熱門資訊> 正文
全球智能機器人時代前瞻
2023-04-18 08:31
- 微軟(MSFT) 0
- 谷歌(GOOG) 0
- 谷歌A(GOOGL) 0
本文來自格隆匯專欄:中金研究,作者:郭威秀 王梓琳 等
ChatGPT迭代速度超出市場預期,多模態大語言模型在垂直領域應用引起廣泛關注,我們研究其在機器人應用落地的可行性,認為多模態語言模型應用是機器人真正具有類人感知的一大基礎,我們看好長期產業趨勢。
摘要
谷歌PaLM-E模型推出,多模態語言模型走向機器人應用。AI與機器人發展相互獨立,隨2006年深度學習出現,AI開始落地機器人應用。早期AI+機器人主要集中於計算機視覺與語義分析兩大應用。直到2017年Transformer模型推出后,多模態大模型飛速發展,機器人應用逐漸向情感交流、多維數據交互發展。2023年3月,谷歌推出全球最大視覺語言模型PaLM-E,實現機器人視覺與文字的同步訓練;同期,微軟發佈論文嘗試將CHATGPT接入機器人訓練,引起行業廣泛關注。我們認為多模態應用於機器人有助於降低機器人編程成本、提升人機交互能力、生動化應用場景,或是技術大勢所趨。
► 場景要素:適當容錯率與數據非私有化格外重要。我們總結多模態大語言模型應用在機器人場景需要四大要素:其中,工藝不涉及商業機密、容錯率偏高是必要條件;另外,編程標準化程度高、一次性初始化編程是可選條件。我們認為To C端應用是理想場景,例如家庭陪伴服務機器人、送餐快遞機器人;此外,移動機器人、食品鞋服等行業搬運機器人、售后運維環節機器人應用有望在工業場景率先落地。
► 落地難點:合理權衡商業機密與編程效率間的關係。編程效率的提高意味着數據要儘可能開源、生產工藝要儘可能標準化、人工反饋環節要儘可能減少,但這恰好意味着商業機密要公開、市場競爭規律被抹平。我們認為編程效率與機密倫理的權衡對於多模態大語言模型大規模推廣至關重要。此外大模型天然具有可信度、時效性、訓練成本高等問題,大模型或在部分應用場景落地率先到來。
► 格局衝擊:固有格局較難打破。我們認為在企業間商業數據不完全打通背景下,數據要素是核心競爭力,固有格局較難打破;在商業數據打通背景下,機器人本體企業的核心競爭力更多體現為控制能力與硬件製造能力,即如何讓運動變得更加高速、精準。
我們看好大語言模型應用長期落地的趨勢,認為具有自主軟件訓練能力的機器人企業有望核心受益。
風險
CHATGPT技術迭代速度慢於預期、機器人零部件自主化進度不及預期。
催化頻頻,多模態語言模型加速走向機器人
發展契機頻現,多模態大模型賦能機器人。2023年3月,谷歌的PaLM-E模型實現了多模態大語言模型在機器人場景訓練方面的落地,引發廣泛關注;同期,微軟發表論文《ChatGPT for Robotics: Design Principles and Model Abilities》,提出利用ChatGPT操控機器人的基本思路;4月7日,阿里雲大語言模型開放對公眾測試,為國內垂直領域嘗試提供可能。
從海內外嘗試來看,「多模態語言大模型+機器人」近期主要用於情感交互及場景拓展訓練。海外市場,谷歌公司開發了PaLM-E大模型,其在機器人多場景訓練方面具有良好表現;此外,伯克利聯手谷歌依據GPT-3開發出了基於語義控制的自主導航機器人。國內市場,優必選充分發揮多模態語言大模型在自然語言理解上的優勢,在情感交互方面實現了諸多應用。
海外試水:LM-Nav語義導航成功落地,PaLM-E指導場景型訓練
【谷歌】PaLM-E實現機器人場景訓練
美西時間3月6日,來自谷歌和德國柏林工業大學的一組人工智能研究人員公佈了史上最大視覺語言模型PaLM-E。PaLM-E為訓練多模態機械手提供了一種新的模型模式,其通過將機器人任務和視覺語言任務融合實現訓練。我們認為,谷歌的例子充分顯示了多模態語言大模型在機器人多數據源多場景融合上的可行性。
圖表1:PaLM-E模型指導機器人機械手完成多任務問題
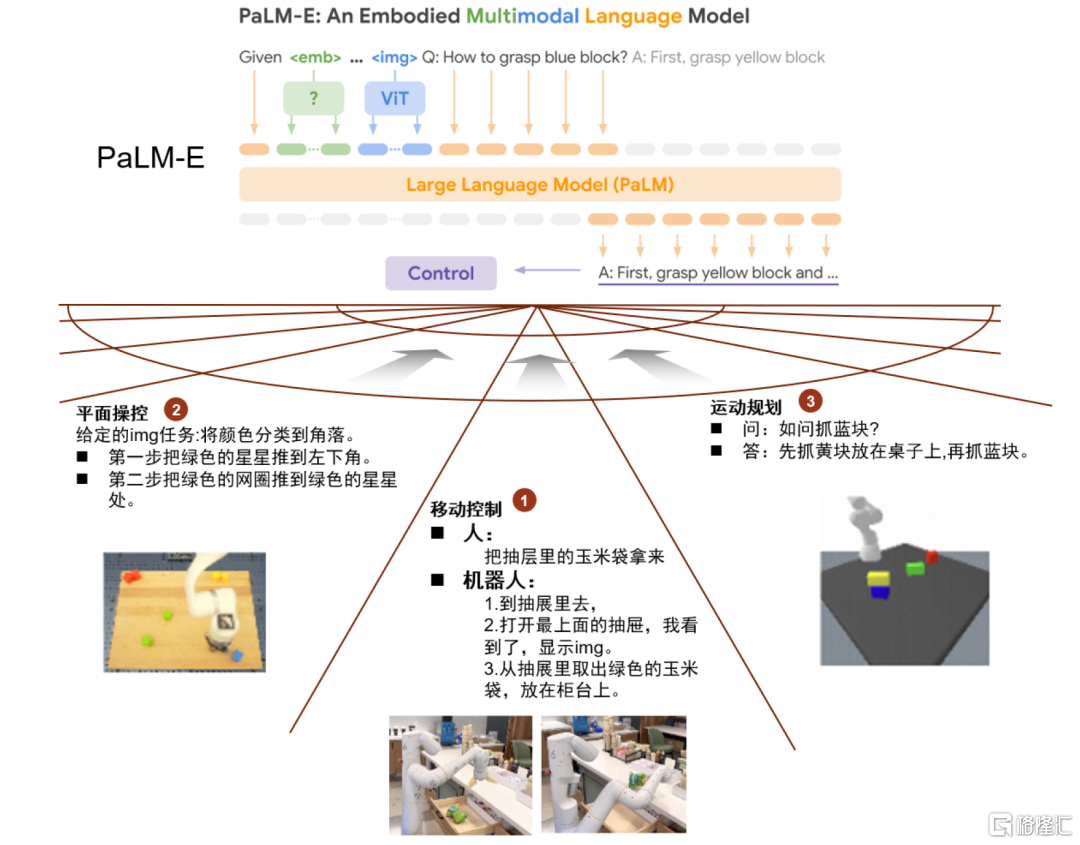
資料來源:Google官網,《PaLM-E: An Embodied Multimodal Language Model》(Danny Driess等,2023),中金公司研究部
PaLM-E模型在視覺和語言領域都實現了顯著正向知識遷移。據谷歌試驗結果,PaLM-E模型在同時進行多任務、多數據訓練過程中,表現出更優的準確度,正向的知識遷移提高了機器人學習的有效性。但我們認為,PaLM-E模型主要還是以文本為輸出結果,在輸出編碼能力方面技術仍在進步。
圖表2:PaLM-E具備良好的正向遷移能力
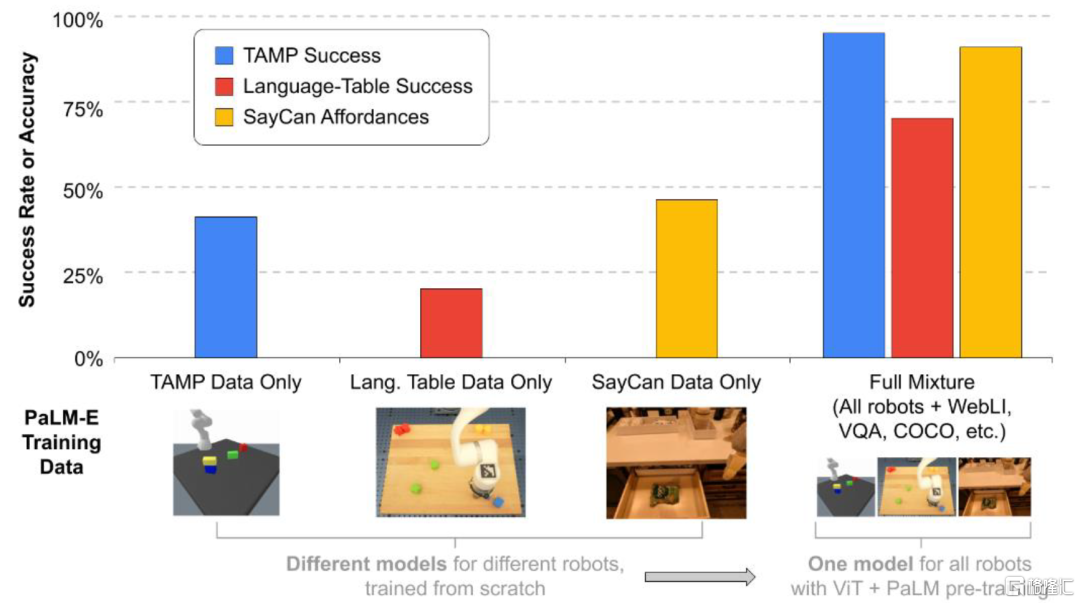
資料來源:Google官網,《PaLM-E: An Embodied Multimodal Language Model》(Danny Driess等,2023),中金公司研究部
【伯克利】LM-Nav打開大模型導航應用先驅
UC Berkeley聯合谷歌機器人團隊2022年6月開發了基於語言視覺動作預訓練大模型的LM-Nav,LM-Nav助力利用自然語言訓練的智能導航機器人落地。LM-Nav基於GPT-3通過自我監督訓練的目標條件策略,訓練機器人從大型的、未標記的數據集中進行基於視覺的導航學習,可在大規模試驗中表現出良好的可擴展性。
圖表3:LM-Nav基於GPT-3實現機器人語義導航

資料來源:《Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action》(UC Berkeley等,2023),中金公司研究部
國內試水:優必選試水,強化情感交互優勢初顯
多模態強化情感交互優勢初顯。多模態語言大模型的核心本質是依靠與自然語言的上下文關係進行訓練,因此並不擅長處理工業場景中數理公式所表達的場景問題。但在服務端,還有一類專注人機交互、情感變化、語言對話的機器人,即以優必選等為代表的專注人機交互企業開發的人形機器人。在國內市場,優必選充分利用多模態語言大模型的優勢,在深化機器人情感語言交互方面做出諸多嘗試。
圖表4:機器人在服務場景下的人機交互領域的應用

資料來源:優必選官網,中金公司研究部
公司提出了語音預訓練、圖文語音轉化預訓練大模型。優必選是一家集人工智能和人形機器人研發、平臺軟件開發運用及產品銷售為一體的全球性高科技創新企業。作為人工智能(AI)賦能機器人的引航企業,公司開始着手訓練面向具體機器人場景的語言任務、數字孿生、機器視覺等,並提出了語音預訓練大模型、圖文語音轉化預訓練大模型:
圖表5:優必選結合多模態語言大模型嘗試的應用場景
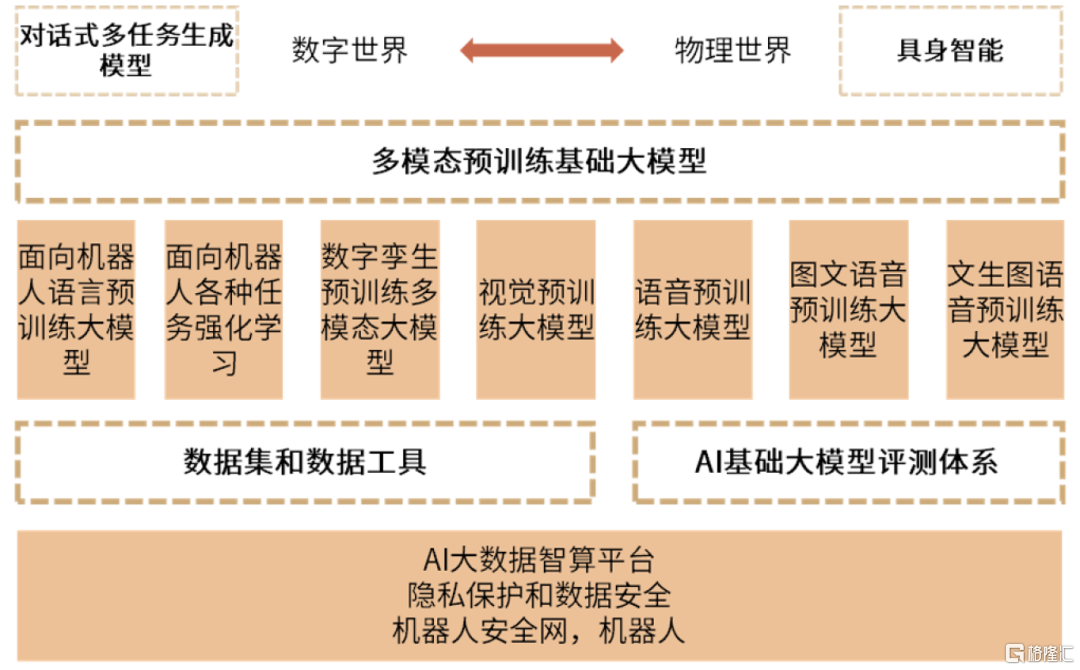
資料來源:優必選官網,中金公司研究部
► 語音預訓練大模型在訓練機器人模仿人語音語調的過程中發揮重要作用。人類可通過不停的模仿與觀察,擁有模仿他人語氣語調説話的能力,而預訓練大模型就是通過上下文之間的關聯性來實現強大的模仿與泛化能力,公司在語音訓練方面實現了機器人運用大模型進行多種語調風格的訓練,如廣播風格,講故事風格,演講風格等。
► 圖文轉換預訓練大模型是訓練機器人的圖文轉換的能力。機器人圖文轉化正是其模仿人看圖説話、看畫繪圖的能力。公司希望未來能夠和諸多平臺聯手,在盤古、悟道等重要大模型上實現面向機器人的多模態語言大模型的搭建。
公司提出融合視頻、文本、語音的多模態大模型的虛擬人融合技術。爲了實現機器人與人交互的合理性與真實性,公司利用預訓練大模型建立起相應的技術能力,利用多模態融合的方法,對視頻、文本、語音的預訓練大模型加以融合,從而可以實現綜合性的情感識別,最終形成具有良好真實性的語音説話頭虛擬人。
圖表6:優必選融合視頻文本語音的多模態大模型訓練虛擬人合成技術
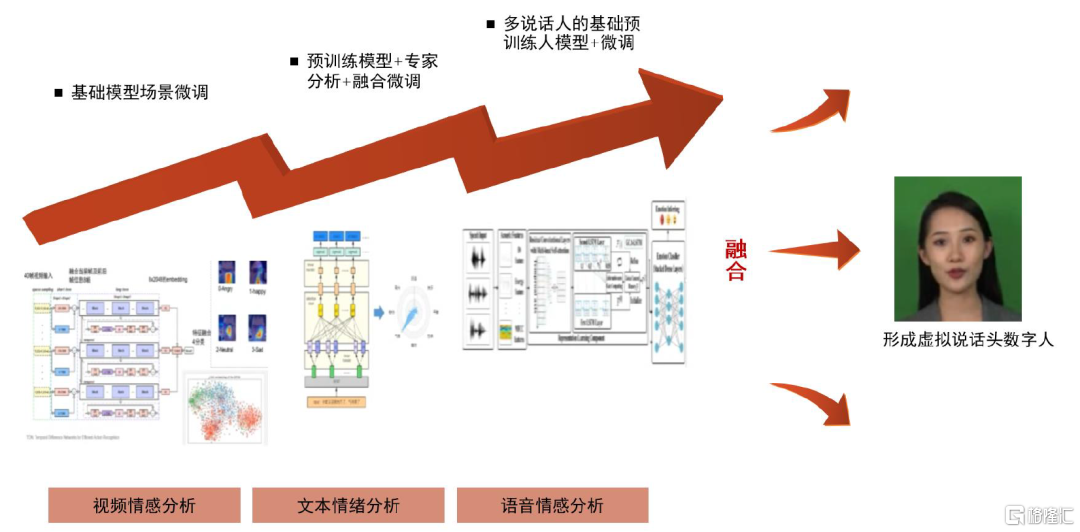
資料來源:優必選官網,中金公司研究部
多模態是AI的重要組成,推動機器人智能發展
AI技術:賦能機器人視覺感知與語義分析
AI技術位於第三次浪潮階段。1990年代末期,AI技術共經歷了三次浪潮,1956至1960年為AI技術的第一次上升期,1960至1970年代符號學派逐漸走向低谷;此后,仿生學派引領AI技術的第二次上升浪潮,專家系統和BP算法得到飛速發展,研發更加重視具體應用的實現;2006年深度算法的提出開啟第三次浪潮,AI技術迅速發展,並逐步在機器翻譯、人臉識別、無人駕駛、智能家居、機器人等更廣闊的全場景實現應用落地。
圖表7:AI發展歷程
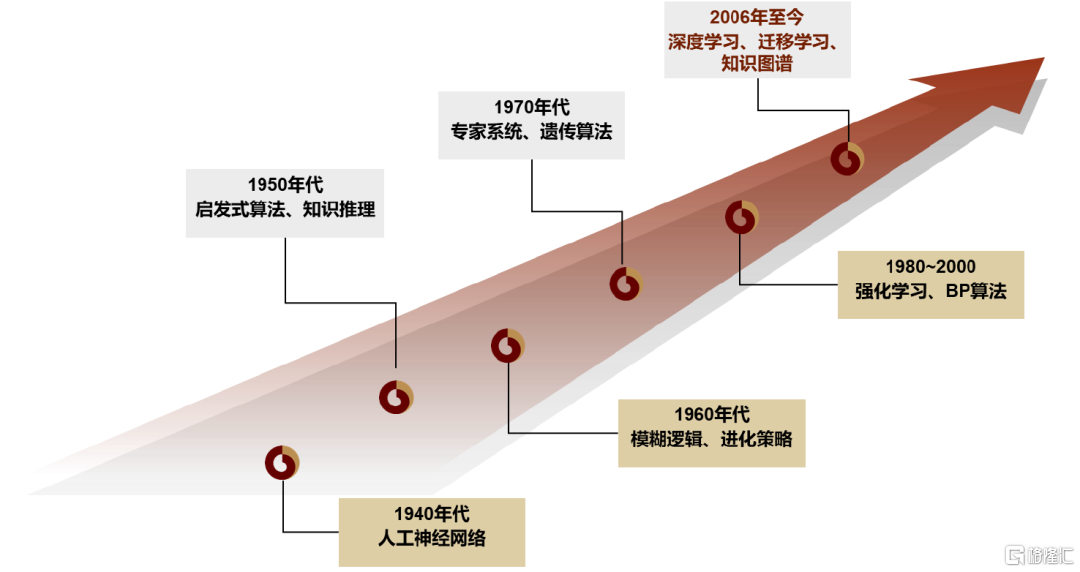
資料來源:《人工智能綜述:AI的發展》(崔雍浩,商聰等,2023),中金公司研究部
AI與機器人是相對獨立的學科。由於AI領域和機器人領域均涉及到模擬人的行為,二者的概念常被混淆,但實際上,我們認為AI和機器人是較為獨立的兩個學科。張鈸(2021)在《人工智能視角下的機器人研究與發展》中指出,AI是以實現模擬人類智能行為為目的的智能體(intelligent agent),機器人則是面向任務、面向應用的機器,模擬人類行為只是機器人達成任務的手段之一。
深度學習的提出促進AI技術在機器人場景的滲透。現代機器人的研究始於20世紀中期,1960年代,首個融合AI的機器人Shakey誕生,但由於計算機運算速度非常緩慢,Shakey需要數小時的時間來感知和分析環境以規劃路徑;隨着傳感和智能技術的發展,1980年代開始進入智能機器人研究階段,但仍未大規模應用AI技術;2010年以后,深度學習算法在語音和視覺識別上迎來較大突破,加之算力的提升,語音和視覺識別相關的AI技術開始快速在機器人中落地應用。
圖表8:結合AI技術的機器人發展歷程
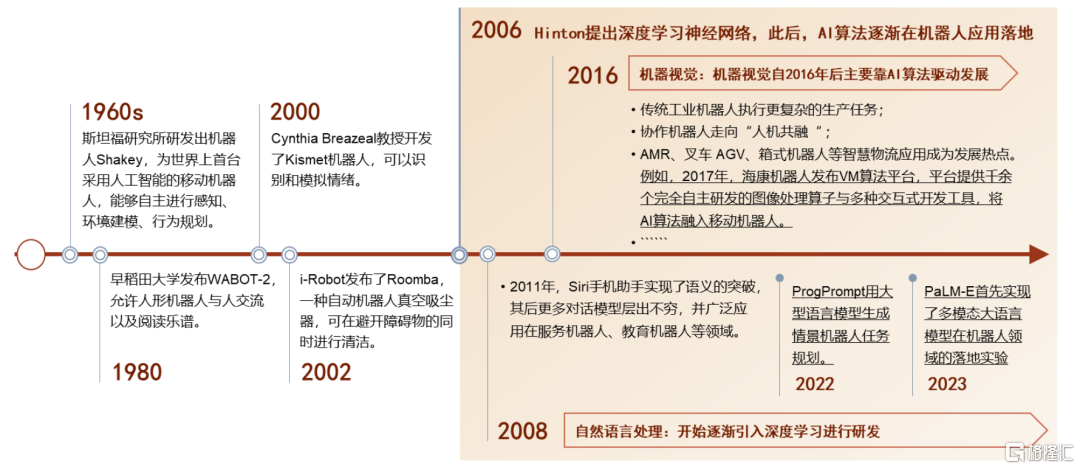
資料來源:《機器視覺發展白皮書(2021版)》(機器視覺產業聯盟CMVU),高工機器人公眾號,中金公司研究部
從機器人系統層級來看,AI主要應用在機器人感知和決策層。從機器人感知、決策、執行三部分來看,AI技術目前主要運用在機器人的感知領域和部分輔助決策領域。
► 感知領域:運用在機器人身上的AI技術以CV(計算機視覺)和NLP(自然語言處理)為主,例如工業機器人在工業相機和AI物體檢測算法下進行分揀、移動機器人在傳感器和算法加持下實現定位導航、服務機器人在語音識別的AI技術下和客户交流。
► 決策領域:AI技術主要滲透進智能調度算法等應用。機器人傳統的運動控制和運動規劃算法在數學上可靠性更強,RL(強化學習)雖為機器人方向的研究熱點,但在工業環境下仍處於探索階段,目前未形成對傳統運動控制算法形成替代的趨勢,因此下文主要講述感知領域的機器人AI技術發展。
圖表9:應用在機器人上的傳統機器人技術和AI技術

資料來源:優必選官網,中金公司研究部
應用一:CV。計算機視覺提升機器人定位和識別精度與效率,應用向3D視覺演進。近年,機器人廠商利用深度學習、語義分割和場景理解來提高低端相機的深度和圖像識別精度與效率,不僅可實現慣性導航、SLAM導航等定位應用,還能在上下料、分揀等工業領域實現目標識別、測量、檢測等功能。隨着2D視覺向3D視覺演進,需要研發處理非結構化三位點雲的神經網絡,實現機器人對三維場景的而精細化理解,目前機器人3D視覺的深度學習應用案例層出不窮,但市場在三維視覺的準確性、導航部署快速性方面仍存在瓶頸。
圖表10:機器人的機器視覺深度學習案例
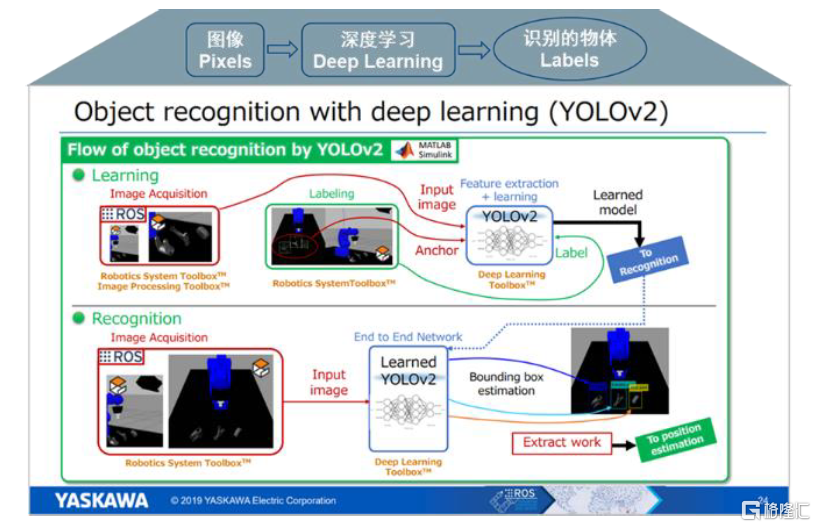
資料來源:機器之心微信公眾號,中金公司研究部
圖表11:機器人的3D視覺深度學習案例

資料來源:機器之心微信公眾號,中金公司研究部
應用二:NLP。機器人語義信息獲取與對話系統加速發展。最早的語言模型出現於上世紀60年代的基於規則系統的語義分析模型;2000-2014年,語言模型基於模塊和統計方法發展,2011年Siri的出現完成了語義方面的突破;2015年開始,市場開始基於神經網絡研發對話模型和產品,預訓練模型在2015年被提出,但在2018年左右才發生重大進展,后續T5、GPT-3、盤古等預訓練語言模型依次開花結果,語言模型向更大規模化、更多模態化高速發展。NLP在機器人中的應用主要在於語義分析和對話系統兩方面:
► 語義分析:機器人首先感知場景中的信息,再通過近些年興起的多模態語言大模型等轉化為物體的語義信息,進一步指導指令執行或自編程。
► 對話系統:對話系統的典型應用為服務機器人,隨着語言模型的升級,機器人的對話系統將有望達到更高的擬人化程度,具備更先進的表達能力和交互性。
圖表12:近年來大語言模型發展歷程
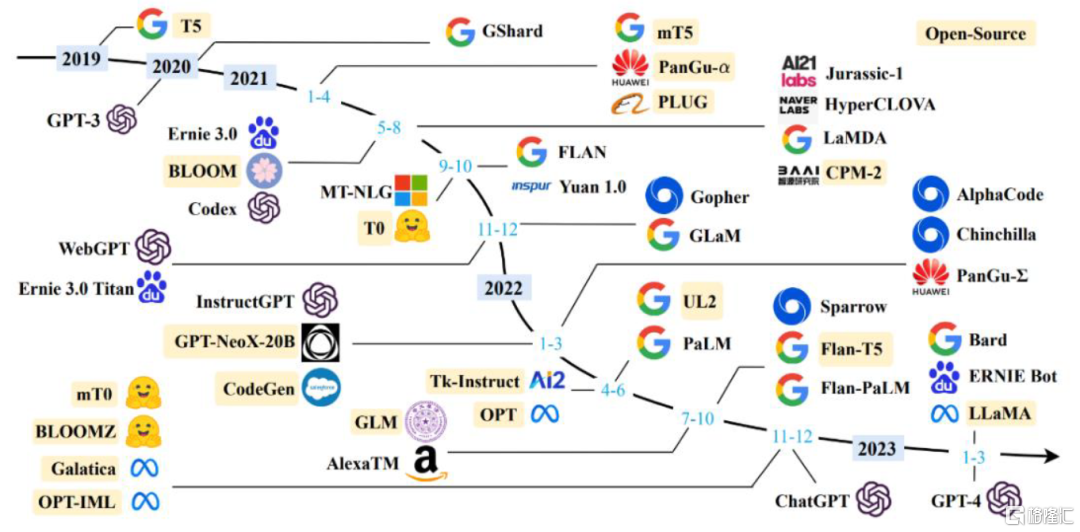
注:圖中標黃模型為開源大語言模型
資料來源:《A Survey of Large Language Models》(Wayne Xin Zhao等,2023),中金公司研究部
AI技術在機器人領域的商業落地主要通過軟件平臺直銷方式。CV技術方面,例如,海康機器人自主開發VM機器視覺算法平臺,可以對客户直接銷售,客户藉助該平臺可快速搭建工業機器人的視覺定位、尺寸測量、缺陷檢測等算法。NLP技術方面,例如,百度開發的對話系統定製平臺UNIT,以和機器人客户託管研發、合作研發或提供技術支持的形式銷售解決方案。
多模態大模型:加速催化機器人感知與情感表達落地
多模態大模型是多模態和大模型的融合,是AI技術的分支之一。多模態是指結合了視覺、文本、語音等多種現實世界中的信號;大模型是指用深度學習等技術構建的包含大參數量的神經網絡模型,近年多模態大語言模型成為大模型發展最快的分類之一。
多模態大模型的發展面臨五大技術挑戰。據《Multimodal Machine Learning: A Survey and Taxonomy》(T. Baltrušaitis et al., 2017),多模態數據具有異質性,且模態之間的關係通常是較為主觀的,因此模型面對五大挑戰:1)表徵:挖掘模態的互補和冗余來表徵多模態數據;2)翻譯:從一種模態映射到另一種模態;3)對齊:對齊多模態的子元素;4)融合:將多種模態信息結合起來進行預測;5)共同學習:不同模態的預測模型之間進行知識轉移、協同訓練。
圖表13:多模態機器學習不同應用的核心挑戰
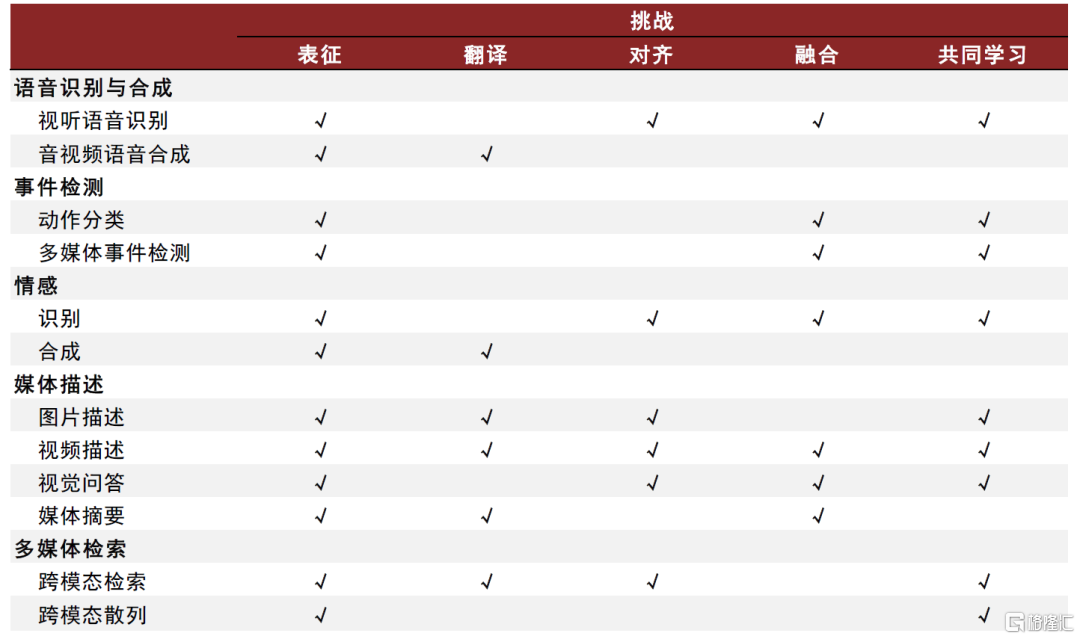
資料來源:《Multimodal Machine Learning: A Survey and Taxonomy》(Tadas Baltrušaitis等,2017),中金公司研究部
2017年Transformer模型推出后,多模態大模型飛速發展。多模態的概念最早應用在上世紀的視聽語音識別,2000年初常見應用為互聯網以文本搜索圖片等跨模態檢索,后續研究拓展至通過分析視覺和語言信息進行情感識別、圖像描述等方向。2017年,《Attention Is All You Need》一文首次提出Transformer模型,該模型推動多模態預訓練模型飛速發展,具體呈現以下特點:
► 多以視覺語言模型為主,模態較為單一。近年來推出的Flamingo、BLIP-2、Kosmos-1等模型大多以圖文對形式進行聯合訓練,在大語言模型之上實現視覺和文字等多模態輸入、通用語言單一模態輸出。Visual ChatGPT則可以在多模態輸入的基礎上實現通視覺的生成,但其實現方式僅僅為通過ChatGPT將自然語言描述的指令轉換為機器可理解的視覺指令,缺少統一的模型訓練。
► 範式多為在預訓練模型中引入Prompt或Adapter來實現多模態,僅需調整個別參數以降低成本。傳統大模型往往採用預訓練模型和微調的範式,但對於多模態預訓練模型而言,對整個模型微調的成本更大,多模態的表徵也更易被破壞,因此往往採用以下範式:1)引入Prompty以指導下游任務,其他大模型部分固定,只需訓練該指令。例如,Visual ChatGPT引入Prompt管理器。2)嵌入Adapter將輸入的內容轉化為預訓練模型本身更能理解的方式,訓練時只需調整Adapter。例如,Flamingo通過加入門控機制的Adapter模塊將視覺信息置入語言模型中,利用原語言模型的知識來進行推理。
► 缺乏對圖文對話指令的微調,與人類的對齊性較弱。盧志武教授在《ChatGPT對多模態通用生成模型的重要啓發》的演講中指出,當前的多模態大模型普遍沒有考慮與人類意圖對齊,這會導致模型生成很多有害的信息,例如生成缺少邏輯的文段。
► 由多模態預訓練模型逐漸轉變為多模態通用生成模型,多模態模型的最終目的為通過建立一個大模型實現通用功能。
我們認為目前大語言模型的積澱較為充足,基於大語言模型的多模態預訓練模型或將率先落地,集合更多模態的通用多模態模型技術突破有待進一步觀察。
圖表14:多模態大模型發展情況
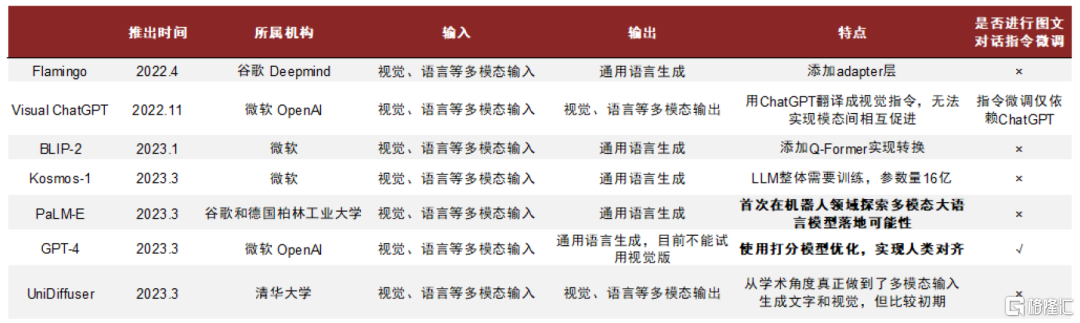
資料來源:機器之心微信公眾號,中金公司研究部
圖表15:Visual ChatGPT模型示意圖
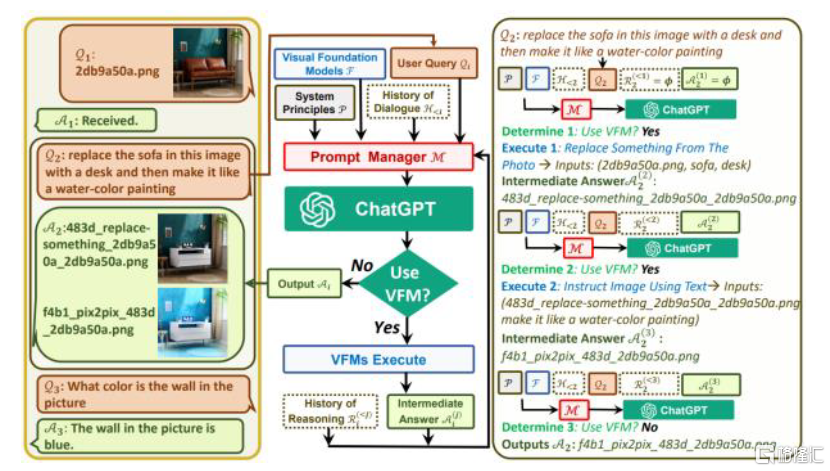
資料來源:《Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models》(Chenfei Wu等,2023),中金公司研究部
圖表16:Flamingo模型示意圖
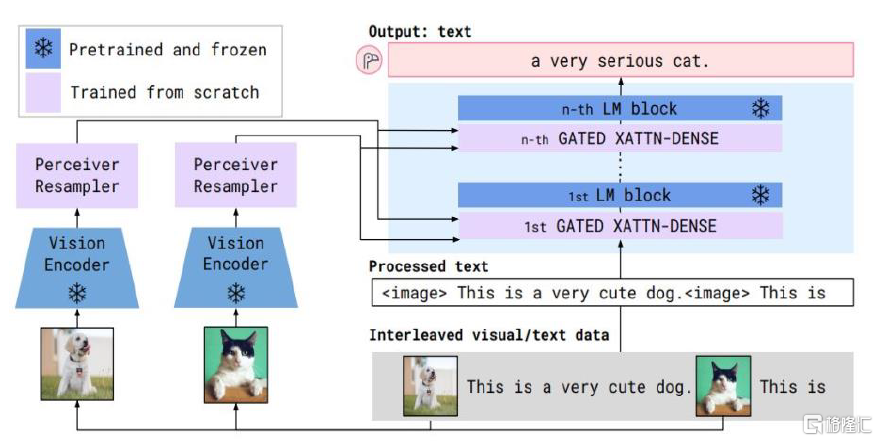
資料來源:《Flamingo: a Visual Language Model for Few-Shot Learning》(Jean-Baptiste Alayrac等,2022),中金公司研究部
多模態大模型發展契機頻現,未來優化進一步賦能機器人。2023年3月,谷歌的PaLM-E模型首先實現了多模態大語言模型在機器人領域的落地實驗,但應用場景較為侷限。我們認為多模態大模型以下發展脈絡或進一步助推機器人發展:
► 帶動機器人實現降本。可以通過將視覺等多模態信息以Adapter等形式嵌入到GPT等模型中,使多模態模型推理能力的強化變得更加容易,模型實現降本,並傳導至機器人成本優化。
► 增強機器人的人機交互能力。借鑑GPT的發展思路,多模態模型的發展將更重視並實現與人類感官對齊,助力人機交互能力與情感交流能力提升。
► 機器人自編譯有望實現。隨多模態模型逐漸拓展至視覺、聲音、文本、生理信號等模態,大模型中模態間的隱性知識和共同學習過程將進一步被激發,機器人從現實世界獲取語義信息的精確性大大提升,我們預計其有望自身轉化更多模態的信息為執行代碼,減少工程師編碼的工程,並使自身更快地走向具身智能。
► 機器人細分領域應用得以深入。多模態模型不僅侷限在圖文領域,將在信息搜索、視覺識別、情感分析、家庭看護等多個領域大放異彩,機器人垂直細分領域應用也將不斷拓展。
To C端應用或率先落地,數據要素是核心競爭力
實現步驟:「拿來主義」行不通,「語言轉化」方可行
多模態語言大模型指導機器人必須遵循良好的步驟。爲了讓多模態語言大模型指導機器人工作,直接將自然語言輸入給機器人是不可行的,需轉化為機器人代碼,即建立自然語言到可編譯語言之間的映射關係非常關鍵,這就需要我們用合理的方法去建立自然語言到可編譯語言之間的映射關係。在這個過程中,合理的API接口、合理的提示訓練、合理的人工檢查必不可少。微軟認為,要讓多模態語言大模型良好的控制機器人做工作,實現路徑包括三個重點環節:定義高階API庫、提示訓練強化學習、人工再回路檢驗修正。
圖表17:ChatGPT控制機器人實現路徑三步走

資料來源:Microsoft《ChatGPT for Robotics》,中金公司研究部
► 必須定義一個高階的機器人API庫。API庫重要功能就是能夠連接到機器人控制系統中的底層硬件代碼,建立自然語言和機器人底層控制函數之間的良好映射關係。具體來説,在這過程中,爲了讓多模態語言模型也能遵循函數庫的規則,預定義函數命名十分關鍵關鍵。清晰、符合自然語言描述的函數名,能讓各函數之間建立良好的功能連接,最終生成高質量的回答。
► 提示訓練(Prompt)必不可少。提示訓練本質上就是微調學習的過程,上下文表述信息充分性將直接影響模型給出答覆的準確性,高質量和大體量的提問需求成為模型精度與泛化能力的關鍵。人機交互中Prompt策略的積累,將是多模態語言模型真正理解編譯語言和工程參數的關鍵。微軟就開發了開源平臺,並利用其進行提示訓練。
► 人工再回路過程進行調整。多模態語言模型的泛化性,往往是以降低精度為代價的,這就使得一般多模態語言模型生成的代碼難以達到工業場景應用精度與安全性。目前生成的代碼尚需要通過人工檢查和虛擬仿真來判別其精度與安全性。
舉例來説,要想讓多模態語言模型編寫代碼驅動機器人幫忙做飯,首先就必須定義通俗易懂的API函數如去某個地方、用品名稱(go_to_location()、user_items())等函數,從而將自然語言命令轉化為編程代碼語言,並通過提示訓練不斷對編程過程進行優化。最終,經過人工調整后形成準確率更高的代碼。
圖表18:ChatGPT控制機器人做飯的學習過程
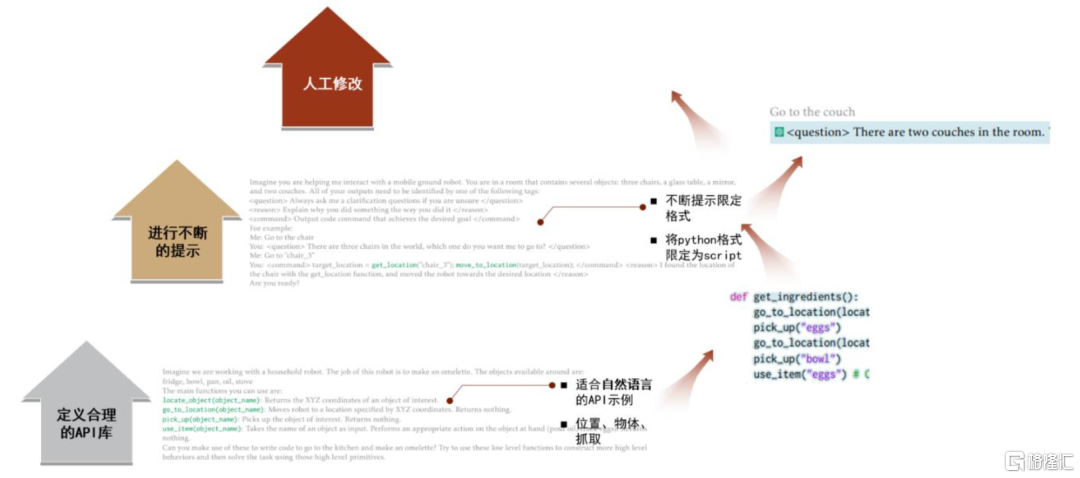
資料來源:Microsoft《ChatGPT for Robotics》,中金公司研究部
場景要素:適當容錯率與數據非私有化格外重要
我們總結CHATGPT類多模態大語言模型應用在機器人領域的場景需要具有四大要素:其中,工藝不涉及商業機密、容錯率偏高是必要條件;另外,編程標準化程度高、一次性初始化編程是可選條件。
圖表19:多模態大語言模型普遍以人工修正訓練為前提,編程標準化程度高、一次性初始化編程是理想應用場景
資料來源:《A Survey of Large Language Models》(Wayne Xin Zhao等,2023),中金公司研究部
► 工藝不涉及商業機密:大語言模型的動作指令代碼生成依賴於動作環節的可拆解、可輸入、可訓練,並可根據拆解的動作環節進行大數據預訓練,一旦動作過程涉及商業機密,將存在訓練數據源不足與商業機密泄露風險。我們認為to C端應用較to B端應用更適合落地。
► 容錯率偏高:大語言模型需要大數據生成式訓練及人工反饋打分,在許多場景初次應用時易存在錯誤率,尤其是在數據量&人工反饋糾偏不足的情況下。我們認為To C端應用容錯率較高,To B端工廠流水線生產普遍對錯誤率容忍度更低。
► 標準化程度高:非標場景接入大語言模型,需對每次非標設計部分進行動作拆解與人工反饋訓練,過程繁瑣,試用度不高。目前,大語言模型對工業生產流程等用到的數理公式尚不能舉一反三;我們認為生活場景用到的自然語言舉一反三能力或有望突破,也即未來在非標的生活場景下,大語言模型有望率先應用。
► 一次性初始化編程:非標場景下,存在某些產線的初始化一次性編程場景,生成式訓練與人工反饋糾偏僅發生一次,無需頻繁變化,則大語言模型代碼生成可顯著提高編程效率。例如,機器人整線的PLC流程編程。
圖表20:CHATGPT類多模態大語言模型應用落地四要素

資料來源:《A Survey of Large Language Models》(Wayne Xin Zhao等,2023),《Generating Situated Robot Task Plans using Large Language Models》(Ishika Singh等,2022),《Language models as zero-shot planners: Extracting actionable knowledge for embodied agents》(W. Huang等,2022)中金公司研究部
服務場景&移動機器人適合率先應用落地。我們按照容錯率高及商業機密含量低兩大必要條件篩選出適合「多模態大語言模型+機器人」應用落地的場景。我們認為家庭陪伴服務機器人、送餐快遞機器人、移動機器人、食品鞋服等行業分揀搬運機器人等場景容錯率偏高,且動作指令拆解過程不涉及商業機密、標準化程度高。例如命令機器人送餐,過程中所有的環節並不涉及機密,且送餐的路線具有一定容錯率。此外,售后運維環節機器人相比於生產線用機器人對於錯誤的容忍率更高,且對於大部分的機器人故障診斷而言,電氣、機械等核心部件的故障原理相似,一次性編程原理為主,不存在過多商業機密。
圖表21:容錯率高&商業機密含量少的應用場景適合接入CHATGPT類多模態大語言模型
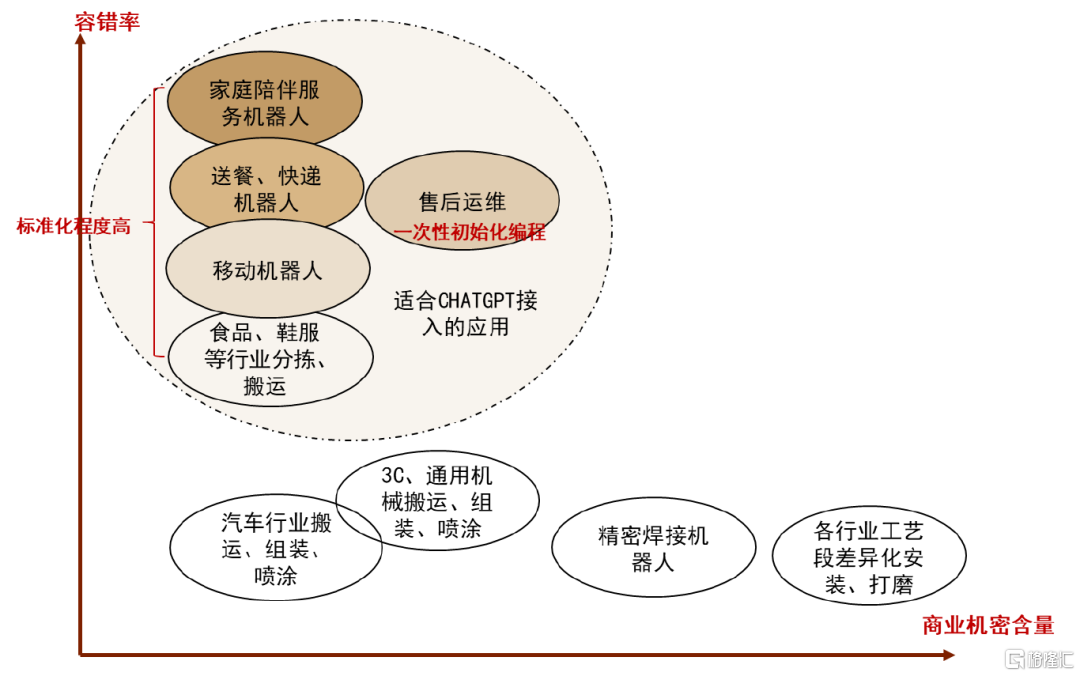
注:顏色越深越適合大語言模型融合落地
資料來源:中金公司研究部
落地難點:如何權衡商業機密與編程效率間的關係
我們認為多模態大語言模型對編程效率要求的提高,意味着降低了對商業機密與倫理的要求,這本身存在一種對立性。編程效率的提高意味着數據要儘可能開源、生產工藝要儘可能標準化、人工反饋環節要儘可能減少,但這恰好意味着商業機密要公開、市場競爭規律被抹平。甚至當數據訓練足夠成熟以后,大模型開始具有創造力,我們開始擔心機器倫理問題。我們認為編程效率與機密倫理的權衡對於多模態大語言模型大規模推廣至關重要。
圖表22:效率與倫理&商業機密性要求存在對立性
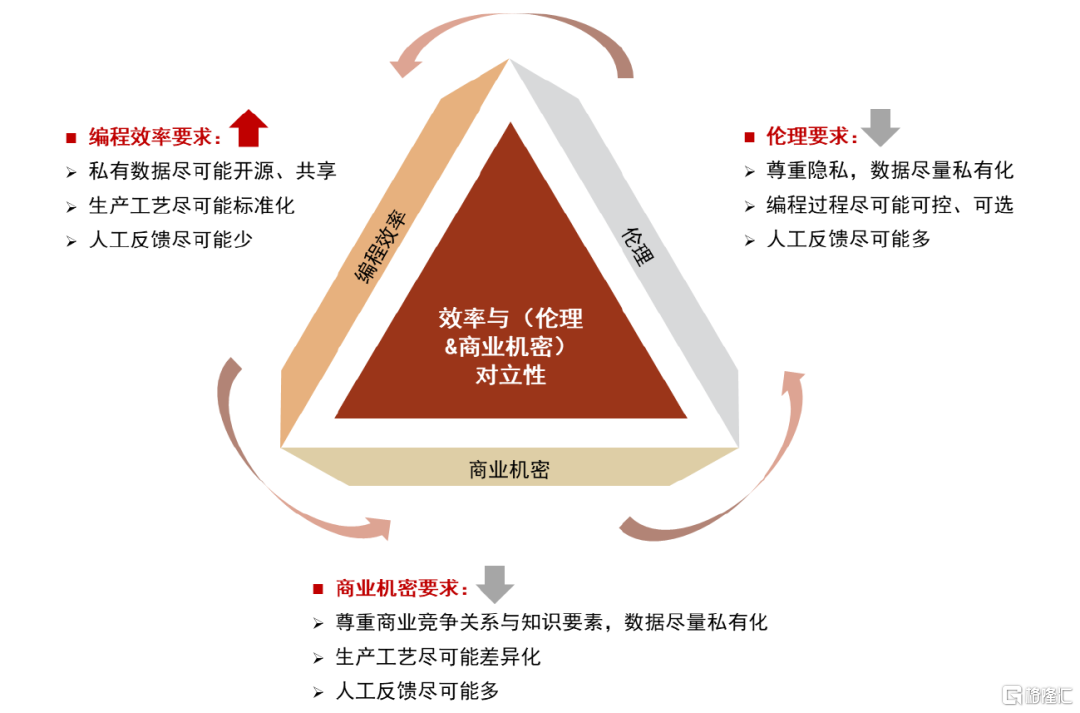
資料來源:《A Survey of Large Language Models》(Wayne Xin Zhao等,2023),中金公司研究部
此外,我們認為多模態大語言模型本身存在侷限性:
► 可信度:由於多模態大語言模型更多基於自然語言邏輯,在以數理為基礎的專業領域容易出現錯誤解析;此外,在不正確定義API(即驅動語令)或缺乏對其詳細説明情況下大語言模型易產生純文本回復,無法驅動機器人,也就是説對於操作者的技能及API接口的標準性都有一定要求。
► 時效性:多模態大語言模型是預訓練模型,對於可回答的知識範圍存在明顯時間邊界。
► 成本高:多模態大語言模型的部署、訓練成本較高,以CHATGPT為例,GPT-3訓練一次的成本約140萬美元,對於一些更大的訓練模型,成本介於200萬美元至1200萬美元之間。此外,我們以CHATGPT在1月獨立訪客數1000萬計算,其對應芯片需求為3萬片英偉達A100 GPU,每天運行成本約為100萬美元。
圖表23:chatGPT-3鉅額算力和成本需求
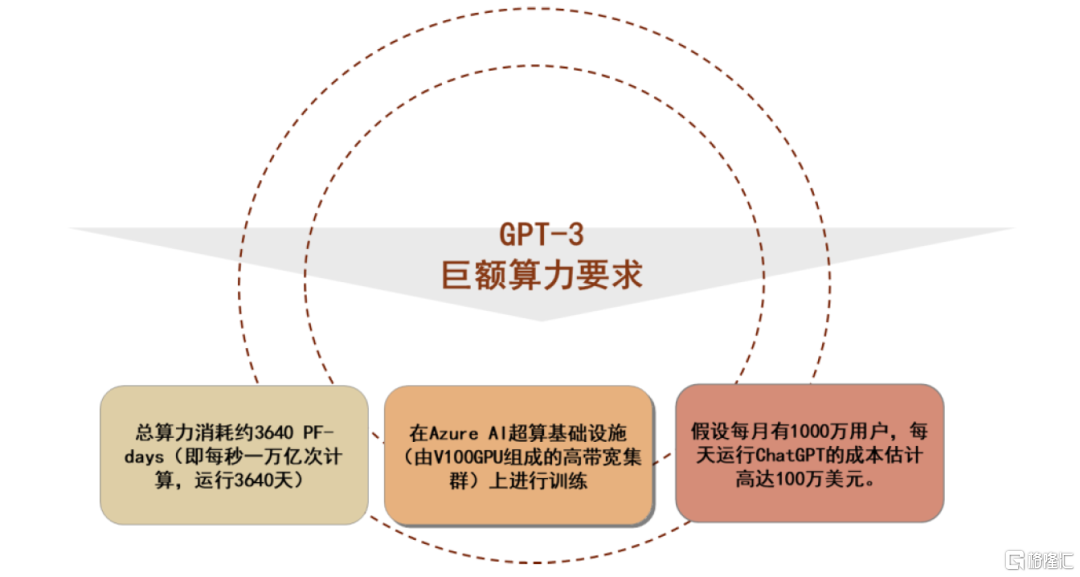
資料來源:《ChatGPT的運行模式、關鍵技術及未來圖景》(朱光輝等,2023),中金公司研究部
我們相信在未來充足的數據訓練前提下,可信度與成本不再是核心問題,多模態大語言模型在常識性、時效性要求不高的場景下會有較好應用。
格局衝擊:數據要素積累至關重要,機器人固有格局難打破
機器人的核心軟件能力可拆解為控制能力和工藝設計能力。工藝設計能力指的是對工藝生產步驟進行拆解設計,例如焊接動作會被拆分成瞄準測量、焊接方式的選擇、軌跡定位、送絲、二次檢查等,每個步驟對應一套自然語言指令;控制能力指的是根據工藝步驟的指令調控機器人進行動作落地。工藝設計過程更容易轉化為自然語言指令;控制過程更多體現為數理公式邏輯,目前該環節仍是大語言模型短板。因此,我們認為大語言模型+機器人應用可能會對機器人工藝設計能力的競爭格局產生一定影響;對於機器人企業控制器算法及硬件生產的競爭力影響不大。
圖表24:機器人企業核心競爭要素體現為工藝設計能力、控制能力以及硬件製造能力
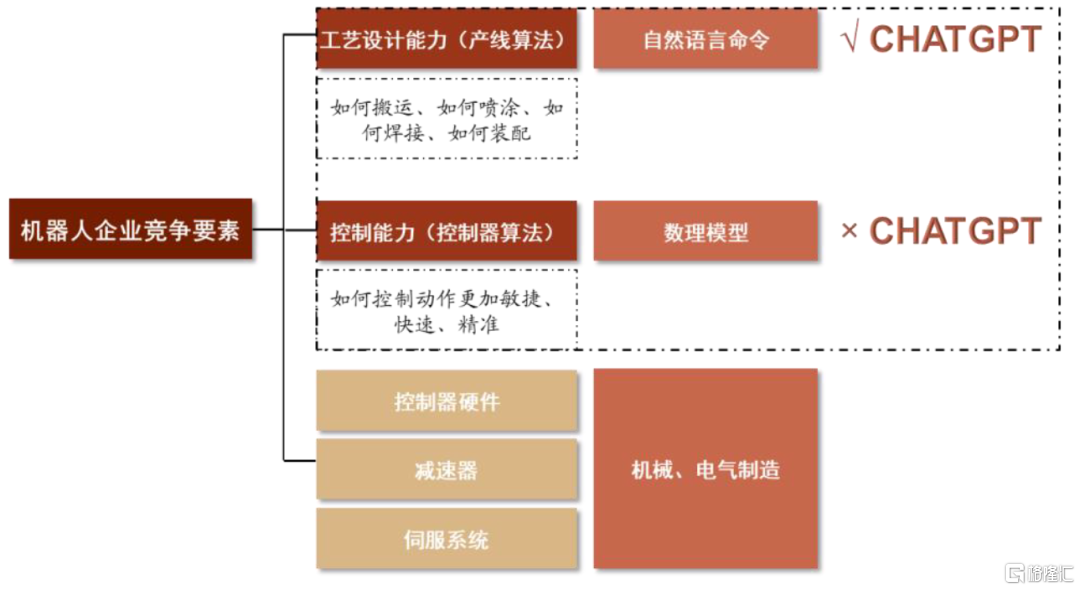
資料來源:《A Survey of Large Language Models》(Wayne Xin Zhao等,2023),《Inner monologue: Embodied reasoning through planning with language models》(W. Huang等,2022)中金公司研究部
我們認為可以在兩種假設下討論多模態大語言模型對機器人行業競爭格局的終局影響。假設一:數據私有化考慮,每家機器人企業獨立訓練大語言模型;假設二:為應對全球競爭(發那科等具有充分數據積累和訓練優勢的企業),國內各企業統一數據雲由國家級實驗室訓練大語言模型。
假設一:數據要素決定競爭力,固有機器人行業格局難改變
以工業機器人行業為例,從2022年競爭格局來看,發那科、ABB、安川、庫卡等銷量數據遠高於國產品牌數倍,即在搬運、碼垛、打磨、噴塗、焊接等各道工藝環節的數據要素積累充分,工藝設計能力的訓練效率及準確性或更優。我們認為在企業與企業間商業數據不完全打通背景下,數據要素是核心競爭力,固有格局較難打破。
圖表25:工業機器人全球競爭格局(2020年)
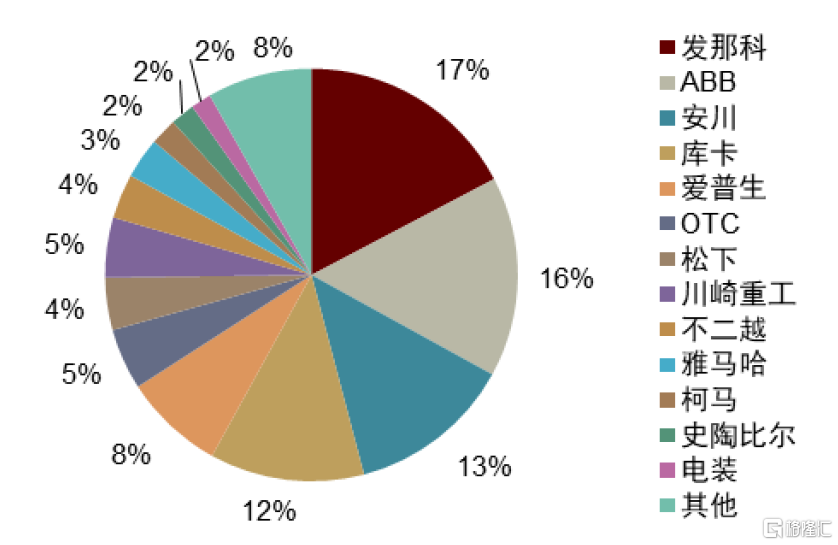
資料來源:IFR,中金公司研究部
圖表26:工業機器人中國競爭格局(2022年)
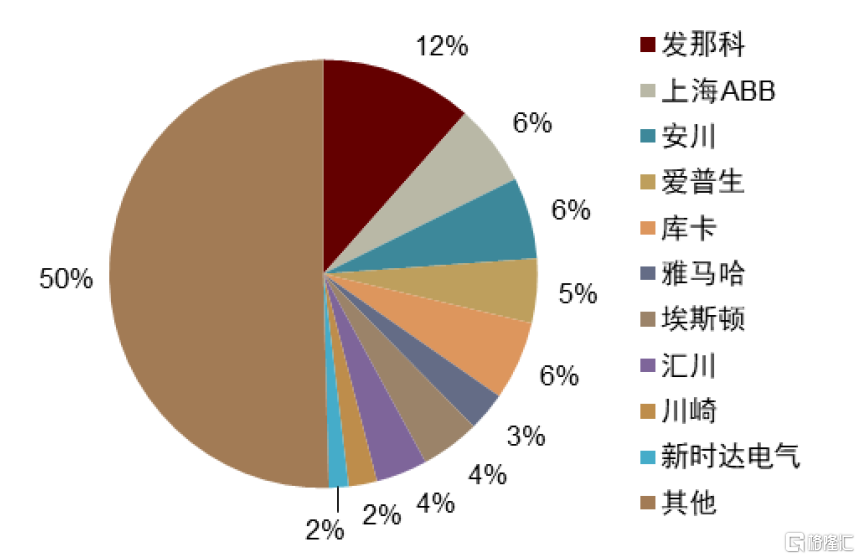
資料來源:MIR,中金公司研究部
假設二:工藝能力差距追平,控制與硬件製造能力成核心競爭力
我們假設長期來看,國內企業間數據流打通,可通過雲端共享工藝數據進行通用多模態大模型訓練,則國內企業在工藝設計環節數據積累量上有望與外資追平差距。彼時機器人本體企業的核心競爭力更多體現為控制能力與硬件製造能力,即如何讓運動變得更加高速、精準。但由於編程門檻降低,對於簡易編程、提供免費工藝包、拖拽示教的本體廠商而言一大競爭優勢或將被追平。
行業要求:第三方企業標準化接口或成行業應用落地風向標
我們認為第三方標準化API接口是基礎條件,只有這樣本體廠商才能形成標準公式語言,推廣效率有望進一步提升,但這對國產機器人企業提出更高要求:1)底層代碼實現自主化:API調度控制算法語言過程中,如果機器人企業內部沒有實現從控制器、操作系統、協議棧、軸插到視覺等一系列內部解耦,即內部算法的完全靈活改編調用,就無法靈活調動底層代碼進行更改與連接。目前,國內零部件底層尚未完全解耦,運動控制器廠家的底層運控內核不完全自主,尚存在黑箱現象。2)機器人本體制造能力強大:大語言模型助力企業在工藝設計能力方面差距縮小,這就將企業競爭點進一步聚焦到硬件製造的穩定性及本體整體系統設計能力上,從而要求國內企業的整機研發和製造能力加速提升。
風險提示
1)CHATGPT技術迭代速度慢於預期:以CHATGPT為代表的多模態大語言模型迭代速度不及預期,或影響其在機器人行業的應用落地速度,機器人相關公司的「AI+賦能」或延緩。
2)機器人零部件自主化進度不及預期:機器人零部件底層代碼尚不能實現完全解耦,則會進一步影響多模態大語言模型對機器人控制器及其他零部件的自由調度,機器人的自身編碼與智能化進步速度或受到限制。
注:本文摘自中金公司2023年4月17日已經發布的《AIGC新篇章:全球智能機器人時代前瞻》報告分析師:
分析員 郭威秀 SAC 執證編號:S0080521120004 SFC CE Ref:BSI157
聯繫人 王梓琳 SAC 執證編號:S0080121060117
分析員 陳顯帆 SAC 執證編號:S0080521050004 SFC CE Ref:BRO897
推薦文章
港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%

一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
一周IPO | 賺錢效應持續火熱!年內24只上市新股「0」破發;「圖模融合第一股」海致科技首日飆漲逾242%
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
美股機會日報 | 降息預期升溫!美國1月CPI年率創去年5月來新低;淨利、指引雙超預期!應用材料盤前漲超10%
財報前瞻 | 英偉達Q4財報放榜在即!高盛、瑞銀預計將大超預期,兩大關鍵催化將帶來意外驚喜?
