熱門資訊> 正文
芯片未來將如何製造?一文看懂巨頭們的佈局!
2023-02-03 11:40
- 應用材料公司(AMAT) 0
- 高通公司(QCOM) 0
- 英特爾(INTC) 0
本文來自格隆匯專欄:半導體行業觀察;作者:Dylan Patel
我們(指代本文作者Dylan Patel)最近參加了在舊金山舉行的第68屆年度 IEEE 國際電子設備會議。IEDM 是最先進的半導體器件技術的首屈一指的會議。在本屆會議上,包括英特爾、臺積電、三星、IBM、美光、欣興、日月光、應用材料等無數企業,IMEC、CEA-Leti等研究機構,再到多所大學在內的組織都展示了半導體的前沿技術。這里的前沿不僅僅指最先進的邏輯工藝,還包括存儲器、模擬、封裝等諸多領域。保持對本次會議的關注很重要,因為它展示的技術將導致設備、代工廠、無晶圓廠、設備和封裝等業務發生變化。
本文是關於 IEDM 上討論的許多進步、發展和研究的簡短系列的一部分,其中將涵蓋高級邏輯技術和高級封裝。本文將涵蓋 CFET——GAA晶體管的下一個演進、順序堆疊(Sequential Stacking)、LFET、應用材料無障礙鎢金屬堆疊(Barrierless Tungsten Metal Stack,)、三星混合鍵合邏輯 4um 和 HBM、ASE FoCoS、臺積電 3nm FinFlex 和自對準觸點、英特爾 EMIB 3 和 Foveros Direct、Qualcomm Samsung 5nm DTCO & Yield、IBM 垂直傳輸 FET (VTFET) 和 RU 互連等技術。
臺積電 FinFlex
在 IEDM 2022 上,臺積電談到了 N3B 和 N3E 。在關於N3E的論文中,臺積電介紹了FinFlex。這是進入 N3 節點系列的巨大設計技術協同優化 (DTCO) 的一部分。FinFlex 是一種高級形式的鰭減少( fin depopulation)。通常,隨着鰭的減少,標準單元中 NMOS 和 PMOS 鰭的數量會減少。這允許降低電池高度,從而提高密度。有了更先進的節點,每個鰭片還可以承載更多的驅動電流,允許鰭片數量減少而對性能的影響很小。
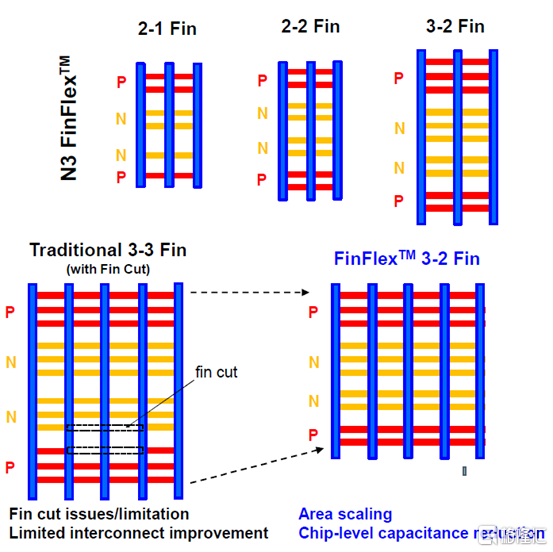
然而,隨着單元(cell)高度的降低,互連成為一個更具限制性的因素。對於1-fin cell,幾乎沒有互連空間,互連幾乎肯定會成為唯一的瓶頸。對於 FinFlex,使用 2-1 fin 設置,其中 1 fin cell堆疊在 2 fin cell的頂部。這有助於緩解互連瓶頸並有效地產生高度為 1.5 fins的cell。藉助 N3E,臺積電提供了三個庫,一個用於高密度的 2-1 單元庫,一個用於平衡功率和性能的 2-2 單元庫,以及一個用於高性能的 3-2 單元庫。
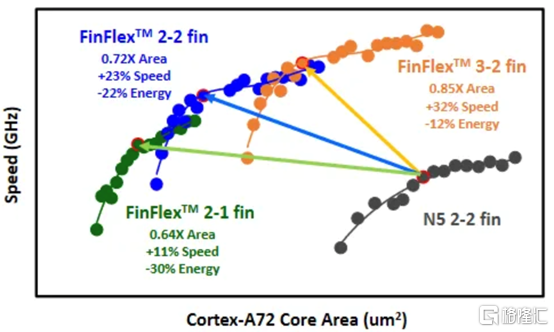
據臺積電稱,2-1 單元庫( cell library)在相同性能下功耗降低 30%,在相同功率下性能提高 11%,並且相對於其 N5 節點上的 2-fin 庫面積減少 36%。2-2 單元庫在 iso-performance 下功耗降低 22%,iso-power 性能提高 23%,面積減少 28%。3-2 單元庫提供低 12% 的功耗 iso-performance、高 32% 的性能 iso-power 和 15% 的面積。
N3E 還提供 6 種閾值電壓(threshold voltage )選項,eLVT、uLVT、uL-LVT、LVT、L-LVT 和 SVT。每一種都在功率和性能方面進行了不同的權衡,並允許設計人員更精確地調整它們的功率性能特性。
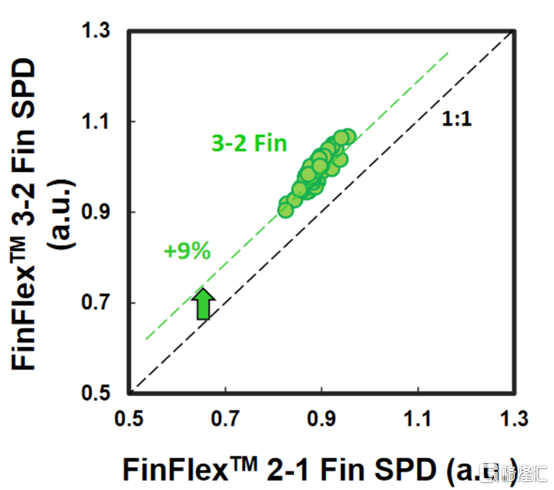
比較 2-1 和 3-2 cell時,臺積電顯示 3-2 cell的性能高出 9%。除非設計人員絕對需要這種性能,否則性能上的提升是微乎其微的。這加強了更密集、更節能的圖書館的理由。但是,這忽略了互連密度限制。FinFlex 使設計人員能夠使用密度較低的單元(例如 2-2 和 3-2 單元)實現最高密度,以最大限度地提高互連佈線和性能。
N3E 的金屬堆疊雖然比 N3B 略微放松,但仍然非常緻密。metal 0 的間距為 23nm,比 N5 減少了 18%。metal 0還提供雙倍寬度,以實現更低的電阻和更高的性能。

臺積電在銅互連中加入了創新的liner,以降低較低金屬層的電阻。我們相信這種liner是釕,英特爾也在其 10nm 節點中用作liner。接觸電阻降低了 20-30%,通孔電阻降低了 60%。臺積電還提到,在 N3B 上需要使用 EUV 進行雙圖案化的三個關鍵層已被在 N3E 上使用 EUV 進行單圖案化所取代。這降低了複雜性、成本並縮短了周期時間。
N3E 在今年晚些時候進入大批量生產時,將成為生產中最先進的節點。臺積電將繼續在邏輯前沿佔據主導地位。像 FinFlex 這樣的創新表明臺積電正在鋭意進取。
TSMC 3nm 自對準觸點
(Self-Aligned Contacts N3B)
自從臺積電在 N16 上過渡到 FinFET 以來,鰭的輪廓對於提高性能和降低功耗至關重要。儘管臺積電能夠將柵極長度從 N7 上的 16-23nm 減少到 N3B 上的 12-14nm,但臺積電也提到柵極長度縮放已達到極限。即使採用鰭片優化,臺積電也無法進一步降低這一點。這進一步強調了設計技術協同優化 (DTCO) 對於進一步擴展到未來的重要性。此外,有人提到 FinFET 晶體管架構已達到極限,必須轉向納米片晶體管架構。
通過 N3B,臺積電還實施了自對準觸點 (SAC:Self-Aligned Contacts)。這非常有趣,因為英特爾從 22nm 開始就開始實施 SAC。同時,臺積電第一個採用該技術的節點是N3B。此外,他們還刪除了 N3E 中的 SAC。
由於接觸多晶硅間距和柵極長度之間的比例差異,接觸的着陸面積已顯着縮小。更嚴格的對齊公差和由多個掩模引起的重疊問題加劇了這種情況。
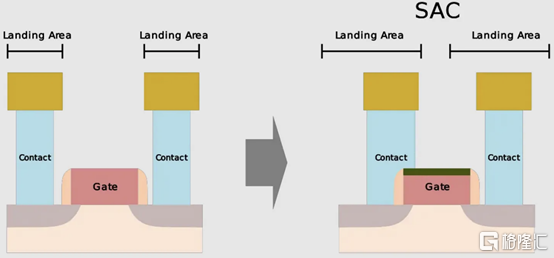
SAC 使觸點甚至可以落在柵極頂部而不會使晶體管短路。雖然這增加了工藝複雜性並因此增加了成本,但它提高了良率。不幸的是,隨着gate-SD接觸電容顯着增加,它也會影響性能。
臺積電在 N3B 上的方案允許柵極接觸結處的泄漏保持恆定,即使在更寬的柵極長度和工藝變化(其中接觸和柵極與柵極的不同部分對齊)也是如此。SAC 還將接觸電阻降低了 45%,將變化降低了 50%。這允許更好的靜電和性能,以及更高的製造產量。

隨着柵極和接觸之間的間隙不斷減小以及由於 FinFET 結構,臺積電面臨着增加柵極接觸結處電容的問題。雖然較厚的墊片可以緩解這個問題,但這會帶來其他問題,例如更高的接觸電阻。不可避免地,臺積電希望降低介電常數並使用低 k 材料。儘管空氣的 k=1 很有前途,但臺積電的 TCAD 模擬表明,與切換到 k<4.0 的電介質相比,它的影響更小。這將最大電壓提高了 200mV 以上,並將結點處的電容降低了 2.5%。這些只是優化新工藝技術時可能被忽視的一些次要細節。
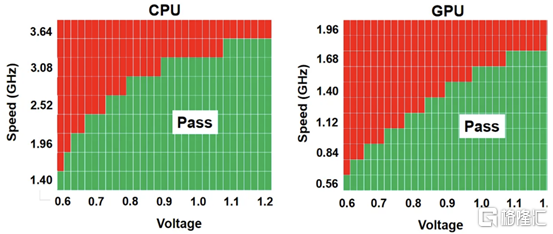
臺積電還在其 N3B 節點上展示了測試芯片的 shmoo 圖,其中顯示 CPU 核心在 1.2V 時達到 3.5 GHz,GPU 核心在 1.2V 時達到 1.7 GHz。他們還展示了芯片中 SRAM 的 shmoo 圖,該芯片在低至 0.5V 時仍能正常工作。
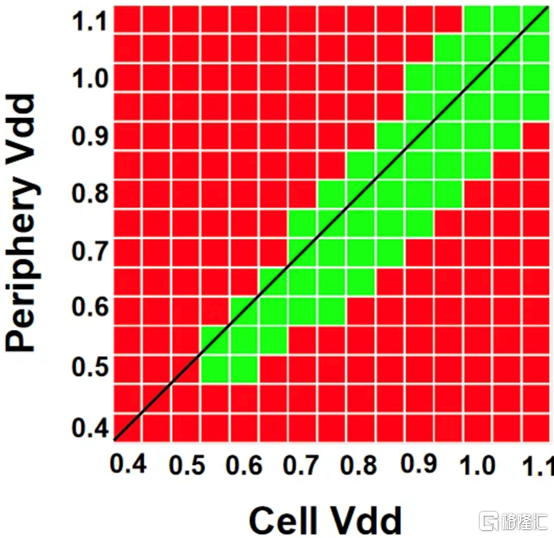
高通和三星 DTCO
在IEDM上,高通和三星還談到了三星5LPE節點上搭載驍龍888的DTCO。高通表示,最小的鰭間距 (FP)、CGP、金屬間距和 SRAM 位單元用於實現比 7LPP 縮小 25%。這些變化可以在 5LPE 的 Ultra High-Density 庫中看到。然而,這些收縮也伴隨着工藝風險的增加。
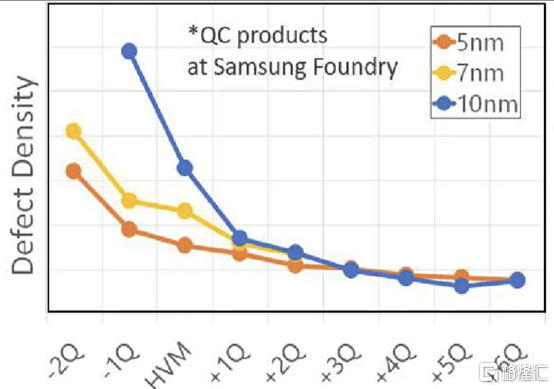
從開始到初始生產,三星減少了 60% 的缺陷,並通過大批量製造進一步將其減少到基準的 2%。5LPE 也經歷了出色的產量提高,比 10LPE 和 7LPP 更快。部分原因還在於 5LPE 是對 7LPP 的增量改進。
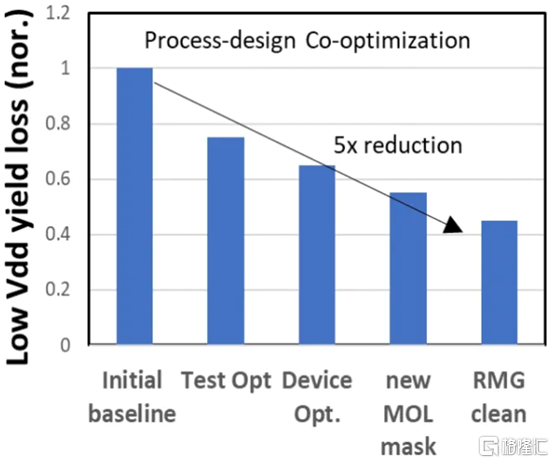
高通和三星還與 DTCO 合作大幅提高良率,將低電壓操作的良率損失降低 2.5 倍,這是移動 SoC 的主要用例。他們還將有缺陷的設備數量減少了 9 倍,這非常重要。
通過持續的 DTCO,高通和三星還將 CPU 功耗降低了 7%,總功耗降低了 3%。隨着工藝節點縮放速度變慢,DTCO 對於實現芯片的理想特性將變得越來越重要。
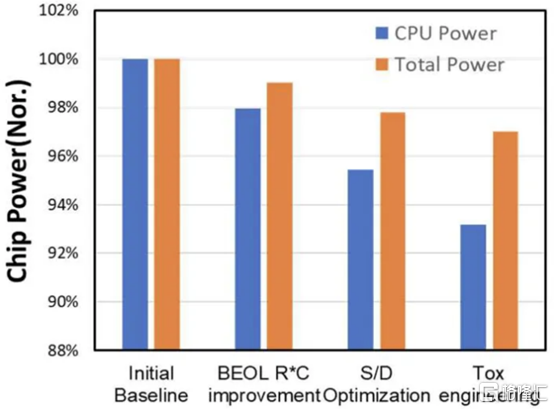
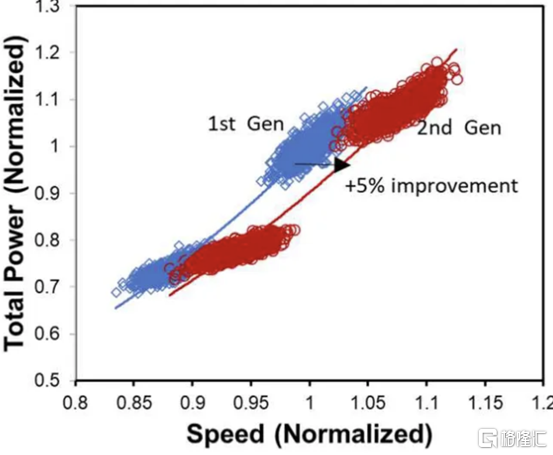
三星還將他們的第一代節點 5LPE 與他們的第二代節點 5LPP 進行了比較。他們表明,它在相同功率下實現了 5% 的更高性能。5LPP 也用於 Snapdragon 8 Gen 1,以 4LPX 的名義銷售。
先進的邏輯技術:晶體管架構
在 Gate All-Around FET (GAAFET) 和 Forksheets 之后,該行業可能會轉向互補 FET (CFET),其中 NMOS 納米片堆疊在 PMOS 納米片之上,反之亦然。這是一個困難的過程,因為 P 型和 N 型的形成需要非常高温的外延生長。無論您製作第 2 個,都會導致第 1 個暴露在高温下,這可能會破壞它。臺積電、英特爾、IMEC都對此進行了研究。爲了製造 CFET,有兩種方法,sequential 和 monolithic.。
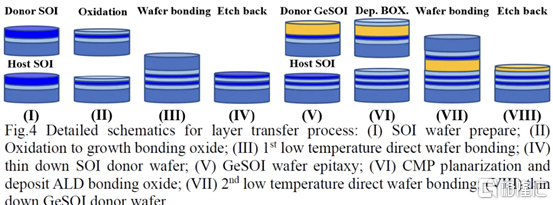
一、通過直接晶圓鍵合與 Ge Nanosheet p-FET 組成的的異質 3D Sequential CFET
韓國高等科學技術研究院提出了一種Sequential CFET 製造方法。KAIST 通過採用順序堆疊方法解決了温度問題,在這種方法中,他們執行高温外延生長,然后通過晶圓間鍵合將它們單獨組合在一起。底部 pFET 由 Ge 組成,而頂部 nFET 由 Si 組成。

這種新方法允許具有更高電子遷移率的 Ge 晶格更優選的取向。在最近的前沿節點中,pFET 的驅動電流問題尤其嚴重,這是緩解該問題的一種方法。經過測試,添加頂部 nFET 的過程不會影響底部 pFET 的電氣特性。
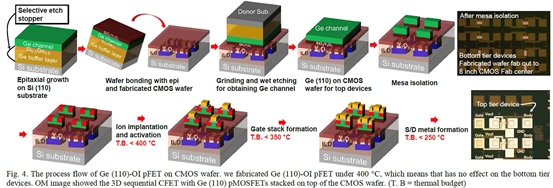
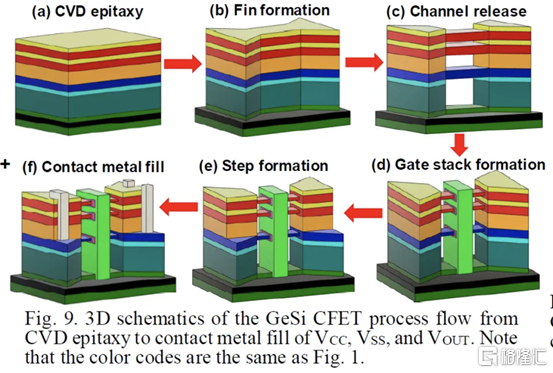
二、通過 CVD 外延生長的單片 3D 自對準 GeSi 溝道和共柵極互補 FET
國立臺灣大學展示了他們在單片 CFET IE 方面的工作,無需晶圓鍵合。這可以通過低温(400C)外延生長來實現,這將防止先前製造的結構被破壞。他們用 75% Ge 和 25% Si 製造了 SiGe 溝道,並使用 P/N 結隔離 CFET 的兩半。通過他們的方法,他們能夠成功地將兩個 pFET 通道堆疊在 1 個 nFET 通道之上。
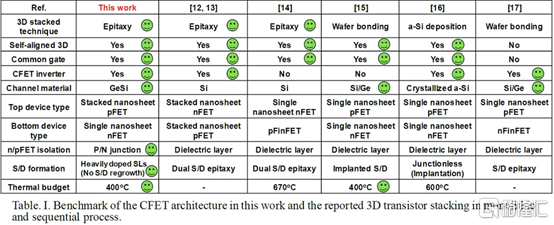
雖然之前已經展示了堆疊式 nFET 上的堆疊式 pFET,但這是第一次展示帶有 P/N 結的 pFET,而且該工藝似乎對源極和漏極的形成影響很小。他們聲稱這比以前的方法更容易實施。
三、IBM 垂直傳輸納米片
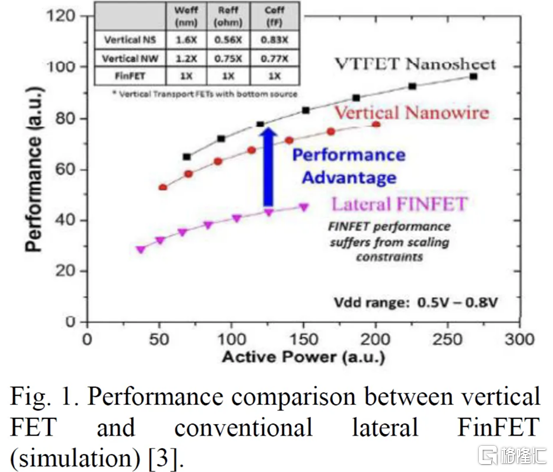
與業內其他公司不同,IBM 尋求一種不同的方法,採用不同的晶體管架構,一種使用垂直納米片。這種架構被稱為垂直傳輸 FET (VTFET)。
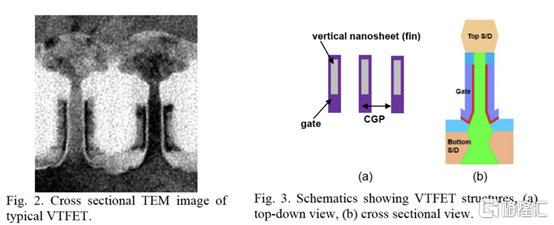
這種方法的一個優點是它允許 CGP 微縮得更多。使用常規晶體管架構將 CGP 擴展到 40nm 以上將被證明是極其困難的,並且可能會在電阻和電容方面進行過多的權衡。IBM 之前曾在 2021 年的 IEDM 上展示過 VTFET。
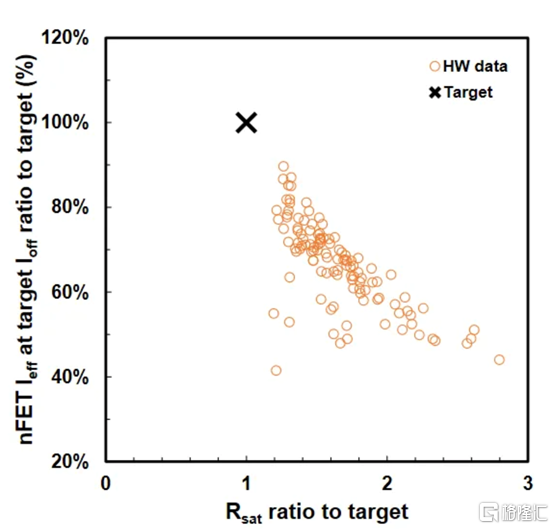
這次他們展示了 CGP 為 40nm 的 VTFET,使用雙擴散中斷。他們還表示,零擴散中斷設計是可能的。儘管 IBM 能夠製造此類 VTFET,但他們發現電容比模擬高 20%,驅動電流低於預期,最佳芯片為目標的 90%。
IBM 通過轉向這種架構展示了與垂直納米線相比令人印象深刻的性能改進。
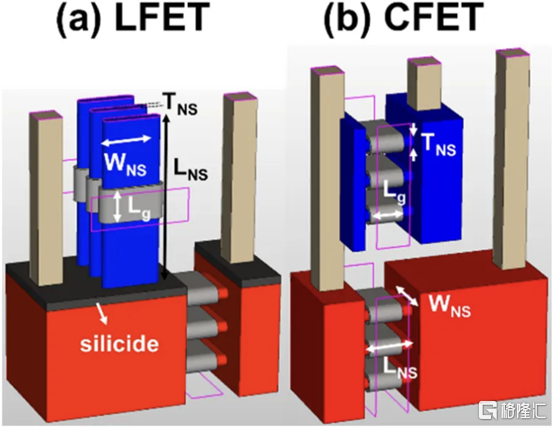
四、用於埃技術節點的異構 L 形場效應晶體管 (LFET)
幾所臺灣大學展示了一種新的晶體管架構,即 LFET。在某些方面,這是 IBM 的 VTFET 和 CFET 的組合。pFET 垂直放置在水平放置的 nFET 之上。LFET 中的「L」不代表任何東西,它只是這個結構的形狀。LFET 在密度方面的改進較少,但它們更易於實施,也更容易調整。與柵極的接觸也可以更容易地形成。
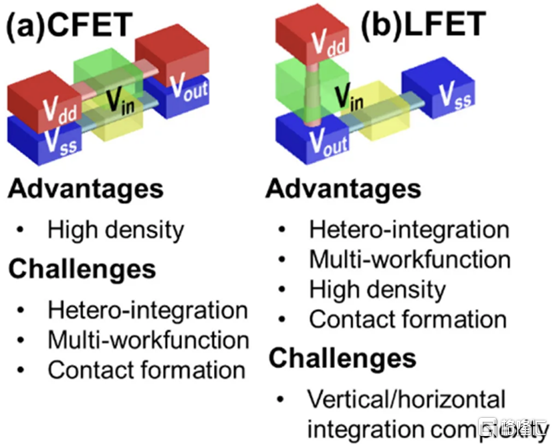
這些器件使用 3 個 PMOS 和 3 個 NMOS 納米片進行模擬。LFET 的壓降略高。但是,它們的功耗和電阻也較低。
先進的邏輯技術:晶體管架構
金屬堆疊的縮放在每個芯片設計中都至關重要,因為它通常是限制因素。然而,最近的技術進步阻礙了金屬堆疊的縮放。當電流通過金屬互連時,它會產生熱量並導致金屬原子流動,稱為電遷移。隨着時間的推移,這種流動會導致空隙和小丘,導致設備電阻增加,並最終導致故障。
隨着電流密度的增加,銅互連尺寸的縮小加劇了這個問題,導致更大的熱量產生和電遷移,以及互連與晶體管開關相比更多的功率損耗。為解決這個問題,引入了氮化鉭勢壘,但隨着互連不斷縮小,勢壘尺寸越小,在較低金屬層中所佔的比例就越大,從而阻礙了縮放工作。
在 Intel 的 10nm 和 Intel 7 節點中,鈷被用於最底層的金屬堆棧,儘管這已經在 Intel 4 中退回了。Ruthenium 也被用於他們的 10nm 和 7nm 節點中,並且越來越成為每個人都希望採用的材料超過。
一、IBM Subtractive Ru Interconnect 由用於 EUV 雙圖案化的新型圖案化解決方案和帶有嵌入式氣隙集成的 TopVia 實現,用於后 Cu 互連縮放
IBM Research 和三星展示了他們使用釕 (Ru) 代替銅的新型互連。Ru 與鈷很像,不需要勢壘並且可以縮放到更小的寬度,而不會獲得天文數字的電阻和電容。
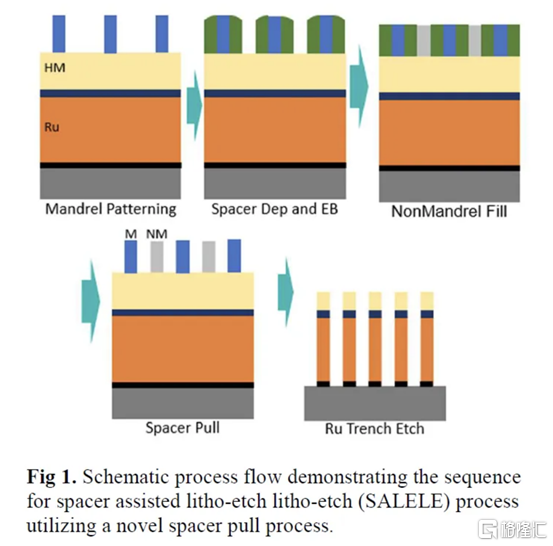
儘管可以使用類似於銅的雙鑲嵌工藝製造 Ru 互連,但他們在這項新研究中使用了減法圖案化。這需要使用帶 EUV 的間隔輔助 LELE (SALELE)。這使他們能夠形成金屬間距為 18 納米的互連,比臺積電 N3E 上的 MMP 減少了 22%。
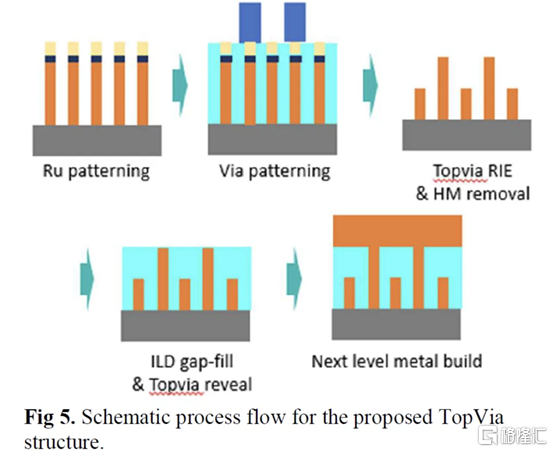
它們還具有 4:1 的高縱橫比,以增加電容為代價降低了 20% 的電阻。由於 SALELE 在互連頂部的金屬層之間構建通孔,因此用空氣填充導線之間的空間要容易得多,這是 ak=1 時可用的最佳電介質。與 k<2.7 的低 k 電介質相比,這是一個顯着的變化,可以將電容降低 30% 以上。
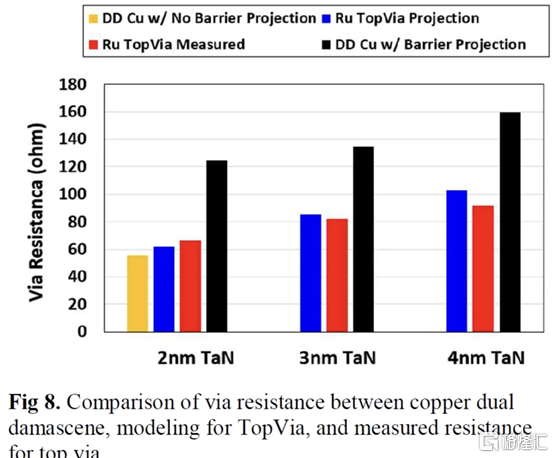
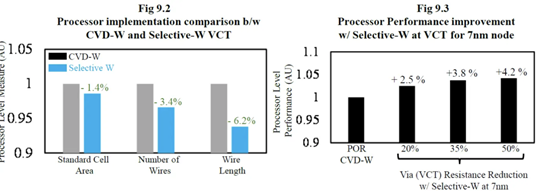
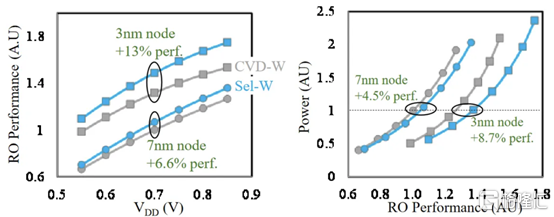
二、Applied Materials Tungsten MOL 局部互連創新:材料、工藝和系統協同優化 3nm 節點及更高節點
Applied Materials 還展示了他們使用鎢 (W) 的新互連。目前,鎢是通過化學氣相沉積 (CVD) 沉積的,並具有由氮化鈦製成的阻擋層。由於 3D NAND,Lam Research 在鎢沉積方面的市場份額處於領先地位,但 Tokyo Electron 和 Applied Materials 也在運營。這項新研究展示了不需要襯墊的選擇性 W。當使用鎢時,目前的襯里通常是 TiN。
如果這項技術成功,它可以在所有高級邏輯節點中採用,這對應用材料公司來説將是一個巨大的利好。
與 Ru 非常相似,這很可能是允許未來互連擴展的候選者。通過這項新的創新,他們能夠將通孔和鏈條電阻降低 40%。
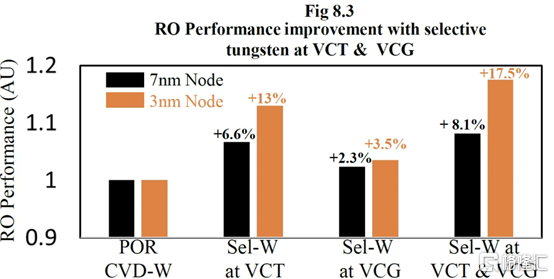
他們還表明,該工藝可使相同電壓下的性能提高多達 13%,在相同功率下性能提高 8.7%,標準電池面積減少 1.4%。像這樣的小創新複合在一起,以保持半導體縮放的輪子轉動。
這對於具有背面供電網絡的未來設備的信號側互連具有巨大潛力!
高級邏輯技術:靜態隨機存取存儲器 (SRAM)
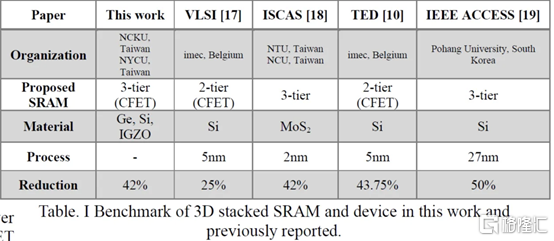
一、具有雙層轉移 Ge/2Si CFET 和 IGZO 傳輸門的 3-D 異構 6T SRAM 的集成設計和工藝,可將單元尺寸縮小 42%
正如臺積電的 N3E 工藝所示,SRAM 縮放變得異常困難。雖然持續的收益將繼續難以實現,但 SRAM 有一些最后的技巧。向 GAAFET 和 CFET 的轉變應該能夠使 SRAM 大幅縮小,每個縮小 30-40%。臺灣多所大學展示了一種帶有 CFET 的 SRAM 位單元設計,該設計僅使用 2 個晶體管的面積來構建 6 晶體管 SRAM 位單元。他們通過順序堆疊實現了這一點。
有了這個,他們能夠將面積減少 42%。根據他們的研究,新的 bitcell 設計在空閒時消耗的功率減少了 100 倍!
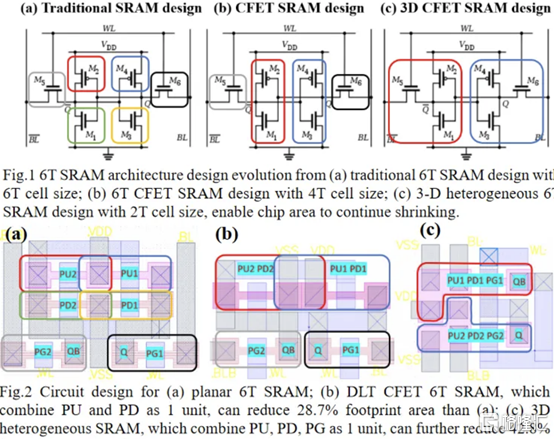
與轉移到 3D 領域的其他潛在 SRAM 新設計(包括來自 IMEC 的設計)相比,這是非常有趣的。鑑於臺積電的 N3E 沒有 SRAM 微縮,這項研究至關重要。
先進封裝
臺積電、英特爾和三星在 IEDM 上提供了他們先進封裝技術的更新。隨着前沿節點的成本進一步增加,先進封裝只會變得越來越重要。
一、TSMC使用有機中介層 (CoWoS-R) 的異構和小芯片集成
臺積電對 CoWoS-R 進行了一些小更新。儘管這主要是對現有信息的重申,但臺積電表示他們可以採用 2μm/2μm 或 1μm/1μm 的 L/S 進行封裝。他們還展示了它被用於將 HBM3 鏈接到小芯片。

二、英特爾 EMIB 3
英特爾展示了其兩種封裝技術,EMIB 和 Foveros Direct。憑藉其第三代 EMIB,EMIB 顯着將其貼裝精度提高了 3 倍以上。藉助新工藝,在為 TCB 工藝加熱時,die的移動量也減少了約 50%。他們還展示了帶有使用 AIB 2.0 的 FPGA 封裝。根據 DARPA CHIPS 計劃,使用 36 μm的第三代 EMIB 連接到 Texas Instruments 的模擬前端芯片。根據顯示的橫截面,L/S 似乎是 2μm/2μm,與 2016 年 ECTC 的論文相當。這比他們的產品(如 Stratix 10 和 Sapphire Rapids)中的 5μm/5μm L/S 有所改進.
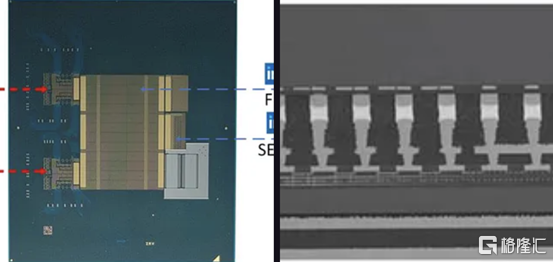
他們還在實際論文中展示了一些提高良率的技術。
三、Foveros 直接重組晶圓鍵合晶圓
英特爾第一代Foveros Direct 的間距為 9μm,密度比使用微凸塊的 Foveros 提高了 4 倍。第二代的間距為 3μm,密度又提高了 4 倍。當然,這些是最小間距,正如AMD 在 Zen 3 上的 3D V-Cache 技術所展示的,最小間距並不總是被使用。如果英特爾能夠堅持其路線圖並兑現承諾,它可能會趕上臺積電的第 4代SoIC ,同樣是 3μm 的間距。
據英特爾稱,第 2代將效率提高了約 20%。他們還聲稱這將允許近乎整體的設計,幾乎沒有或沒有功率、面積和延迟開銷。我們覺得這很難相信,但進一步擴大規模將有助於這三個領域。最后,英特爾還展示了一些芯片系統的概念,該芯片系統使用多種不同的封裝方法並堆疊了很多層。
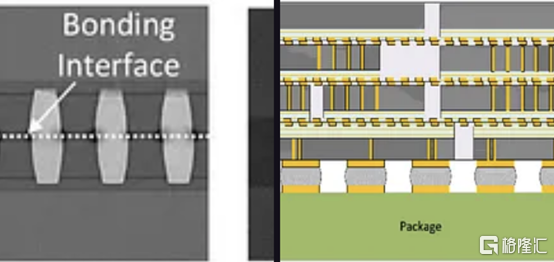
英特爾的工藝最有趣的地方在於它是一種重組晶圓鍵合晶圓。
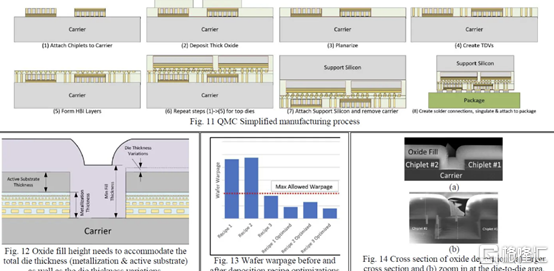
他們將其稱爲準單片芯片 (QMC)。
四、三星先進封裝、混合鍵合邏輯4umm和混合鍵合HBM
一段時間以來,三星在先進封裝領域一直處於落后狀態,其封裝解決方案未能獲得重大關注,儘管他們正在大力投資以爭取份額。它的 X-Cube 計劃在 2024 年投產,採用微凸塊,比臺積電和英特爾落后多年,而在 2026 年採用混合鍵合,又比臺積電和英特爾落后多年。他們的封裝解決方案以 Advanced Packaging Fab Solutions (APFS) 為品牌。
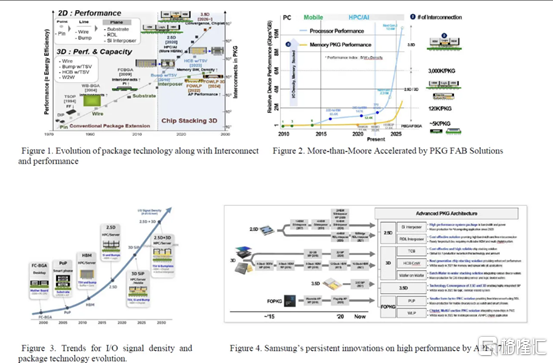
I-Cube 是三星的硅中介層技術,類似於 CoWoS-S 。第 4代支持 8個HBM 封裝和 3 倍光罩尺寸,比臺積電晚了大約 1 年。據說下一代支持 12 HBM 封裝和 4x 標線尺寸。三星還展示了採用混合鍵合的 12Hi HBM,這是他們在 2021 年實現的。提醒一下,SK 海力士在 2021 年公開展示了採用混合鍵合的 16Hi HBM。
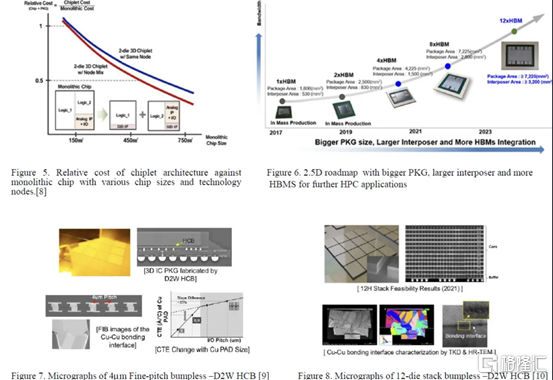
我們預計百度仍將是唯一使用這些技術的大客户。三星的混合鍵合 X-Cube 被證明具有 4μm 間距,如果到 2026 年投產,這可能會大大縮小差距。但是,它很可能只會在晚些時候投產。

五、用於小芯片設計和異構集成封裝的 Unimicron 混合基板
欣興還展示了一些先進的封裝。他們在 PID 和 ABF 基板上使用了 55μm 的微凸點間距,並對它們進行了比較。他們展示了一個 3 金屬層設計,每個金屬層具有不同的間距和線/間距,分別低至 3μm 和 2/2μm。雖然這種封裝與 TSMC 或 Intel 的 HVM 相比沒有那麼先進,但它仍然表明 OSAT 正在研究自己的解決方案。

Unimicron 是 Intel、AMD 和許多其他公司的基板供應商。
六、面向小芯片和異構集成的 ASE 先進封裝技術平臺
近年來,日月光一直在改進其封裝選擇組合,以保持與臺積電和其他公司的競爭力。在 IEDM 上,他們提供了許多封裝選項的摘要。Fanout Chip on Substrate (FOCoS) 有多種形式,例如 FOCoS-Chip First (FOCoS-CF) 和 FOCoS-Chip Last (FOCoS-CL)。這些之間的區別類似於臺積電對CoWoS 和 InFO的區分。
FOCoS-CF 支持 4 個重分佈層 (RDL),線距/間距為 2/2μm。他們展示了一個test vehicle,在 47.5x47.5mm 2封裝上有兩個 30x28mm 2芯片。FOCoS-CL 具有 4 層具有相同線/間距的 RDL。它具有 55μm 的微凸點間距,類似於英特爾 Sapphire Rapids 中 EMIB 的間距。所示的測試車輛有一個尺寸為 30x28mm 2的 ASIC 裸片,以及在 47.5x47.5mm 2封裝上的兩個 HBM 堆棧。

ASE 還展示了 FOCoS-Bridge (FOCoS-B)。這涉及使用嵌入式硅橋,線/間距小至 <0.8/0.8μm。他們的網站聲明它下降到 0.6/0.6μm。我們認為 FoCoS-B 是 SPIL 在被 ASE 收購之前開發的 FOEB 的重命名版本。他們的測試車輛展示了具有 0.8/0.8μm 線/間距的 FoCoS-B。它有 2 個 ASIC 芯片和 8 個 HBM2e 堆棧。

推薦文章
華盛早報 | 史上最大IPO!SpaceX 6月12日上市,估值衝向1.77萬億美元;再次增持!泡泡瑪特「二老闆」段永平持股比例突破6%;中興、騰訊將合作發佈AI雲電腦

時間定了!6月12日SpaceX上市交易,發行價135美元,計劃籌資750億美元成有史以來規模最大的IPO
6月4日外盤頭條:美伊緊張局勢再度加劇 SpaceX目標IPO定價135美元 特朗普政府調整進口銅關税規則
不止邁威爾科技!黃仁勛點名超30只「AI工廠」產業鏈公司,年內最高已搶跑480%漲幅
6月金股一圖睇完 | 騰訊領銜「科網老登」集體反彈?科指月內累漲4%,機構稱AI仍為核心增長引擎!
華盛早報 | 光通信利好連發!國產技術重要突破 + 邁威爾引爆美股+ 英偉達硅光量產;微軟聯手英偉達重新發明電腦;SpaceX擬定價135美元
6月3日外盤頭條:特朗普簽署AI行政令加強政府監管 微軟發佈全新AI模型 SpaceX要求壓低IPO承銷費率
港股盤中持續拉昇!恆指漲超1.4%,科指漲超3.5%;美團績后漲超8%,騰訊漲超7%,比亞迪股份漲逾5%
