热门资讯> 正文
200万上下文窗口创飞Gemini 1.5!微软来砸谷歌场子了
2024-02-24 19:07
- 微软(MSFT) 0
- 谷歌-A(GOOGL) 0
- 谷歌-C(GOOG) 0
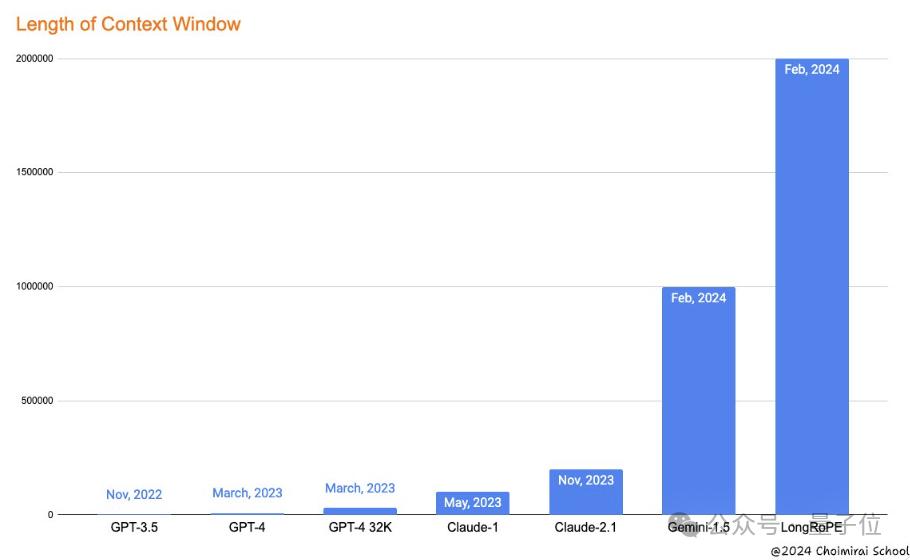
谷歌刚刷新大模型上下文窗口长度记录,发布支持100万token的Gemini 1.5,微软就来砸场子了。
推出大模型上下文窗口拉长新方法——LongRoPE,一口气将上下文拉至2048k token,也就是200多万!
并且1000步微调内,即可完成从短上下文到长上下文的扩展,同时保持原来短上下文窗口性能,也就是说训练成本和时间又省了一大笔。
网友看不下去了,直呼“谷歌太惨了”:
此外值得一提的是,这次LongRoPE为纯华人团队,论文一作Yiran Ding,就读于杭州电子科技大学,于实习期间完成该项工作。

LongRoPE究竟长啥样?先来看一波测试效果。
拿LLaMA2和Mistral试试水
上下文窗口有效拉长,语言模型长文本理解能力可以得到很大提高。研究人员在LLaMA2-7B和Mistral-7B上应用LongRoPE,从三个方面评估了其性能。
第一项测试是在长文档上评估扩展上下文语言模型的困惑度。
在256k以内的评估长度上,研究人员使用Proof-pile和PG19数据集来进行测试。
LongRoPE在4k-256k的文本长度上,整体上显示出困惑度下降的趋势,优于基准。
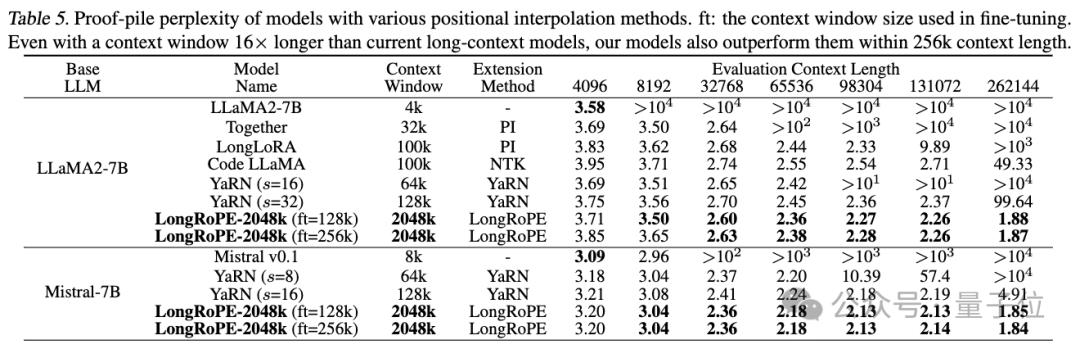
LongRoPE在Proof-pile数据集上的表现
即使在上下文窗口长度是标准长度16倍的条件下,LongRoPE-2048k模型在256k上下文长度内也超过了最新基线水平。
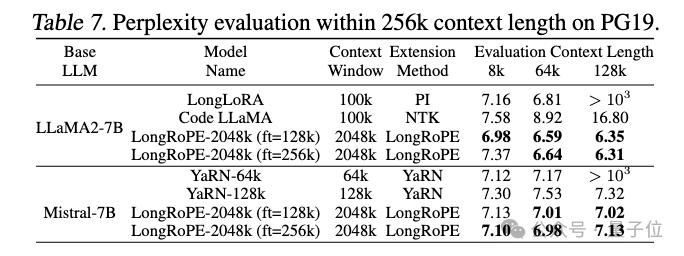
LongRoPE在PG19数据集上的表现
接下来上难度,从Books3数据集中随机选取20本书,每本长度超2048k,使用256k的滑动窗口。
研究人员观察到2048k的LLaMA2和Mistral之间性能差异显著。
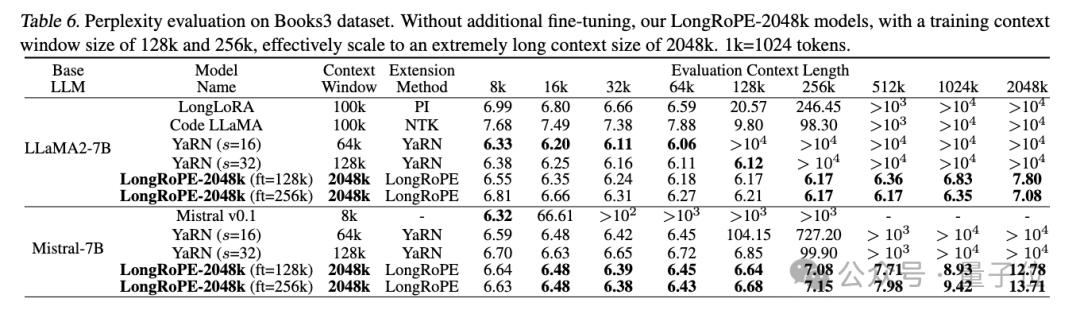
在8k-128k的文本长度上二者均取得了与基线相当的或更优的困惑度。LLaMA2的困惑度随着文本长度的增加而逐渐下降,在1024k和2048k长度处略有上升,展示了较好的性能。
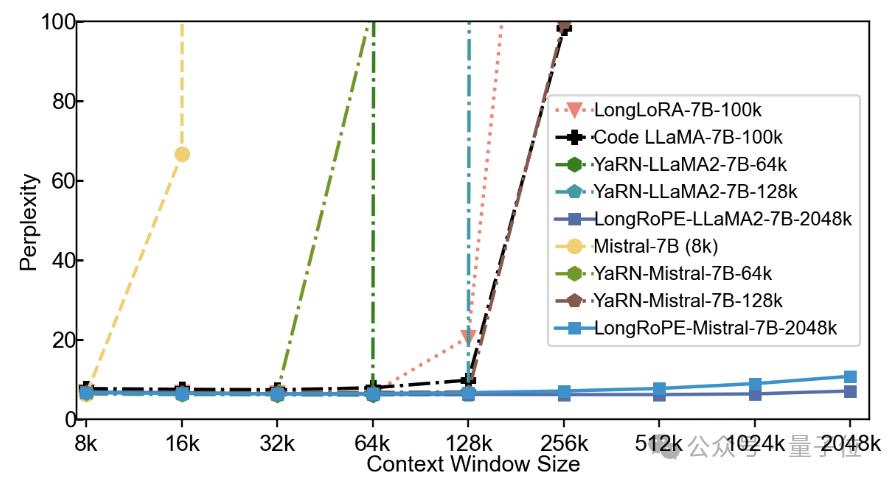
不过,Mistral在较短的长度上胜过基线,但当文本长度超过256k时,其困惑度急剧上升。研究人员分析,主要原因是对于Mistral的微调采用了与YaRN相同的设置,即使用16k长度的文本进行训练,导致了模型难以有效处理更长的文本。
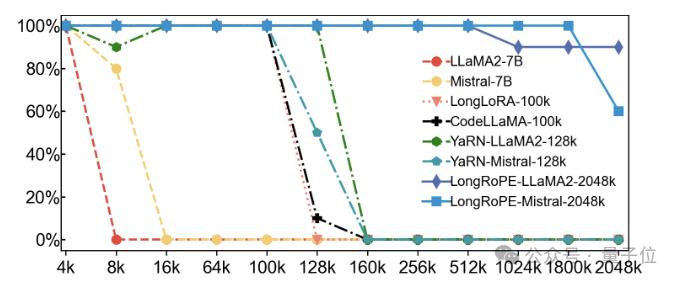
第二项测试是用Passkey检索任务评估在海量无关文本中检索简单密钥的能力。
也就是在很长的文本中随机隐藏一个五位数的密码,让模型找出这个密码。
结果显示,现有模型的准确率在文本超度超128k后迅速下降到0。
而LLaMA2-2048k在4k-2048k文本范围内保持了90%以上的检索准确率,Mistral-2048k在1800k之前保持了100%的准确率,在2048k时准确率下降到60%。
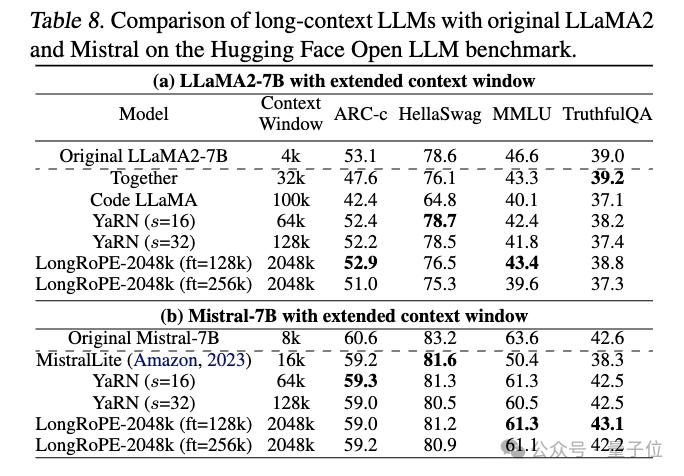
第三项测试是在短4096上下文窗口长度内的标准大语言模型基准测试上评估。
这项测试,主要是为了检验模型上下文窗口被扩展后,在原有任务上的表现会不会受到负面影响。
LongRoPE-2048k模型在原始上下文窗口大小的任务上,与原始模型相比表现相当。
在TruthfulQA上,扩展后的Mistral比原始高出0.5%;LLaMA2性能略微下降,但在合理的范围内。
这是如何做到的?
三大法宝扩展上下文窗口
LongRoPE可以有效扩展模型上下文窗口关键有三:非均匀位置插值、渐进式扩展策略、短上下文窗口性能恢复。
非均匀位置插值
位置嵌入(Positional Embeddings)在Transformer架构中,用于帮助模型理解长句中token的顺序。
位置嵌入通常是预先定义的,并与模型的其他参数一起训练,当模型需要处理的文本长度超过其训练时的上下文窗口时,新出现的token的位置就需要新的位置嵌入。
而LongRoPE通过识别并利用位置嵌入中两个形式的非均匀性,即不同的RoPE维度和token位置,优化了位置嵌入,不用微调就能实现8倍的上下文窗口扩展。
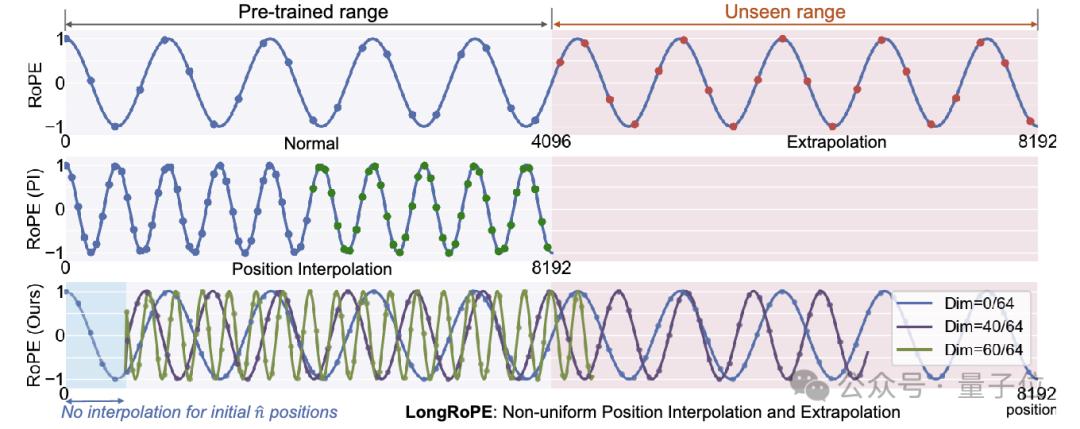
这种方法通过有效的搜索算法来确定每个RoPE维度的最佳缩放因子,针对每个RoPE维度的旋转角进行了重新缩放,同时也考虑了token位置的影响。
这样,模型在扩展上下文窗口的同时,能够更好地保留关键的维度和位置信息,减少信息损失。
渐进式扩展策略
此外,LongRoPE采用了一种渐进式扩展的方法。研究人员先对预训练的大模型进行微调,使其适应256k长度的文本。
然后,在微调后模型基础上进行搜索,找到新的位置插值参数以重新缩放RoPE,最终实现2048k上下文窗口,这个过程无需额外微调。
短上下文窗口性能恢复
在RoPE(旋转位置编码)中,超长上下文窗口会使得原始窗口内的维度被迫聚集在更小范围内,从而影响模型性能。
为此,研究人员调整了短上下文窗口RoPE的重缩放因子,使其与长上下文时不同,缓解了性能下降的问题。
通过这种动态调整机制,LongRoPE在处理极长文本和处理短文本时都表现良好。
LongRoPE发布后,部分网友认为RAG恐面临淘汰:
不过也有质疑的声音:
那么,你怎么看?
免责声明:以上内容仅代表作者的个人立场和观点,不代表华盛的任何立场,亦并非旨在提供任何投资意见。有关内容不构成任何专业意见、买卖任何投资产品或服务的要约、招揽或建议。本页面的内容可随时进行修改,而本公司毋须另作通知。本公司已尽力确保以上所载之数据及内容的准确性及完整性,如对上述内容有任何疑问,应征询独立的专业意见,本公司不会对任何因该等资料而引致的损失承担任何责任。以上内容未经香港证监会审阅。
推荐文章
华盛早报 | 特朗普称将很快结束对伊战争!30年美债收益率升至近20年来最高水平;英伟达今日盘后放榜

美股机会日报 | 重磅信号!中美敲定AI政府间对话;三大期指盘前悉数走低;谷歌开发者大会将于次日凌晨1点开幕
一图看懂 | 哔哩哔哩Q1营收74.7亿元略超预期,经调整净利同比大增62%;月活用户突破3.76亿,用户时长再创新高
华盛早报 | 特朗普“急刹车”推迟对伊攻击!暗示重回谈判桌;大摩称债市抛售潮或冲击美股涨势;韩国法院要求三星罢工不得影响产量
谷歌持仓骤增超200%!时隔六年后“买回”达美航空,伯克希尔这一次的作业能抄吗?
期权交易指南 | SOXX跟单“大空头”轻松赚500刀!英伟达财报日将有大波动?这份高胜率期权策略值得关注
美股机会日报 | 美方将在谈判期间豁免对伊石油制裁!特朗普称将“慢跑式”减持英特尔;百度AI业务收入占比首次过半
一图看懂 | AI业务收入占半壁江山!百度Q1营收超预期达320.8亿元;萝卜快跑订单量暴增120%至320万单
