
热门资讯> 正文
学习历史预测未来,国防科大新模型在多个数据集上实现未来事实预测SOTA
2021-01-24 12:37
来源:机器之心
作者:祝存超、陈牧昊、范长俊、程光权、张岩
时序知识的表征和推理是一个具有挑战性的问题。在本文中,来自国防科技大学等的研究者借鉴了自然语言生成(NLG)中的复制机制思路,并通过设计一种全新的基于时序知识图谱嵌入(TKGE)的模型来更有效地建模时序知识图谱。在多个公开时序知识图谱(TKG)基准数据集上,新模型 CyGNet 在未来事实(链接)预测任务上均实现了 SOTA 结果。
知识图谱在知识驱动的信息检索、自然语言理解和推荐系统领域有着广泛的应用。一个知识图谱只拥有静态某一时刻的事实,而目前快速增长的数据往往表现出复杂的时间动态,即时序知识图谱(TKG)。具有代表性的时序知识图谱包括全球事件、语言和音调数据库(Global Database of Events, Language, and Tone, GDELT)和综合危机预警系统(Integrated Crisis Early Warning System, ICEWS)。下图 1 展示了 ICEWS 系统的一个外交活动记录子图。
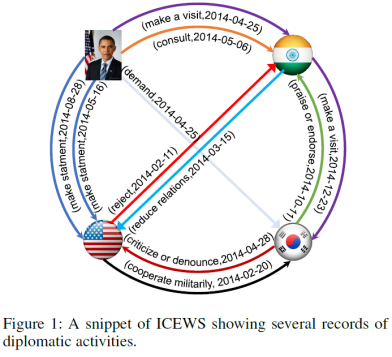
然而,现有建模时序知识图谱的方法忽视了时间事实的复杂演变(即许多事实在历史上反复出现)这个自然现象。例如:全球经济危机大约每隔 7 至 10 年就会定期发生一次;外交活动定期发生在两个建立关系的国家之间;东非动物每年 6 月都会进行大规模的迁徙。更具体地说,在整个 24 年的 ICEWS 数据集中(即 1995 年至 2019 年),超过 80% 的事件在过去已经发生过了。这些现象更进一步强调了利用已知事实预测未来事实的重要性。这也是本文的主要出发点。
所以,为了能将时间事实的复杂演变现象融入并建模时序知识图谱,来自中国国防科技大学、美国南加州大学、法国计算与先进技术学院等机构的研究者相信更有效地利用历史上发生过的已知事实能够提高时间事实推断的精度。他们决定借鉴在自然语言生成中的复制机制(copy mechanism)思路,探索一种新的框架,通过有效学习时间重复模式以更精准地建模时序知识图谱。

论文链接:https://arxiv.org/pdf/2012.08492v1.pdf
代码链接:https://github.com/CunchaoZ/CyGNet
首先,研究者通过复制机制来探究时序事实的内在现象,并提出在时序知识图谱中学习推理未来事实的时候应参考已知事实。
其次,研究者通过时间感知复制生成(copy-generation)机制创建了一个新的时序知识图谱嵌入模型CyGNet(Temporal Copy-Generation Network) 。该模型能够结合两种推理模式以根据历史词汇表或整个实体词汇表来进行推测,从而更符合上述 TKG 事实的演变模式。
最后,研究者在 ICEWS18、ICEWS14、GDELT、WIKI 和 YAGO 等 5 个公开 TKG 基准数据集上进行了广泛的实验,结果表明 CyGNet 在未来事实(链接)预测任务上优于以往 SOTA TKG 模型。
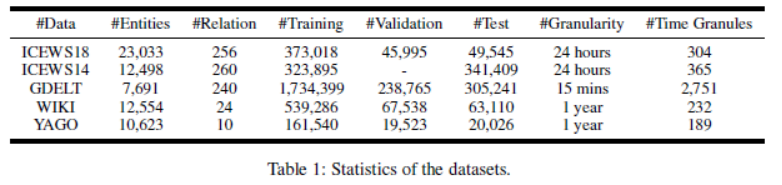
5 个数据集的统计。
方法
模型 CyGNet 举例
如下图 2 所示,研究者以预测 2018 年 NBA 冠军球队为例,总体介绍了 CyGNet 模型的预测流程。
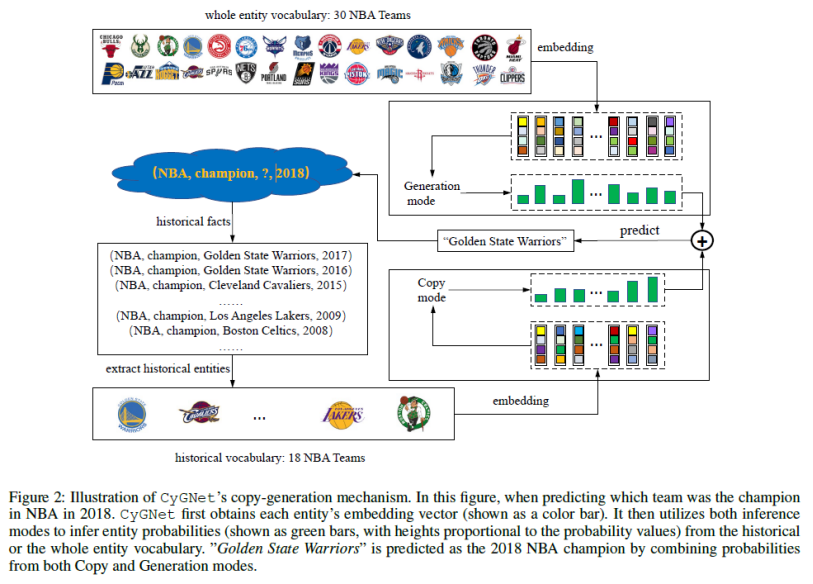
可以看到,当预测 2018 年哪支球队获得了总冠军时,我们可以从历史得知一共有 18 支 NBA 球队曾经获得过冠军。CyGNet 首先获得每个实体的嵌入向量(见彩色柱),然后使用生成模式(generation mode)得到所有 30 支 NBA 球队获得冠军的概率(见绿色条形,条形越高表示概率越大),同时使用复制模式得到所有曾经得到过冠军的 18 支球队的概率。通过合并两个模块得到的概率,CyGNet最终预测「金州勇士(Golden State Warriors)」能够获得 2018 年 NBA 冠军。
模型 CyGNet 结构
CyGNet 各部分之间的联系如下图 3 所示,主要由复制模式和生成模式两个模块组成。前者从一个具有重复事实的特定历史词汇表中选择实体,后者从整个实体词汇表选择实体。
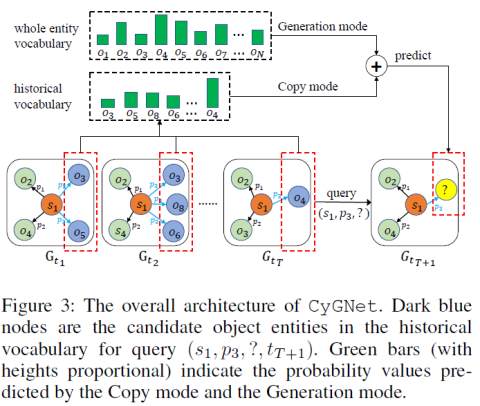
在训练过程中,研究者按照时间顺序依次训练每个时间片的知识图谱。每训练一个新的时间片的知识图谱,他们都会将该时间片之前的所有历史重复事实加入到历史词汇表,如下图 4 所示(验证和测试的时候,研究者使用整个训练集的历史信息)。
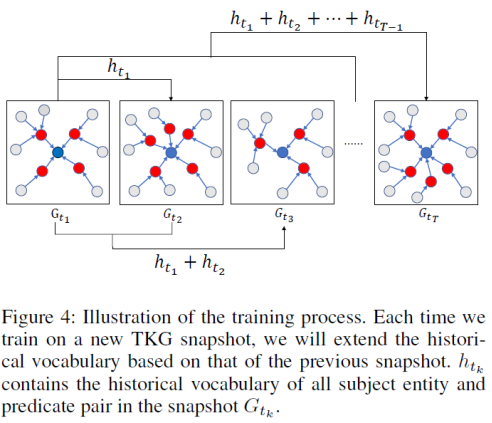
复制模式
首先得到每个时间片的历史词汇表,该词汇表由多热指示向量表示,其中在历史出现过的实体记为 1,未出现过的实体记为 0.
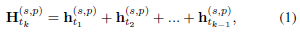
然后通过一层MLP 获得一个索引向量 v_q:

通过将
中的未出现过的实体的值设为无限小的值(如 - 10000),然后通过简单的加和,将未出现过的实体概率值降到无限小。通过一层 softmax,即可将未出现过的实体概率无限逼近与 0,得到历史出现过的所有实体的概率值 p(c):

生成模式(generationmode)
生成模式通过一层 MLP,然后再接一层 softmax,即可得到整个词汇表的概率值:
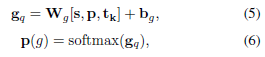
通过参数 alpha 调整复制机制和生成机制的权重,得到最终预测概率,概率最大的即 CyGNet 预测的实体:
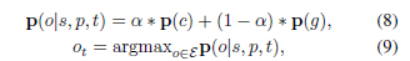
实验分析
链路预测实验结果
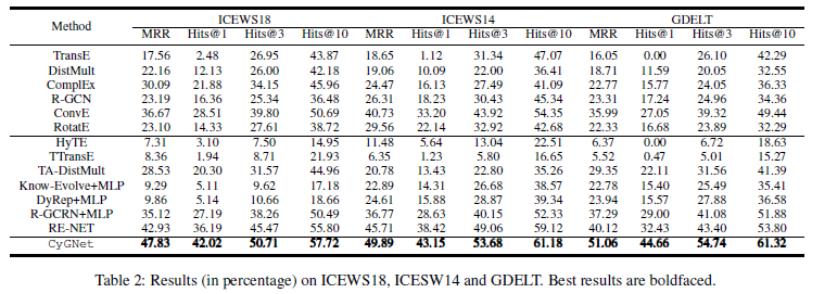
研究者在以下五个公开 TKG 基准数据集上进行了实验,如下表 2 和 3 所示。CyGNet 模型在预测未来事实的链路预测任务上的表现超过所有 baseline 模型,这说明了 CyGNet 可以通过结合复制机制和生成机制有效地建模时序知识图谱数据。
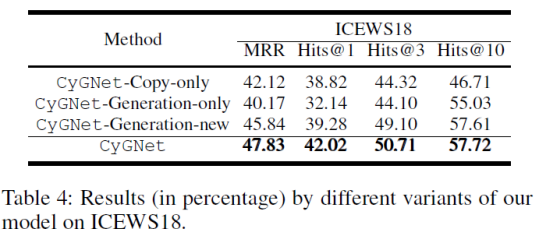
控制变量实验结果
CyGNet-Copy-only 是当 CyGNet 只使用复制模式,CyGNet-Generation-only 只使用生成模式,CyGNet-Generation-new 是 CyGNet 模型改变生成模式的词汇表,即生成模式只从全新的从未发生过的实体中选择。如下表 4 所示,每个模块都对模型产生了重要的作用。
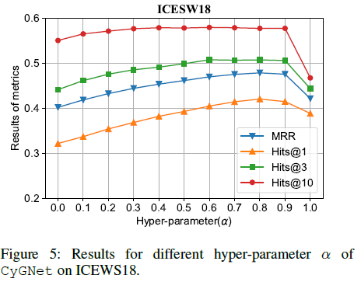
参数\ alpha 的敏感度分析
以 ICEWS18 为例,研究者分析了调整复制模式和生成模式权重的参数 alpha。实验结果证明 CyGNet 能有效的结合生成模式和复制模式。
总结
时序知识图谱预测在现实中是一个重要且有挑战性的问题。传统的方法大多侧重于通过对时序信息进行精细复杂的建模来提高预测的准确性。CyGNet 抓住时序实体经常性的重复出现这一现象,借鉴了自然语言生成领域中的「复制-生成」机制,设计了两个模块进行预测。两个模块的模型都很简单,却打败了传统的设计很复杂的模型,这充分说明了利用好时序实体重复出现特性的优势。然而对于这一特性不明显的数据,CyGNet 的表现可能未必同样出色。
AAAI 2021线上分享 | BERT模型蒸馏技术,阿里云有新方法
在阿里巴巴等机构合作、被AAAI 2021接收的论文《Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation 》中,研究者们提出了一种跨域自动数据增强方法来为数据稀缺领域进行扩充,并在多个不同的任务上显著优于最新的基准。
1月27日20:00,论文共同一作、阿里云高级算法专家邱明辉为大家详细解读此研究。
添加机器之心小助手(syncedai5),备注「AAAI」,进群一起看直播。

