熱門資訊> 正文
眼見不一定為實,AI苦練騙人術
2022-11-01 10:18
是否想象過上課或開會的時候,找到一個替身替自己坐在那里聽課、開會? 想必很多人都不止一次想過這一畫面,而今這一幻想就要成真了。

近期,海外一家創業公司開啟了一項新業務引起了不少人的關注,初創企業 EmbodyMe 宣佈開啟全新服務xpression camera Voice2Face,為客户提供網絡會議中的虛擬人像。 據悉,這一應用會提供與參會者毫無二致的虛擬形象,通過 AI 系統的加持,還能實現表情、動作與發言者的互動,還可以自定義角色服裝、發型等。 EmbodyMe社的高管吉田一星表示,xpression camera Voice2Face專門針對網會疲勞現象開發,可以切實解決宂長網會中醬油角色們的疲勞和憂傷。
01 虛擬人崛起
EmbodyMe的xpression camera Voice2Face功能從本質上來説屬於虛擬數字人技術,與此前新華社的虛擬主播、某銀行的虛擬員工同宗同源。
虛擬數字人的廣義定義為數字化外形的虛擬人物,具有「虛擬」(存在於非物理世界中)+「數字」(由計算機圖形學、圖形染、動作捕捉、深度學習、語音合成等計算 機手段創造及使用)+「人」(具有多重人類特徵,如外貌、人類表演/交互能力等)的綜合產物,打破物理界限提供擬人服務與體驗是其核心價值。
其中「人」(外形看起來像)是其中核心的因素,高度擬人化(行為看起來像)為用户帶來的親切感、參與感、互動感與沉浸感是多數消費者的核心使用動力。 能否提供足夠自然逼真的相處體驗,是虛擬數字人在各個場景中取代真人重要標準。
按應用場景來分,虛擬數字人可虛擬偶像、虛擬分身、虛擬助手、多模態助手等等,其中虛擬偶像較易實現,一般通過計算機以遊戲引擎製作並輸入預定的語音與動作即可,例如初音未來、洛天依等等; 而虛擬分身則一般需要掃描捕捉人體特徵與動作,再在計算機中實時生成形象; 最后就是虛擬助手與多模態助手了,這兩者基本上都屬於自動化的範疇了,無論是在形象上還是在交互上,有更為「以假亂真」。
本次EmbodyMe的xpression camera Voice2Face功能既是虛擬分身又是虛擬助手之間,説它是虛擬分身是因為xpression camera Voice2Face能夠滿足個人在虛擬世界中為自己創造獨特形象的身份需求,又説它是虛擬助手則是因為xpression camera Voice2Face可以在對交互要求相對簡單的場景下應用替代真人,比如代替你開無效的視頻會議。
不過當前所有虛擬數字人都存在一個共同的問題——呆。 數字虛擬人最終效果受到語音合成(語音表述在韻律、情感、流暢度等方面是否符合真人發聲習慣)、NLP技術(與使用者的語言交互是否順暢、是否能夠理解使用者需求)、語音識別(能否準確識別使用者需求)等技術的共同影響,所以xpression camera Voice2Face即便在AI技術的加持下看起來比較自然,但稍微問個問題xpression camera Voice2Face就原形畢露了。
02 AI是關鍵
除了前面提到的能夠幫助人們在無效視頻會議(僅支持ZOOM)中摸魚外,通過Xpression Camera的官網我們還發現,Xpression Camera還支持在 Twitch 上直播或在創建 YouTube 視頻,Xpression Camera能夠實現以上功能背后則離不開一個名為Voice2Face AI技術。
據悉,Voice2Face技術是FACEGOOD(量子動力)在2022年年初開源的一項關於語音驅動三維人臉的項目(https://github.com/FACEGOOD/FACEGOOD-Audio2Face),該技術可以將語音實時轉換成表情blendshape動畫。
值得注意的是,FACEGOOD主要完成Voice2Face部分,ASR,TTS由思必馳智能機器人完成。 如果你想用自己的聲音,或者第三方的ASR,TTS可以自行進行替換。 當然FACEGOOD Audio2Face部分也可根據自己的喜好進行重新訓練,比如你想用自己的聲音或其它類型的聲音,或者不同於FACEGOOD使用的模型綁定作為驅動數據,都可以根據下面提到的流程完成自己專屬的動畫驅動算法模型訓練。
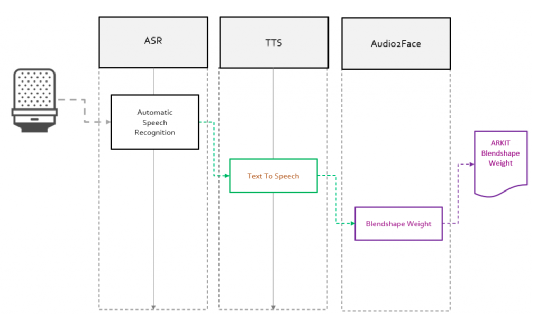
Voice2Face的具體工作原理如下:第一階段,數據採集製作。這里主要包含兩種數據,分別是聲音數據和聲音對應的動畫數據。聲音數據主要是錄製中文字母表的發音,以及一些特殊的爆破音,包含儘可能多中發音的文本。而動畫數據就是,在maya中導入錄製的聲音數據后,根據自己的綁定做出符合模型面部特徵的對應發音的動畫;第二階段,主要是通過LPC對聲音數據做處理,將聲音數據分割成與動畫對應的幀數據,及maya動畫幀數據的導出;第三階段,將處理之后的數據作為神經網絡的輸入,然后進行訓練直到loss函數收斂既可。
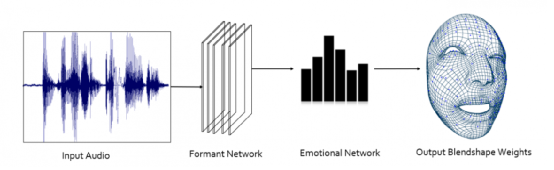
其實本質上Voice2Face屬於 Audio2Mesh 路線,即語音直接預測mesh序列信息。 除此之外等效的還有一種,Audio2ExpressionCoefficient,語音預測表情係數或者blendshape係數,最后在進行線性相加合成mesh序列。 但無論使用何種方法,能夠根據語音實時生成相應的表情並賦予給虛擬形象,以此來實現視頻會議中的「摸魚」,背后都離不開AI的功勞,未來隨着AI技術的進一步發展,AI「欺騙」人類的那天越來越近了。
本文來自微信公眾號「Techsoho」(ID:scilabs),編輯:Light,出品:科技智谷,36氪經授權發佈。
推薦文章
美股機會日報 | 阿里發佈千問3.5!性能媲美Gemini 3;馬斯克稱Cybercab將於4月開始生產

港股周報 | 中國大模型「春節檔」打響!智譜周漲超138%;鉅虧超230億!美團周內重挫超10%
一周財經日曆 | 港美股迎「春節+總統日」雙假期!萬億零售巨頭沃爾瑪將發財報
一周IPO | 賺錢效應持續火熱!年內24只上市新股「0」破發;「圖模融合第一股」海致科技首日飆漲逾242%
從軟件到房地產,美國多板塊陷入AI恐慌拋售潮
Meta計劃為智能眼鏡添加人臉識別技術
危機四伏,市場卻似乎毫不在意
財報前瞻 | 英偉達Q4財報放榜在即!高盛、瑞銀預計將大超預期,兩大關鍵催化將帶來意外驚喜?
