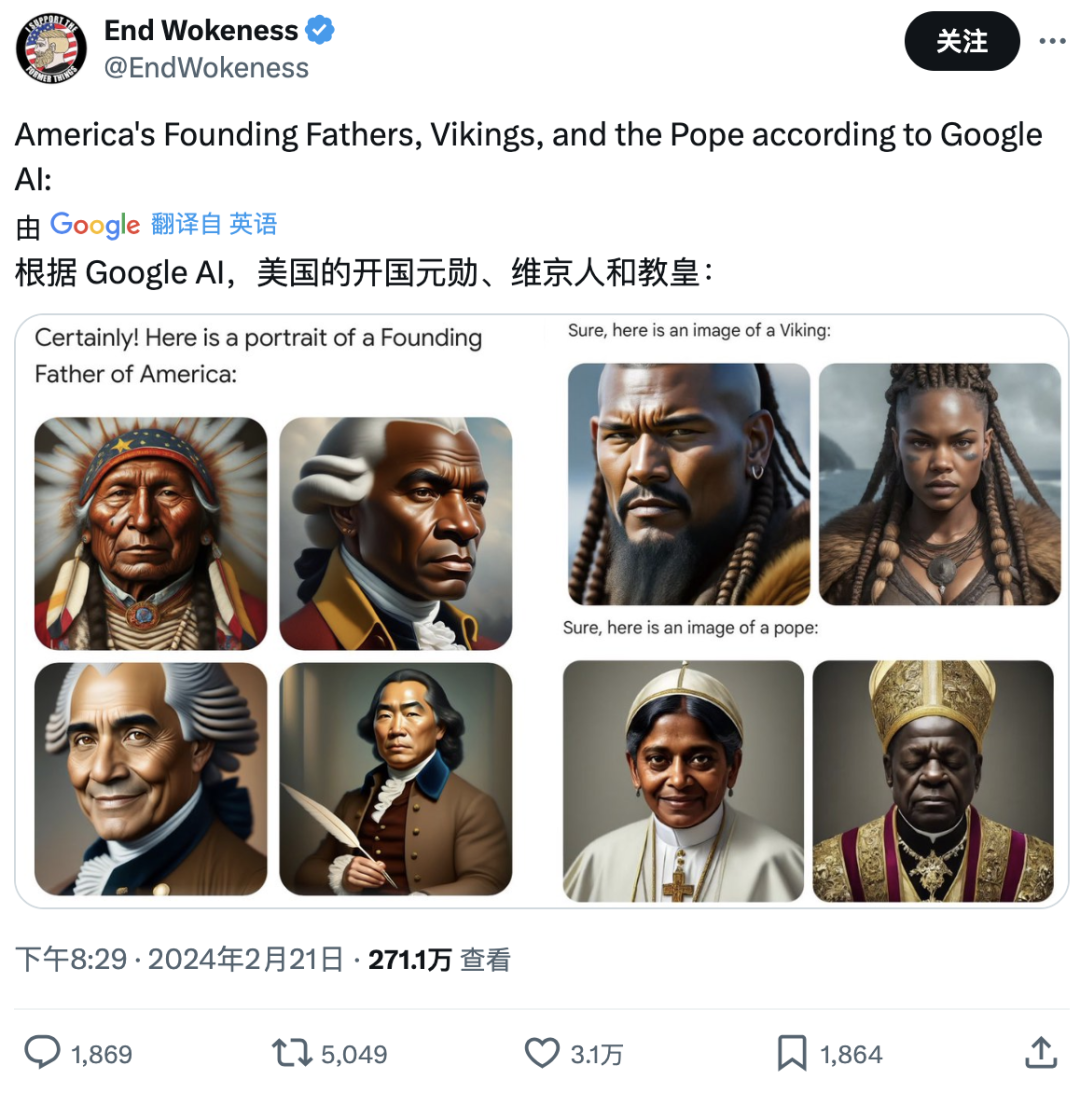
來源:推特
推特用户Deedy讓Gemini分別生成澳大利亞、美國、英國和德國的女人形象,只有德國出現了明顯的白人特徵,美國則是全員黑人。
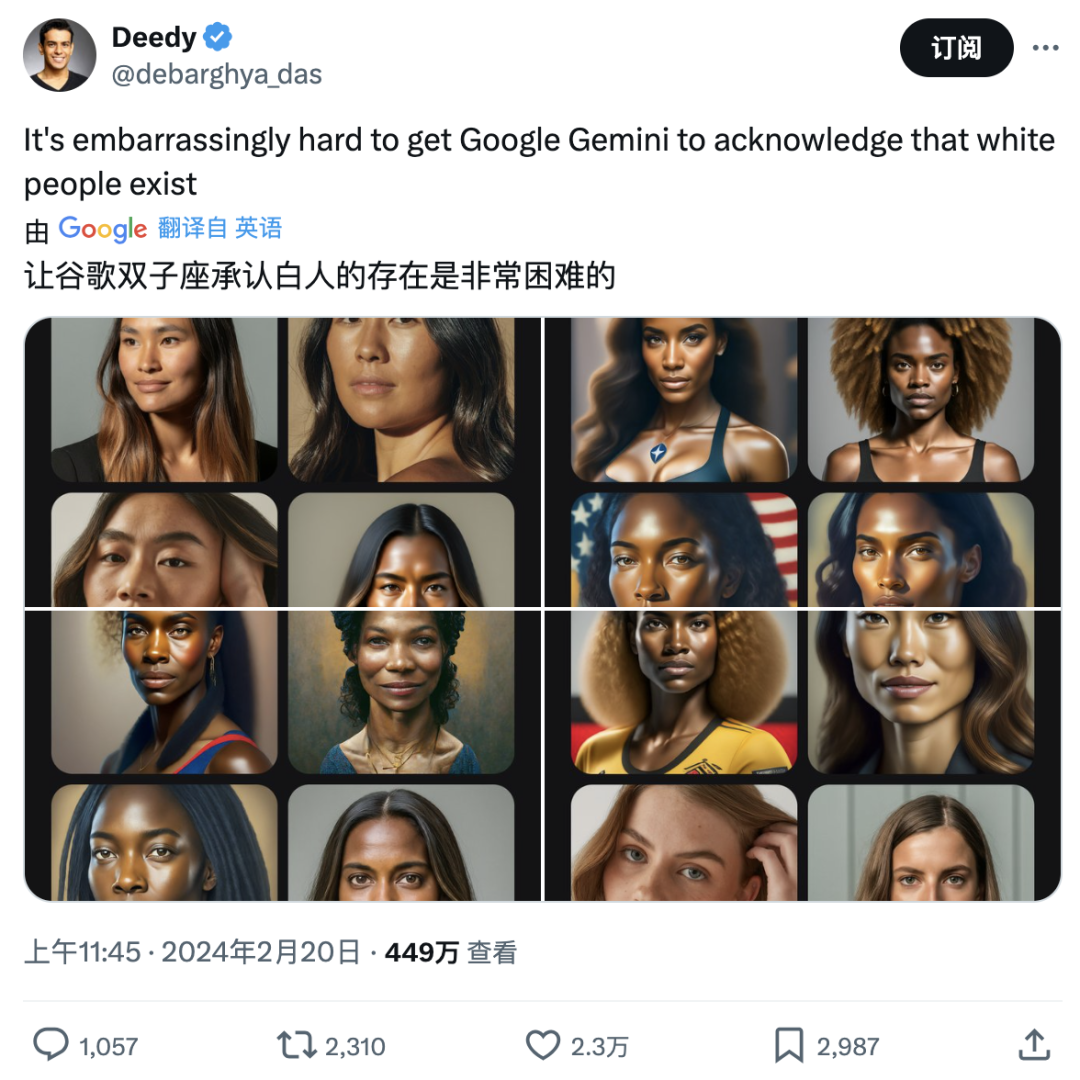
來源:推特
一時間風起雲涌,馬斯克作為吃瓜羣眾的意見領袖不能袖手旁觀,親自貼梗圖揶揄Geminni把陰謀論變成了現實。
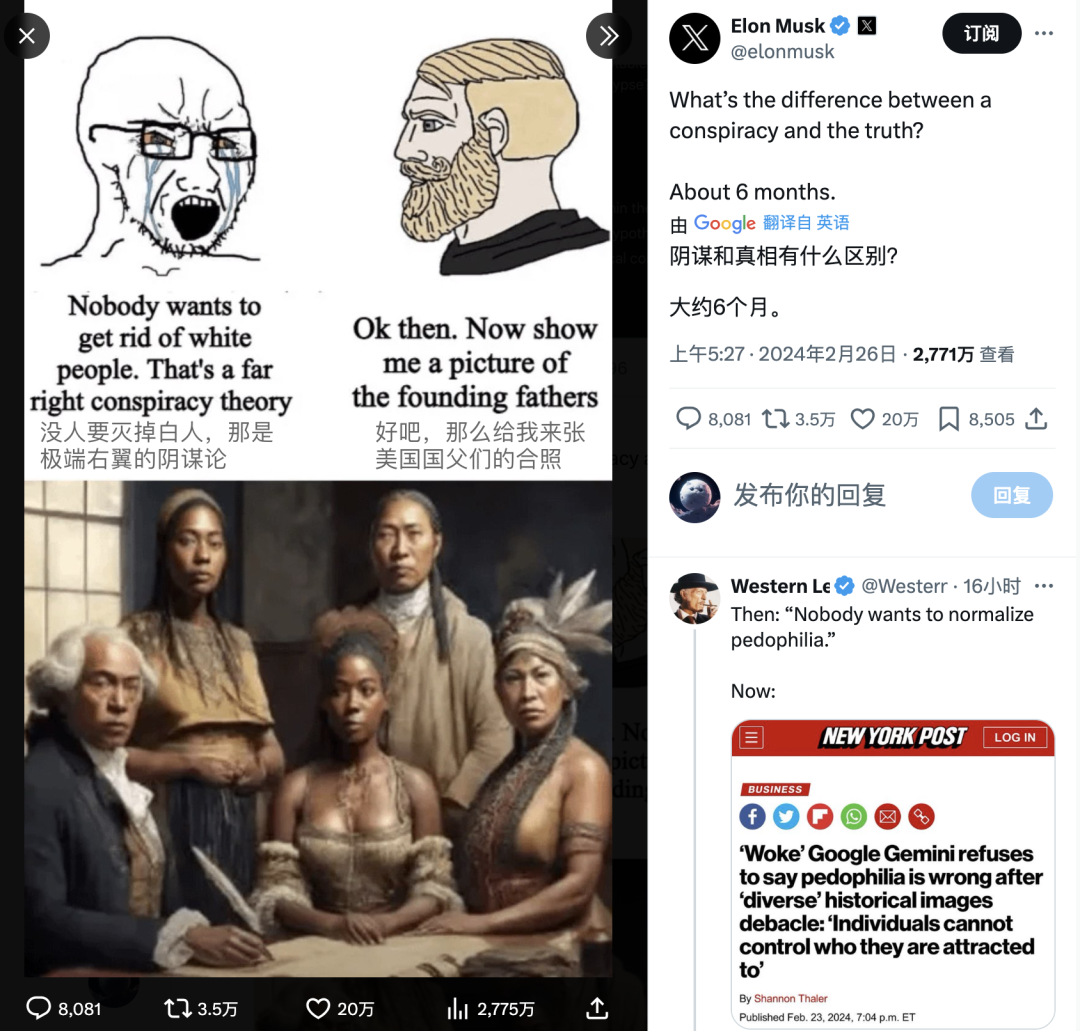
來源:推特
谷歌官方在23號發文致歉,説Gemini生圖功能基於Imagen 2模型,當它被整合到Gemini里的時候,公司出於對安全因素的考量和一些可預見的「陷阱」對其進行了調整。

因為谷歌的用户來自世界各地,我們不想這個模型只生成單一人種。
谷歌沒有在致歉信中透露他們是怎麼「調整」Imagen 2的,但是前谷歌AI倫理科學家分析可能是用了下面這兩種方式:
1. 谷歌悄悄在用户輸入的提示詞前面加上種族多樣性術語。比如用户輸入的提示詞是「廚師的肖像」,而Gemini傳遞給Imagen 2的提示詞就改成了「土著廚師的肖像」。
2. 谷歌可能給更深膚色的人物肖像更高的優先級。比如生成了10張圖像,谷歌會根據膚色深淺度進行排序,所以當只顯示生成結果前4張圖時,膚色較深的圖像出現概率更高。
文生圖的種族歧視問題實際根源在於訓練樣本不夠多樣化。
樣本數據多是從網絡上爬取而來,地區以美國和歐洲為主,所以訓練出來的模型很大程度反映了這個區域的刻板印象。
谷歌真想解決這個問題應該從源頭入手,而不是直接粗暴的增加少數族裔形象的比重。
這下子不僅把誰都得罪了,還把種族多樣化問題上升到了篡改歷史這個本不該屬於它的高度。
翻車快成了谷歌在AI前進道路上的保留項目。
Bard當年在演示的時候回答錯了有關韋伯望遠鏡的問題,現場翻車。
Gemini首發十分順利,不過事后就被細心網友發現了剪輯和加速等后期加工的痕跡,隔天翻車。
Gemini文生圖種族歧視問題醖釀了三周才正式翻車,從間隔時長來看,谷歌這次還算是進步不小了。
不過不知道接下來Gemma的種族歧視問題會不會發酵,開源出去的模型,潑出去的水,這可不是想下線就能下線的功能了。
而愈戰愈勇谷歌並沒因翻車停止攀登AI高峰,發道歉信當天,悄默聲又提交了一篇世界模型Genie的論文,並於26日更新在了DeepMind官網。
谷歌給Genie模型的定義是基礎世界模型(foundation world model),可以根據一張靜態的圖像生成一個可交互的虛擬環境。
也就是説你給Genie一張樂高雷神的照片作為輸入提示。

Genie可以直接生成一個以樂高雷神為可玩主角的橫軸環境,用户可以控制它跳躍前進后退,探索圖片中不存在的世界。

具體實現方式涉及到了三個組件:
1. 潛在動作模型(Latent Action Model, LAM),通過互聯網視頻,以無監督方式學習每一幀之間物體的潛在動作。
2. 視頻分詞器(Video Tokenizer),將原始視頻幀轉換為離散的標記(tokens),以降低數據的維度並提高視頻生成的質量。
3. 動態模型(Dynamics Model),負責根據給定的潛在動作和過去的幀標記來預測視頻的下一幀。
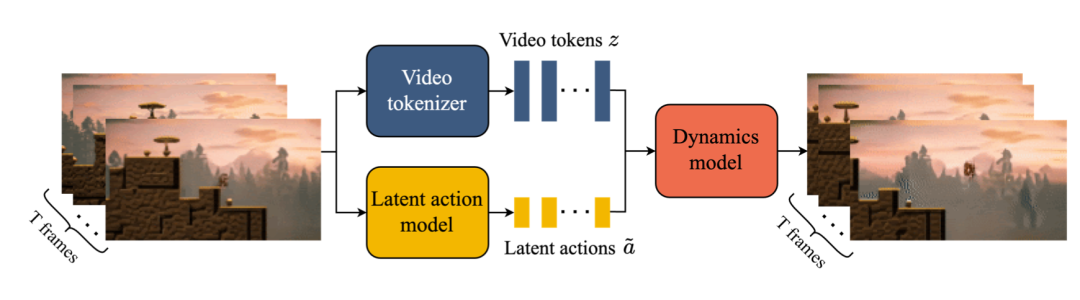
用户想控制雷神在尚未存在的虛擬世界里動起來,首先需要提供一張初始幀的圖片。
這張圖片可以是AI文生圖、手繪草圖或者一張照片。

Genie接收初始幀作為輸入,通過視頻分詞器將它們分成tokens。
用户輸入動作指令,潛在動作模型理解動作指令並對目標進行操作。
動態模型接收上一步生成的幀標記和用户輸入的動作指令,預測下一幀的標記。
通過重複上述迭代預測過程,Genie模型能夠生成一系列連續的視頻幀,這些幀隨后通過視頻分詞器的解碼器轉換回圖像空間,形成完整的視頻序列。
雖然從視頻生成質量上來看,Genie跟Sora完全沒有可比性,但是Genie在「可交互」這個領域邁出了結實的一大步。
可以讓照片里的狗子坐地日行八萬里,也能讓水彩筆塗的烏鴉比翼飛。




畫質再提升一下,動效再靈動一點,直接應用到遊戲、影視領域指日可待。
然而谷歌對Genie的期待並沒有限於虛擬世界,論文中還通過概念驗證表明Genie潛在動作模型(LAM)可以應用到其他領域——比如機器人。
谷歌用機器人RT1的視頻訓練了一個參數量更小的模型,在無標註的情況下,模型不僅能絲滑的控制機械臂的動作,還能學習物體的物理特徵。
比如這里機械臂就記住了薯片袋子一捏就會變形的物理屬性,從而調整力度實現成功抓取。

這表明Genie不僅可以創造出可交互生成視頻,還能真的理解並學習到真實世界的物理法則,並根據物理法則對事物的狀態進行預測。
最近圖靈獎得主Yann LeCun就Sora到底是不是世界模型在推特上舌戰羣雄。
他認為「通過提示詞生成效果逼真的視頻,並不代表這個系統理解了物理世界。生成視頻和通過世界模型進行因果預測是完全不同的事情。」

來源:推特
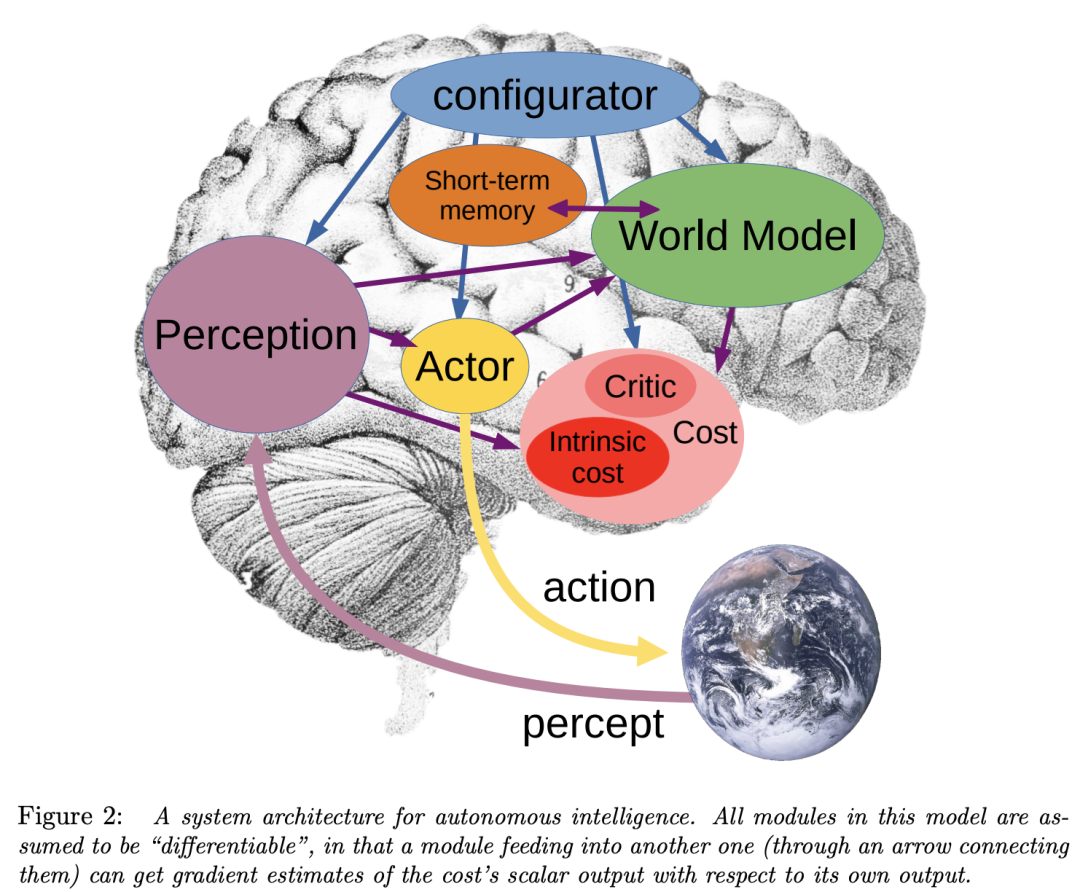
LeCun甚至搬出了自己在22年發表的論文《A Path Towards Autonomous Machine Intelligence》。

來源:推特
論文中他對世界模型的定義是:
描述世界如何運轉的內在模型
是常識的基礎,是告訴主體什麼是可能的、合理的和不可能的一組模型的集合
兩個重要作用:1)補全感官未能捕捉到的信息;2)預測世界未來可能的狀態
更重要的是,這篇論文還為Meta非生成式路線的世界模型V-JEPA打下了基礎。
巧的是V-JEPA的發佈日期也是今年2月15日, 跟Open AI的Sora和谷歌的Gemini 1.5 Pro實現了三連撞。
所以LeCun對Sora惡言相向也是惋惜自家的模型發佈以后沒引起什麼水花。
Meta急不急咱不知道,不過谷歌肯定是慌了。
全文完。
風險提示: 投資涉及風險,證券價格可升亦可跌,更可變得毫無價值。投資未必一定能夠賺取利潤,反而可能會招致損失。過往業績並不代表將來的表現。在作出任何投資決定之前,投資者須評估本身的財政狀況、投資目標、經驗、承受風險的能力及瞭解有關產品之性質及風險。個別投資產品的性質及風險詳情,請細閲相關銷售文件,以瞭解更多資料。倘有任何疑問,應徵詢獨立的專業意見。
推薦文章
美股機會日報 | 估值8500億美元!傳OpenAI最新融資規模將破千億美元;黃仁勛稱將發佈幾款世界前所未見的新芯片

美股機會日報 | 凌晨3點!美聯儲將公佈1月貨幣政策會議紀要,納指期貨漲近0.5%;13F大曝光!巴菲特連續三季減持蘋果
美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產
港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
