热门资讯> 正文
谷歌突破性算法震惊硅谷 华尔街激辩:内存需求要降温了?
2026-03-26 12:49
财联社3月26日讯(编辑 刘蕊)美东时间周二,谷歌发布了一个炸裂硅谷科技圈的最新算法:超高效AI内存压缩算法TurboQuant。

谷歌声称,这项算法可以在在不损失准确性的前提下,将大型语言模型运行时的缓存内存占用至少减少6倍、性能提升8倍,本质上,可以让人工智能在占用更少内存空间的同时记住更多信息。
这一算法一经发布,美股芯片股应声下挫。谷歌和华尔街也掀起了一场热烈讨论:当前困扰众多科技巨头的内存芯片短缺灾难是否可以就此终结了?
TurboQuant是什么?
先来说说这项TurboQuant算法具体是什么。
根据谷歌在官方网站的介绍,TurboQuant是一种压缩方法,它能够在不损失任何精度的前提下大幅减小模型大小,因此非常适合支持键值缓存(KV Cache)压缩和向量搜索。它通过两个关键步骤实现这一点:
1、高质量压缩(PolarQuant method):TurboQuant 首先随机旋转数据向量。这一巧妙的步骤简化了数据的几何结构,使得可以轻松地将标准的高质量量化器分别应用于向量的每个部分。第一阶段利用了大部分压缩能力(大部分比特)来保留原始向量的主要概念和特征。
2、消除隐藏误差:TurboQuant 使用少量剩余的压缩能力(仅1比特)将QJL算法应用于第一阶段遗留的微小误差。QJL 阶段充当数学误差检查器,消除偏差,从而获得更准确的注意力评分。
简单来说,TurboQuant本质上就是在保持AI模型核心结构不变的情况下压缩AI模型,而且无需预处理或特定的校准数据。
谷歌声称,他们使用开源的长上下文模型(Gemma和Mistral ),在包括LongBench、Needle In A Haystack、ZeroSCROLLS、RULER和L-Eval在内的多项基准测试中,对 TurboQuant、PolarQuant 和KIVI这三种算法进行了严格评估。
实验数据表明,TurboQuant在点积失真和召回率方面均达到了最优评分性能,同时最大限度地减少了键值(KV)内存占用。
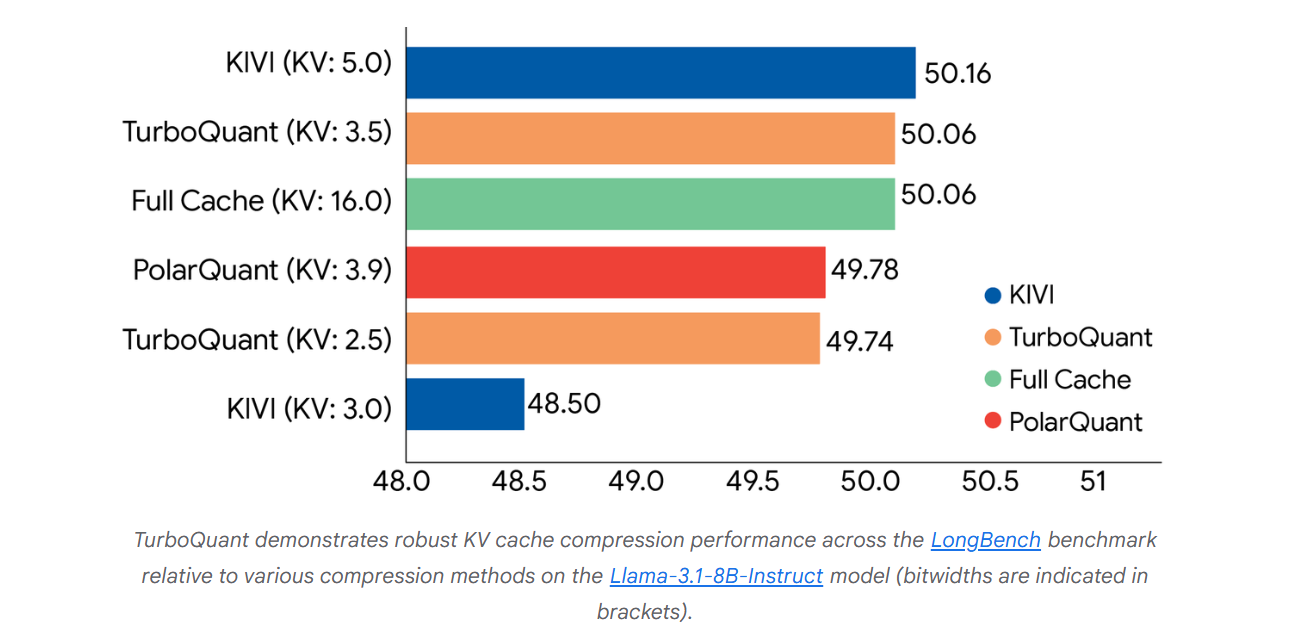
上图展示了TurboQuant、PolarQuant 和KIVI基线算法在问答、代码生成和摘要等不同任务中的综合性能得分。
谷歌称,TurboQuant在所有基准测试中均取得了完美的下游结果,同时将键值内存大小至少减少了6倍。
他们计划在下个月的ICLR 2026会议上展示他们的研究成果,以及展示实现这种压缩的两种方法:量化方法PolarQuant和名为QJL的训练和优化方法。
谷歌迎来DeepSeek时刻?
谷歌的这一算法,令不少人联想到了HBO电视剧《硅谷》(2014年至2019年播出)中虚构的创业公司Pied Piper。在电视剧中,Pied Piper同样开发出一种突破性的压缩算法,能在近乎无损压缩的情况下大幅减小文件大小。
而现实中的谷歌研究院发布的TurboQuant技术,同样致力于在不损失质量的前提下实现极致压缩,但它应用于人工智能系统的核心瓶颈。
Cloudflare首席执行官Matthew Prince等人甚至称之为谷歌的DeepSeek时刻,认为其有望像DeepSeek一样,通过极高的效率收益大幅拉低AI的运行成本,同时在结果上保持竞争力。
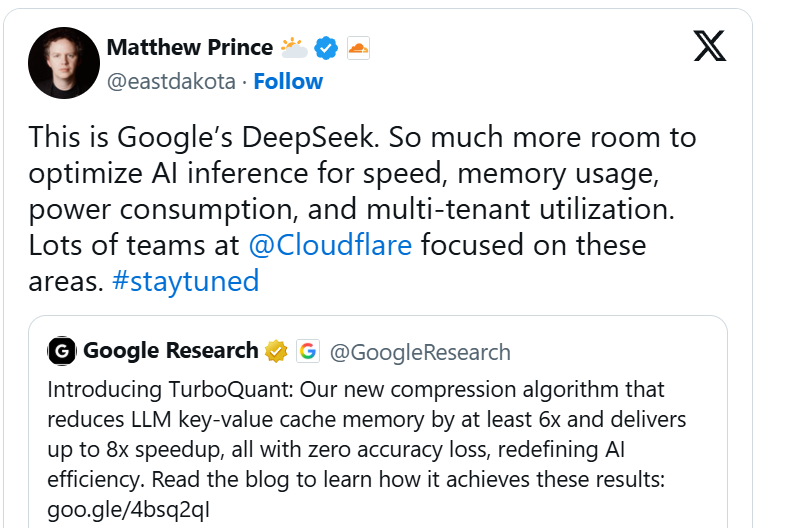
他在X上的一篇文章中写道:“在速度、内存使用、功耗和利用率方面,AI推理还有很大的优化空间。”
内存芯片需求将会降温?
谷歌的这一算法发布之际,正值全球存储芯片短缺问题日趋严峻的时刻。
由于全球各大巨头全力兴建AI基础设施,内存需求不断攀升,供不应求的现象短期内难以缓解。各大科技公司开发人员已经想出各种创新方法来克服或至少应对内存短缺,而谷歌的TurboQuant,目前被科技界人士认为,很可能成为一种给内存需求降温的可持续方案。
这一预期对于致力于建设AI基础设施的科技巨头们来说,自然是一件好事。但对于内存芯片厂商们来说,可能结果就不同了。
受到内存需求可能降温预期的影响,美东时间周三,美股存储芯片板块在开盘后不久就集体跳水:闪迪一度跌6.5%,美光科技跌4%,西部数据跌超4%,希捷科技跌超5%。
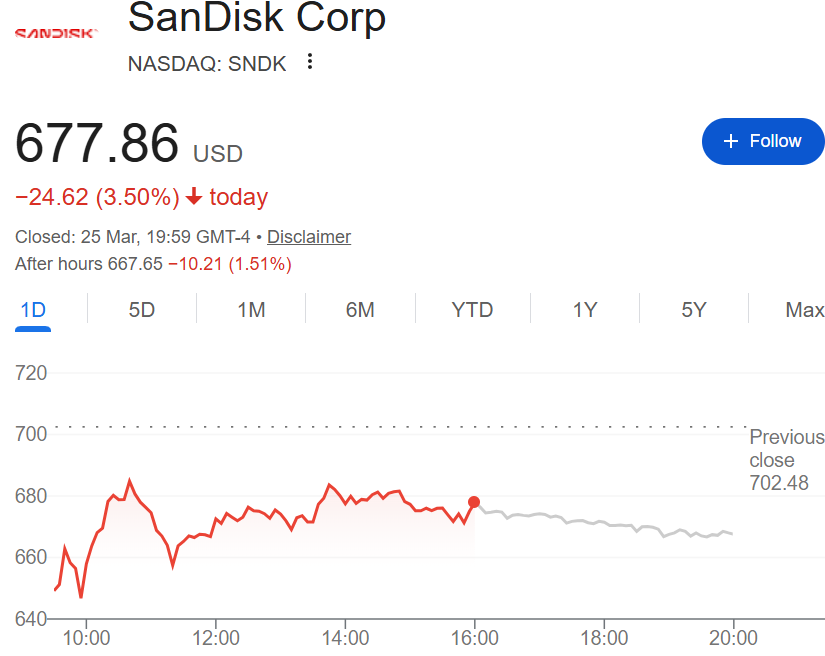
闪迪周三早盘一度大跌
周四亚洲时段,截至发稿时SK海力士下跌4.42%,三星跌3.02%。
Futurum股票研究部门的Shay Boloor声称:
“市场认为这对内存类股票来说是一个潜在的不利因素,因为长上下文AI推理每个工作负载可能需要的内存现在可能大幅减少。”
大摩提出相反观点
不过,也有华尔街巨头提出了相反的看法。
比如,Lynx Equity Strategies分析师KC Rajkumar就提出,TurboQuant的技术“颠覆性”可能并没有媒体描述的那么夸张。
他表示,谷歌所谓的“8倍性能提升”是建立在与老旧的32-bit模型对比之上的,然而当前的推理模型早已广泛采用4-bit量化数据,因此性能提升幅度并没有那么夸张。
此外,摩根士丹利还指出,谷歌TurboQuant技术仅作用于推理阶段的键值缓存,不影响模型权重所占用的HBM,也与训练任务无关。
因此,这并非存储总需求或硬件总量减少6倍,而是通过效率提升增加单GPU吞吐量——相同硬件可支持4至8倍更长的上下文,或在不触发内存溢出的前提下显著提升批处理规模。
更重要的是,摩根士丹利进一步援引了“杰文斯悖论”(Jevons Paradox),来解释内存需求不会降温的判断。
杰文斯悖论是经济学中的一个重要概念,指的是技术进步与资源消耗之间的一种反直觉关系。其定义是:当技术进步提高了效率,资源消耗不仅没有减少,反而激增。例如,瓦特改良的蒸汽机让煤炭燃烧更加高效,但结果却是煤炭需求飙升。
摩根士丹利认为,通过大幅降低单次查询的服务成本,TurboQuant能够让原本只能在云端昂贵集群上运行的模型迁移至本地,有效降低AI规模化部署的门槛,这可能反而能进一步提振整体需求。
实际上,Cloudflare首席执行官Matthew Prince等人提到的DeepSeek,就是杰文斯悖论的最鲜明例子:在DeepSeek去年年初刚刚发布时,市场也一度担忧AI硬件需求将会降温,但事实是,效率的提升带来了AI应用的进一步普及,AI硬件需求也再次升温。
推荐文章
年中盘点|港股爆升榜Top10出炉!AI产业链“霸榜”,智谱飙涨近16倍,极致分化中港股下半年如何布局?

华盛早报 | 美股全线大涨!纳指反弹逾2%,SpaceX考虑向特朗普账户捐赠股票;立讯精密、三环集团等9只新股今起招股
新股申购 | 珞石机器人一手入场费3838.32港元; “果链” 巨头立讯精密一手入场费6391.82港元
苹果的“印度梦”遭遇重击:核心供应商被黑,iPhone 18 Pro机密文件被挂暗网
美股前瞻 | 特朗普称美伊会谈明天召开!纳指期货升逾1%;太空概念股RKLB大涨12%,豪掷80亿美元收购铱星通讯;康卡斯特飙升22%
新股申购 | 6只新股今启招股!基本半导体一手入场费6387.78港元,中国自动驾驶公司MOMENTA-W一手入场费5971.62港元
iPad、Xbox接连涨价 折射出存储芯片短缺之痛
港股周报 | 阿里巴巴单周重挫15%!一众科网股继续“寻底”;南方两倍做多海力士ETF规模一度超盈富基金
